len()The function counts the number of characters in a string
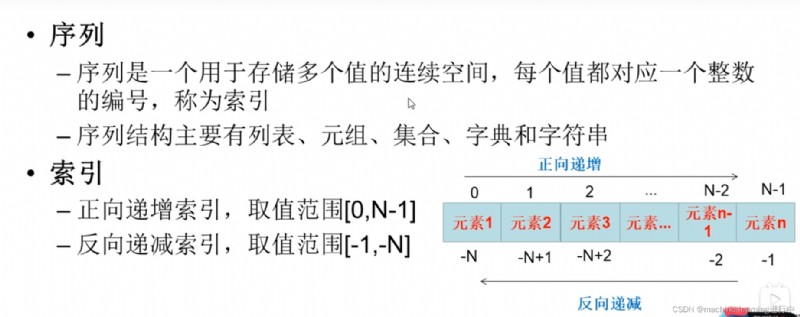
Note the forward and reverse index numbers

The various parameters of the slice:start,end,step
Pay attention to the meaning and default value of each parameter
s="helloworld"
s1=s[0:5:1] #Specify the start and end positions and step size
print(s1) #輸出為hello
序列相加:The sequence types are required to be the same(The type of sequence has a list、元組、集合、字典和字符串),元素的 Type can be character or integer.Understand sequence types and the types of elements in sequences
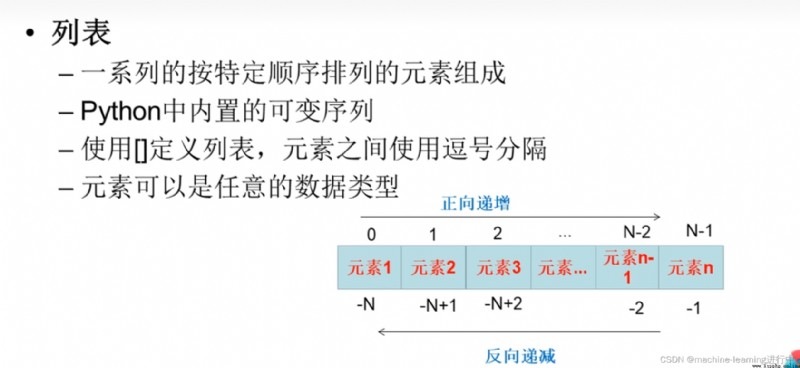

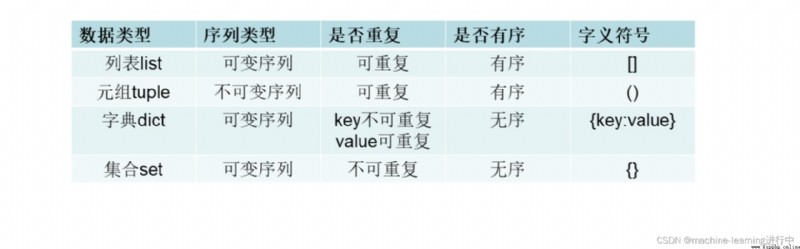
Lists are variable-length sequences,because it can increase、刪除元素
#列表的創建
#直接使用[]創建
lst=["hello","world",99.8,] #變量名為lst不是list,因為list是內置函數
#使用內置函數list()創建
lst2=list("hello") #結果為["h","e","l","l","0"]
lst3=list(range(1,10,2)) #從1開始,到10結束(不包括10)and the step size is 2,輸出結果為[1,3,5,7,9]
#actions in the list
print(lst2+lst3) #結果為["h","e","l","l","0",1,3,5,7,9]
print(lst2*3) #結果為["h","e","l","l","0","h","e","l","l","0","h","e","l","l","0"]
print(len(lst2))
print(max(lst3)) #The same applies to sequence operations
print(min(lst3))
#列表的刪除
del lst #刪除列表,then the list does not exist
del lst2
del lst3

#使用for循環遍歷列表元素
lst=["hello","world","python","php"]
for item in lst:
print(item)
#使用for循環,range()函數,len()函數,Iterate over elements by index
for i in range(len(lst)):
print(i,"-->",lst[i])
#使用for循環,enumerate()函數進行遍歷
for index,item in enumerate(lst): #默認index序號從0開始
print(index,item)
for index,item in enumerate(lst,1): #修改index序號從1開始
print(index,item)
lst=["hello","python","php"]
print("原列表:",lst,id(lst)) #id()The function represents that address,The output is the original list:["hello","python","php"]
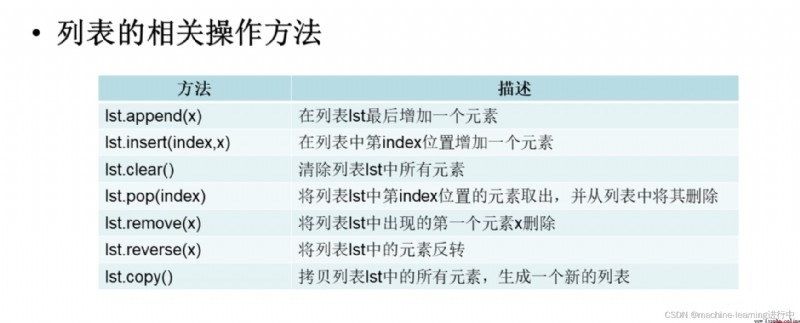
#使用insert(index,x)在指定位置插入元素
lst.insert(1,100) #在位置1處插入元素100(默認位置從0開始)
#刪除元素
lst.remove("hello")
#使用pop(index),Removes elements by index,Remove the element first,再將元素刪除
