自從我們的項目數據層從讀取數據庫改為讀取接口服務後,經常會出現一些類似於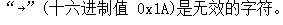 的錯誤。我們的數據結構如下所示
的錯誤。我們的數據結構如下所示

在用戶輸入的數據中常常有一些小人箭頭之類的特殊符號(由於在www.cnblogs.com/xietong下不支持這些特殊符號,所以讀者在我舉例的數據結構中看不到這些特殊符號),我曾經嘗試匹配這些特殊字符,然而未能找到與之相匹配的unicode代碼區塊,所以采用了匹配正常字符的方式來獲取合法的數據用於xml解析。可以看到我們數據中的字符包括字母數字、各種標點、空白符,據此可以寫出我們的正則表達式"(\w|\p{P}|\s)*"。在RegxTest下測試發現無法匹配“<>=”這些符號,加上這些符號後正則表達式為"(\w|\p{P}|[<>=]|\s)*",經測試,發現可以獲取到所有正常的字符,在c#中代碼如下:
string content = sb.ToString();
MatchCollection matches = Regex.Matches(content, @"(\w|\p{P}|[<>=]|\s)*");
sb = new StringBuilder();
foreach (Match m in matches)
{
sb.Append(m.Value);
}
content = sb.ToString();
在運行之後發現類似異常雖然少了很多,但還是有一部分異常,查看這些異常發現造成這些異常的原因正是存在16進制的字符,數據如下:
如果直接將0x式樣的16進制去掉,那麼這些圖片就無法找到正確地址,似乎有些粗魯。為此,我決定將相應的變量先取出來,然後在讀取出來的DataSet中重新對相應字段賦值。我的代碼如下:
1 MatchCollection imatches = null;
2 if (Regex.IsMatch(content, "0x[0-9a-fA-F]+", RegexOptions.IgnoreCase))
3 {
4 Regex regex = new Regex(@"<(?'tag'\w+?)><!\[CDATA\[(?'text'.*?0[Xx].*?)\]\]></\k'tag'>");
5 imatches = regex.Matches(content);
6 if (imatches != null)
7 {
8 content = regex.Replace(content, "<${tag}></${tag}>");
9 }
10 }
11
12 System.Xml.XmlDocument xd = new System.Xml.XmlDocument();
13 xd.LoadXml(content);
14 System.Xml.XmlNodeReader xnr = new System.Xml.XmlNodeReader(xd);
15 ds.ReadXml(xnr);
16 xnr.Close();
17 if (imatches != null && imatches.Count > 0 && ds != null && ds.Tables.Count > 0)
18 {
19 foreach (Match m in imatches)
20 {
21 foreach (DataTable table in ds.Tables)
22 {
23 if (table.Columns.Contains(m.Groups["tag"].Value))
24 {
25 table.Rows[0][m.Groups["tag"].Value] = m.Groups["text"].Value;
26 break;
27 }
28 }
29 }
30 }
在上面的代碼中用到了正則的文本替換及分租,如果有不理解的地方可以在http://edu.51cto.com/course/course_id-4664.html中學習一下基本的C#正則表達式知識。
上面的代碼經測試可以正常運行,但放到那裡呢,雖然在try-catch拋出異常,在異常中處理的話要耗費幾百個時鐘周期,但鑒於問題數據只是一小部分,並且上面的正則表達式的效率並不太高,所以我將上面的代碼放在了catch語句塊中。