1、可配置性:Camelot 通過可調整的設置讓您控制表格提取過程。
2、指標:您可以根據准確性和空白等指標丟棄壞表,而無需手動查看每個表。
3、輸出:每個表都被提取到一個pandas DataFrame中,它可以無縫集成到ETL 和數據分析工作流中。您還可以將表格導出為多種格式,包括 CSV、JSON、Excel、HTML、Markdown 和 Sqlite。
特定於操作系統的說明
#Ubuntu
$ apt install ghostscript python3-tk
#MacOS
$ brew install ghostscript tcl-tk
#Windows
對於 Ghostscript,您可以在他們的下載頁面獲取安裝程序。對於 Tkinter,您可以從 ActiveState下載ActiveTcl 社區版。
打開 Python REPL 並運行以下命令:
#對於 Ubuntu/MacOS:
from ctypes.util import find_library
find_library("gs")
"libgs.so.9"
#對於 Windows:
import ctypes
from ctypes.util import find_library
find_library("".join(("gsdll", str(ctypes.sizeof(ctypes.c_voidp) * 8), ".dll")))
<name-of-ghostscript-library-on-windows>
檢查:函數的輸出find_library不應為空。
如果輸出為空,則可能是 Ghostscript 庫不可用 // 變量之一,LD_LIBRARY_PATH具體DYLD_LIBRARY_PATH取決於PATH您的操作系統。在這種情況下,您可能必須修改其中一個路徑變量。
1、pip
要使用 PyPI 從 PyPI 安裝 Camelot pip,請包括cv如下所示的額外要求:
$ pip install "camelot-py[base]"
2、conda
conda是Anaconda發行版的包管理器和環境管理系統。它可用於從conda-forge頻道安裝 Camelot:
conda install -c conda-forge camelot-py
3、從源代碼
安裝依賴項後,您可以通過以下方式從源代碼安裝 Camelot:
a. 克隆 GitHub 存儲庫。
$ git clone https://www.github.com/camelot-dev/camelot
b. 然後再次簡單地使用 pip。
$ cd camelot
$ pip install ".[base]"
閱讀 PDF 以使用 Camelot 提取表格非常簡單。
首先導入 Camelot 模塊:
import camelot
點擊這裡獲取PDF文件
tables = camelot.read_pdf('foo.pdf')
tables
結果是
<TableList n=1>
現在,我們有一個TableList名為 的對象tables,它是一個Table對象列表。我們可以從這個對象中得到我們需要的一切。我們可以使用每個表的索引來訪問它。從上面的代碼片段中,我們可以看到該tables對象只有一個表,因為n=1. 讓我們使用索引訪問表0並查看它的shape.
tables[0]
<Table shape=(7, 7)>
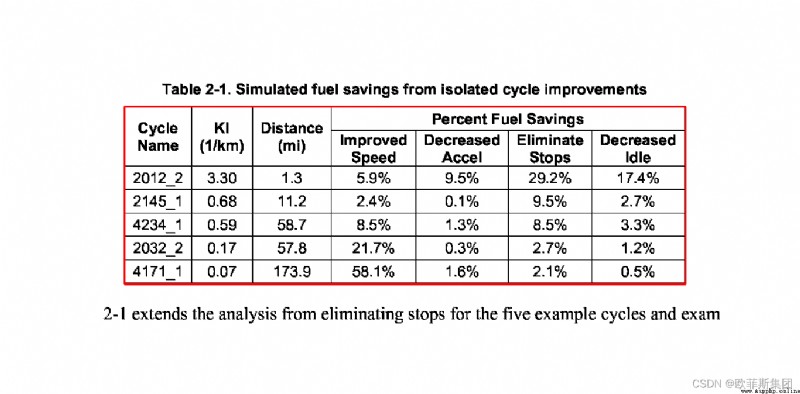
讓我們打印解析報告。
print tables[0].parsing_report