lst.pop(1) #The statement is output directly in the window100
#清空列表所有元素
lst.clear()
#Reverses the positions of elements in a list
lst.reverse()
#列表的拷貝,and produce a new list
new_lst=lst.copy() #The memory addresses of the two lists are not the same
#列表元素的修改
lst[1]="mysql" 
sort方法:reverse=True,則降序排序;False是升序排序,The default is to sort pairs in ascending order
sorted函數:是內置函數
注意sort()是方法,而sorted()是內置函數
The sorting effect for Chinese is not very good,But English can be sorted,按照首字母的unicodeCode values are sorted(ASCII碼是unicodepart of the code)
#用sort()方法進行排序
lst=[5,15,46,3,59,62]
lst.sort() #默認是升序排序
lst.sort(reverse=True) #降序排序
#Sort English
lst2=["banana","apple","Cat","Orange"]
lst2.sort() #默認升序排序,Uppercase first, then lowercase(按照首字母的unicode碼排序)
lst2.sort(reverse=True) #降序排序,Lowercase first before uppercase
#忽略大小寫進行排序
lst2.sort(key=str.lower) #Default ascending order and partial case,用到參數key(is the key for the comparison sort)#用sorted()內置函數進行排序
lst=[5,15,23,86,3,87]
asc_lst=sorted(lst) #默認是升序排序
print(lst)
print(asc_lst) #輸出會發現lst未改變,asc_lstSorting changed
#sorted()函數的參數和sort()方法相同,can take the same form

expression是表達式的意思,That is, the preceding can be any expression
#列表生成式
#生成整數列表
lst=[i for i in range(1,11)]
lst1=[i*i for i in range(1,11)] #is preceded by an expression
#產生10個隨機數列表
import random #To generate random numbers to importrandom模塊
lst3=[random.randint for _ in range(10)] #Because the loop variable was not used before,So replace it with an underscore and the loop indicates the number of loops
#從列表中選擇符合條件的元素組成新的列表
lst4=[i for i in range(10) if i%==0] #產生0~9之間的偶數列表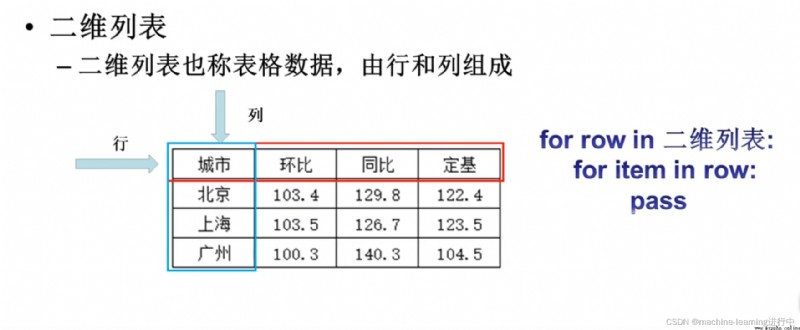
#創建二維列表
lst=[["城市","環比","同比"],
["北京",102,103],
["上海",104,504],
["深圳",103,205]
]
#Traverse a two-digit list
for row in lst
for item in row
print(item,end="\t")
print()
#List comprehensions create lists with four rows and five columns
lst2=[[j for j in range(5)]for i in range(4)]
print(lst2) #輸出是[[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]
