# -*- coding:utf-8 -*-
"""
作者:wyt
日期:2022年04月21日
"""
import threading
import requests
import time
urls = [
f'https://www.cnblogs.com/#p{page}' # address to be crawled
for page in range(1, 10) # 爬取1-10頁
]
def craw(url):
r = requests.get(url)
num = len(r.text) # Crawling the number of characters on the current page of the blog garden
return num # Returns the number of characters on the current page
def sigle(): # 單線程
res = []
for i in urls:
res.append(craw(i))
return res
class MyThread(threading.Thread): # 重寫threading.Thread類,Add a function to get the return value
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url # 初始化傳入的url
def run(self): # Newly added functions,該函數目的:
self.result = craw(self.url) # ①.調craw(arg)函數,and initializedurl以參數傳遞——實現爬蟲功能
# ②.並獲取craw(arg)The return value of the function is stored in the defined value of this classresult中
def get_result(self): #Newly added functions,該函數目的:返回run()函數得到的result
return self.result
def multi_thread():
print("start")
threads = [] # 定義一個線程組
for url in urls:
threads.append( # After adding the assignment to the thread groupMyThread類
MyThread(url) # 將每一個url傳到重寫的MyThread類中
)
for thread in threads: # 每個線程組start
thread.start()
for thread in threads: # 每個線程組join
thread.join()
list = []
for thread in threads:
list.append(thread.get_result()) # Each thread returns the result(result)加入列表中
print("end")
return list # Returns a list of results returned by multiple threads
if __name__ == '__main__':
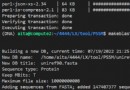
start_time = time.time()
result_multi = multi_thread()
print(result_multi) # 輸出返回值-列表
# result_sig = sigle()
# print(result_sig)
end_time = time.time()
print('用時:', end_time - start_time)
單線程:
多線程:
加速效果明顯.
import threading
import requests
import time
urls = [
f'https://www.cnblogs.com/#p{page}' # address to be crawled
for page in range(1, 10) # 爬取1-10頁
]
def craw(url):
r = requests.get(url)
num = len(r.text) # Crawling the number of characters on the current page of the blog garden
print(num)
def sigle(): # 單線程
res = []
for i in urls:
res.append(craw(i))
return res
if __name__ == '__main__':
start_time = time.time()
result_sig = sigle()
print(result_sig)
end_time = time.time()
print('用時:', end_time - start_time)
import time
from threading import Thread
def foo(number):
time.sleep(1)
return number
class MyThread(Thread):
def __init__(self, number):
Thread.__init__(self)
self.number = number
def run(self):
self.result = foo(self.number)
def get_result(self):
return self.result
if __name__ == '__main__':
thd1 = MyThread(3)
thd2 = MyThread(5)
thd1.start()
thd2.start()
thd1.join()
thd2.join()
print(thd1.get_result())
print(thd2.get_result())
返回:
3
5
Multithreaded entry
threading.Thread(target=craw,args=(url,)) # 注意args=(url,),元組
多線程傳參
需要重寫一下threading.Thread類,Add a function that receives the return value.
A previously published code for crawling subdomains was rewritten using this multithreading technique with return values,The original code is here:https://blog.csdn.net/qq_45859826/article/details/124030119
import threading
import requests
from bs4 import BeautifulSoup
from static.plugs.headers import get_ua
#https://cn.bing.com/search?q=site%3Abaidu.com&go=Search&qs=ds&first=20&FORM=PERE
def search_1(url):
Subdomain = []
html = requests.get(url, stream=True, headers=get_ua())
soup = BeautifulSoup(html.content, 'html.parser')
job_bt = soup.findAll('h2')
for i in job_bt:
link = i.a.get('href')
# print(link)
if link not in Subdomain:
Subdomain.append(link)
return Subdomain
class MyThread(threading.Thread):
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url
def run(self):
self.result = search_1(self.url)
def get_result(self):
return self.result
def Bing_multi_thread(site):
print("start")
threads = []
for i in range(1, 30):
url = "https://cn.bing.com/search?q=site%3A" + site + "&go=Search&qs=ds&first=" + str(
(int(i) - 1) * 10) + "&FORM=PERE"
threads.append(
MyThread(url)
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
res_list = []
for thread in threads:
res_list.extend(thread.get_result())
res_list = list(set(res_list)) #列表去重
number = 1
for i in res_list:
number += 1
number_list = list(range(1, number + 1))
dict_res = dict(zip(number_list, res_list))
print("end")
return dict_res
if __name__ == '__main__':
print(Bing_multi_thread("qq.com"))
返回:
{
1:'https://transmart.qq.com/index',
2:'https://wpa.qq.com/msgrd?v=3&uin=448388692&site=qq&menu=yes',
3:'https://en.exmail.qq.com/',
4:'https://jiazhang.qq.com/wap/com/v1/dist/unbind_login_qq.shtml?source=h5_wx',
5:'http://imgcache.qq.com/',
6:'https://new.qq.com/rain/a/20220109A040B600',
7:'http://cp.music.qq.com/index.html',
8:'http://s.syzs.qq.com/',
9:'https://new.qq.com/rain/a/20220321A0CF1X00',
10:'https://join.qq.com/about.html',
11:'https://live.qq.com/10016675',
12:'http://uni.mp.qq.com/',
13:'https://new.qq.com/omn/TWF20220/TWF2022042400147500.html',
14:'https://wj.qq.com/?from=exur#!',
15:'https://wj.qq.com/answer_group.html',
16:'https://view.inews.qq.com/a/20220330A00HTS00',
17:'https://browser.qq.com/mac/en/index.html',
18:'https://windows.weixin.qq.com/?lang=en_US',
19:'https://cc.v.qq.com/upload',
20:'https://xiaowei.weixin.qq.com/skill',
21:'http://wpa.qq.com/msgrd?v=3&uin=286771835&site=qq&menu=yes',
22:'http://huifu.qq.com/',
23:'https://uni.weixiao.qq.com/',
24:'http://join.qq.com/',
25:'https://cqtx.qq.com/',
26:'http://id.qq.com/',
27:'http://m.qq.com/',
28:'https://jq.qq.com/?_wv=1027&k=pevCjRtJ',
29:'https://v.qq.com/x/page/z0678c3ys6i.html',
30:'https://live.qq.com/10018921',
31:'https://m.campus.qq.com/manage/manage.html',
32:'https://101.qq.com/',
33:'https://new.qq.com/rain/a/20211012A0A3L000',
34:'https://live.qq.com/10021593',
35:'https://pc.weixin.qq.com/?t=win_weixin&lang=en',
36:'https://sports.qq.com/lottery/09fucai/cqssc.htm'
}
Very, very, very, very much faster,It's also cool to blast subdomains this way.沒有多線程,There may be several features missing from my project:Because some of the programs I wrote before were cut off by me because the execution time was too long.這個功能還是很實用的.
B站python-多線程教程:https://www.bilibili.com/video/BV1bK411A7tV
2022年4月28日於家中,加油!
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在.深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小.自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前.因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔.添加下方名片,即可獲取全套學習資料哦