#Conditional filtering can also be added by imitating the one-dimensional list comprehension
元組是不可變序列
The data type in the tuple can be a string、整型、也可以是列表,元組
#直接使用()創建元組
t=("hello","python",[0,1,2],10)
print(t) #輸出是("hello","python",[0,1,2],10),輸出中帶有()
#使用內置函數tuple()創建元組
t=tuple("hello")
print(t) #輸出為("h","e","l","l","o")
t=tuple([1,2,3])
print(t) #輸出是(1,2,3)
t=tuple(range(1,5))
print(t) #輸出是(1,2,3,4)
#The related operations on tuples are the same as those on sequences
#若元組中只有一個元素,should be enclosed in parentheses“,”
z=(10)
print(type(z)) #輸出<class:int>
m=(10,)
print(type(m)) #輸出<class:tuple>
#刪除元組
del m
print(m) #報錯:nameerror:m is not defined
t=("python","php","hello")
print(t[0]) #輸出為python,根據索引訪問
t1=t[0:3:1]
print(t1) #輸出是("python","php","hello"),切片操作
#元組的遍歷
#1,直接使用for循環遍歷
t=("python","php","hello")
for item in t:
print(item)
#2,for循環+range()+len()組合遍歷
t=("python","php","hello")
for i in range(0,len(t)):
print(t[i])
#3,enumerate()函數遍歷
for index,item in enumerate(t):
print(index,item) #使用enumerate()函數時index默認從0開始
t=(i for i in range(1,4))
print(t) #結果是<generator object <genexpr>>生成器對象
#1,Generator objects can be converted to tuple type output
t=tuple(t)
print(t) #輸出(1,2,3)
#2,Generator objects can be used directlyfor循環遍歷,No need to convert to tuple type
for item in t:
print(item)
#3,Builder object methods__next__()方法遍歷
print(t.__next__()) #拿到第一個元素
print(t.__next__()) #Get the second element
print(t.__next__()) #Get the third element
t=tuple(t)
print(t) #The output will find that the element is empty
#After generator traversal,If you want to re-traverse, you must recreate a generator object,Because the original generator object does not exist after the traversal注意:After generator traversal,If you want to re-traverse, you must recreate a generator object,Because the original generator object does not exist after the traversal
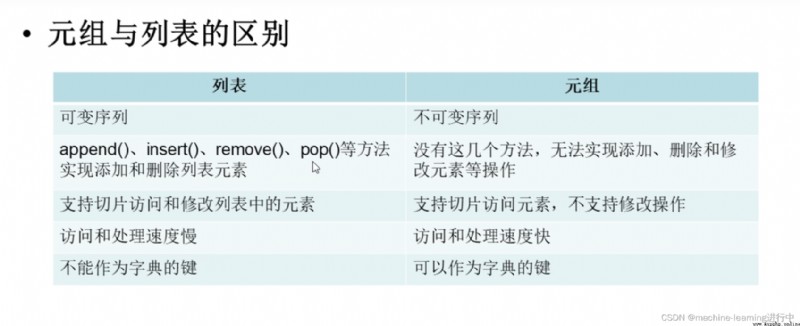
1,Mutable sequence when list,Add and delete operations can be performed;元組是不可變序列.
2,Lists are mutable sequences and cannot be used as dictionary keys;Tuples are immutable sequences that can be used as dictionary keys
3,When only the element needs to be accessed and not modified,用元組


字典沒有索引,Accessible only by key
The keys in the dictionary must be immutable sequences,值可以是任意類型
Dictionaries are mutable sequences,可以添加和刪除元素

字典的刪除:del 字典名
#1,直接使用{}創建
d={10:"car",20:"dog",30:"pet"}
#2,映射函數zip()函數結合dict()使用
lst1=[10,20,30,40]
lst2=["cat","dog","car","zoo"]
ziph=zip(lst1,lst2) #The result of the map function is zip對象
#zip()The function combines the elements at corresponding positions in the two lists as a tuple,並產生zip對象
#print(ziph) #輸出是<zip object>
#print(list(ziph)) #zipObjects need to be converted to lists or tuples for output
d=dict(ziph)
print(d) #輸出是{10:"cat",20:"dog",30:"car",40:"zoo"}
#3,使用dict()and create a dictionary with parameters
d=dict(cat=10,dog=20,car=30) #If written in parentheses10=catThen an error is reported because the variable cannot be a number
print(d) #輸出是{"cat":10,"dog":20,"car":30}
t=(10,20,30)
m={t:10} #Keys must be immutable sequences
print(m) #輸出是{(10,20,30):10}
n=[10,20,30]
m={n:10}
print(m) #報錯typeError:unhashable type:"list"
#刪除字典
del m #It doesn't exist after deletion
del n
Iterate over dictionary elements:方法items()指的是鍵值對
d={"hello":10,"world":20,"php":30}
#訪問字典元素
#1,使用[key]
print(d["hello"])
#2,使用d.get(key)
print(d.get("hello"))
#[key]和d.get(key)的區別,The difference occurs if the key does not exist
#print(d["java"]) 直接報錯:KeyError鍵錯誤
print(d.get("java")) #不會報錯,輸出None,d.get("java")默認值None
print(d.get("java","不存在")) #The output default value does not exist
#字典的遍歷
for item in d.items():
print(item) #The output is in tuple form,即("hello",10)形式,因為items是鍵值對形式
for key,value in d.items():
print(key,value) #輸出對應的值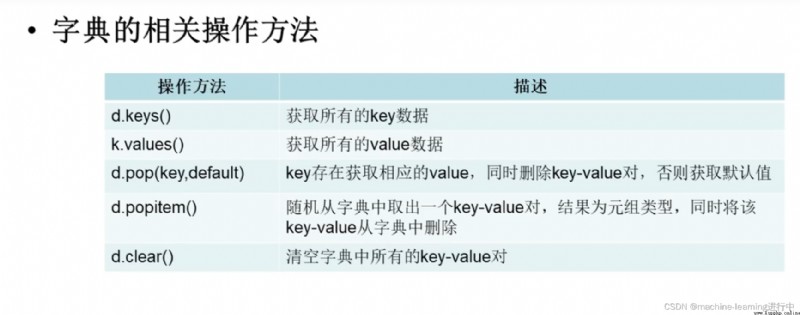
d={1001:"李梅",1002:"王華",1003:"張鋒"}
#向字典中添加數據
d[1004]="張麗" #直接使用d[key]=value賦值運算,添加數據
#獲取字典中所有的key
key=d.keys() #d.keys()結果是dict_keys,pythonAn internal data type in ,Dedicated to representing dictionarieskey
#If you want a better display of the data,可用list()或tuple()Convert to a list or tuple
print(list(key))
print(tuple(key))
#獲取字典中所有的value
value=d.values() #d.values()結果是dict_values
print(list(value))
print(tuple(value))
#使用pop()方法
print(d.pop(1008,"不存在")) #若鍵不存在,輸出默認值“不存在”
#清除字典
d.clear()
print(bool(d)) #輸出False
#Use the specified range of numbers as keyskey
import random
d={item:random.randint(1,100) for item in range(4)}
print(d) #輸出{0:39,1:25,2:45,3:56}
#使用映射函數zip()as a generating expression
lst1=[1001,1002,1003]
lst2=["劉偉","張強","李華"]
d={key:value for key,value in zip(lst1,lst2)}
print(d)


集合中的元素不能重復,If repeated, the weight will drop automatically,The weight reduction of strings can be achieved
本博客Only mutable collections are describedset
#The first method to create a collection
s={10,20,30,40]
print(s) #輸出為{40,10,20,30},因為集合是無序的
s={[10,20],[30,40]}
print(s) #報錯TypeError,因為列表是可變的
s={} #創建的是空字典
s=set() #Created an empty collection
#The second creates a collection,set(可迭代對象),Iterable objects just workforThe type of loop to traverse
s1=set("hello")
s2=set([10,20,30])
s3=set(range(1,10))
print(s1) #輸出{"h","l","o","e"},集合中的元素不能重復,Deduplication of strings can be achieved
print(s2)
print(s3)
del s1 #刪除s3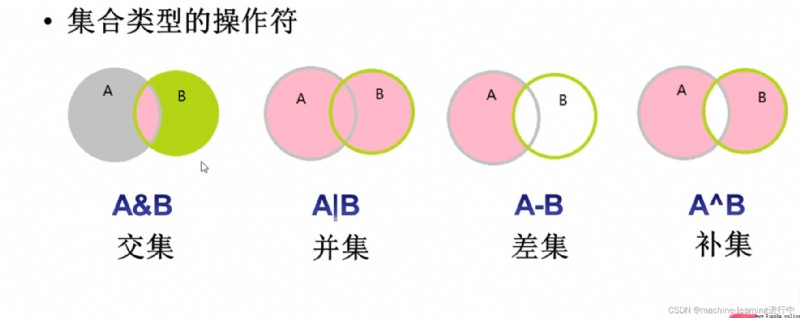
a={10,20,30,60}
b={20,30,40,80}
print(a&b) #輸出是{20,30},Still a collection
print(a|b) #The output is still a collection
print(a-b)
print(a^b) #補集,即去掉a和bAll elements remaining after the repeated elements in 
s={10,20,30}
#添加元素
s.add(100) #結果是{100,10,20,30}
#刪除元素
s.remove(20)
#清除集合中所有元素
s.clear()
#遍歷集合元素
for i in s:
print(i)
#使用ennumerate()函數遍歷
for index,value in ennumerate(s,1): #index是序號,不是索引
print(index,value)
#集合生成式
s={i for i in range(1,10)}
m={i for i in range(1,10) if i%2==0}
#千年蟲
lst=[88,89,90,98,00,99] #Two integers representing the employee's year of birth
#遍歷列表
for index in range(len(lst)):
if str(lst[index])!="0":
lst[index]="19"+str( lst[index])#Assignment after splicing
else:
lst[index]="200"+str( lst[index])
#使用enumerate()函數遍歷列表
for index,value in enumerate(lst):
if value!=0:
lst[index]="19"+str(value)
else:
lst[index]="200"+str(value)#Simulate the Jingdong shopping process
#創建列表,Used to store the commodity information in the warehouse
lst=[]
for i in range(1,6):
goods=input("Enter the item number and item name,Enter one item at a time")
lst.append(goods)
#Output all product information
for item in lst:
print(item)
#創建空列表,Used to store items in the shopping cart
cart=[]
while True:
flag=False
num=input("請輸入要購買的商品編號")
#遍歷商品列表,Check whether the purchased item exists
for item in lst:
if num==item[0:4]
cart.append(item)
print("商品已添加到購物車")
break
if flag==False and num!="q":
print("該商品不存在")
if num="q":
break
print("The item selected in the shopping cart is ")
#反向
cart.reverse()
for item in cart:
print(item)
#模擬12306購票流程,字典的應用
#創建字典,Used to store ticket information,trips dokey,Do with other informationvalue
dict_ticket={"G1569":["北京南-天津北","18:06","18:39"],"G1567":["北京南-天津南","18:15","18:50"],"G1845":["北京南-天津西","18:13","18:36"],"G1902":["北京南-Tianjin East","18:23","18:56"]}
#遍歷字典元素
for key in dict_ticket.keys():
print(key,end="")
#Traverse trip details
for item in dict_ticket.get(key):#根據key獲取值,dict_ticket[key]
print(item,end="")
print()
#Enter the user's ticketed train number
train_no=input("Enter the number of trains purchased by the user")
#根據鍵獲取值
info=dict_ticket.get(train_no,"The train does not exist")#get()method if there is no correspondingkey,The default parameters are output"The train does not exist"
if info!="The train does not exist":
person=input("Enter the rider")
#獲取車次詳細信息
s=info[0]+" "+"開"+info[1]
print("已購買"+train_no + person + s + "Exchange for a ticket【鐵路12306】")
else:
print("The train does not exist")
#模擬手機通訊錄,集合的應用
#創建空集合
phones=set()
for i in range(5):
info=input("請輸入第"+str(i)+"A human friend")
#添加到集合中
phones.add(info)
for item in phones:
print(item)