結果是
{
'accuracy': 99.02,
'whitespace': 12.24,
'order': 1,
'page': 1
}
准確性是一流的,並且空格較少,這意味著該表很可能被正確提取。table您可以使用對象的df屬性以 pandas DataFrame 的形式訪問該表。
tables[0].df
您現在可以使用其to_csv()方法將表導出為 CSV 文件。to_json()或者,您可以使用或方法將表格分別導出為 JSON、Excel、HTML 文件或 sqlite 數據庫。to_excel() to_html() to_markdown()to_sqlite()
tables[0].to_csv('foo.csv')
這會將表格導出為指定路徑的 CSV 文件。在這種情況下,它foo.csv位於當前目錄中。
tables您還可以使用對象的export()方法一次導出所有表。
tables.export('foo.csv', f='csv')
指定頁碼
默認情況下,Camelot 僅使用 PDF 的第一頁來提取表格。要指定多個頁面,您可以使用pages關鍵字參數:
camelot.read_pdf('your.pdf', pages='1,2,3')
關鍵字參數接受以逗號分隔的pages頁碼字符串形式的頁面。您還可以指定頁面范圍 - 例如,pages=1,4-10,20-30或pages=1,4-10,20-end。
要從加密的 PDF 文件中提取表格,您必須在調用時提供密碼read_pdf()。
tables = camelot.read_pdf('foo.pdf', password='******')
tables
目前,Camelot 僅支持使用 ASCII 密碼和算法代碼 1 或 2加密的 PDF 。如果無法讀取 PDF,則會引發異常。這可能是由於未提供密碼、密碼不正確或加密算法不受支持。
將來可能會添加進一步的加密支持,但與此同時,如果您的 PDF 文件使用不受支持的加密算法,建議您在調用read_pdf(). 這可以通過QPDF等第三方工具成功實現。
qpdf --password=<PASSWORD> --decrypt input.pdf output.pdf
資料來源PDF
在這裡插入圖片描述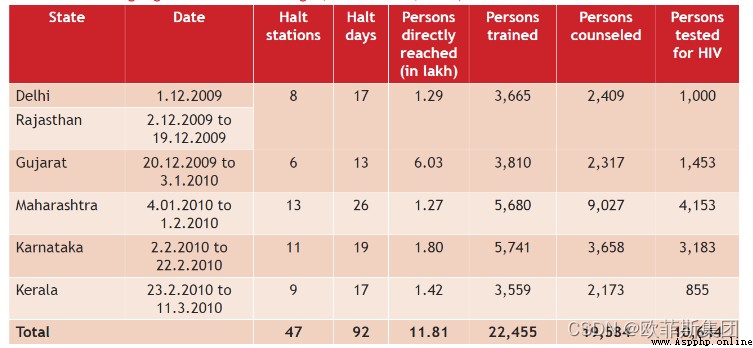
處理背景線
要處理背景線,您可以通過process_background=True.
tables = camelot.read_pdf('background_lines.pdf', process_background=True)
tables[1].df
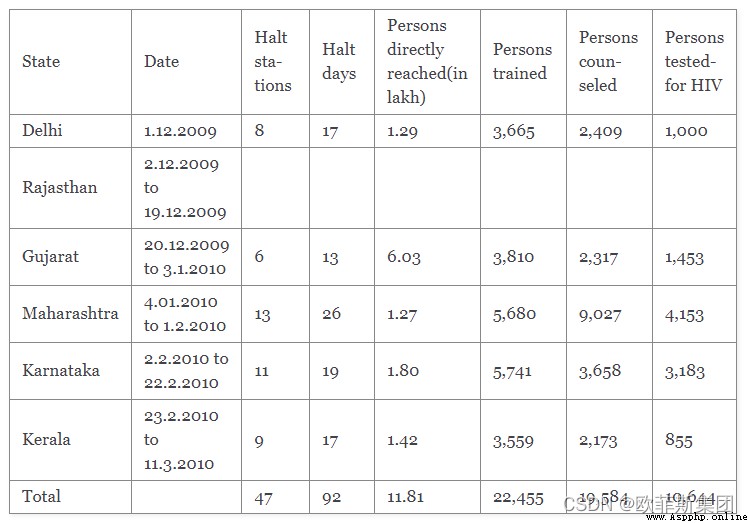
可視化調試
您可以使用該plot()方法生成在處理 PDF 頁面時檢測到的各種元素的matplotlib圖。這可以通過調整不同的配置參數來幫助您選擇表格區域、列分隔符和調試錯誤的表格輸出。
kind您可以使用關鍵字參數指定要繪制的元素類型。生成的圖可以通過傳遞filename關鍵字參數保存到文件中。支持以下繪圖類型:
文本
text
讓我們繪制表格 PDF 頁面上的所有文本。
camelot.plot(tables[0], kind='text').show()
網格
讓我們繪制表格(看看它是否被正確檢測到)。這種繪圖類型以及等高線、直線和關節對於調試和改進提取輸出很有用,以防表格未被正確檢測到。(稍後會詳細介紹。)
camelot.plot(tables[0], kind='grid').show()
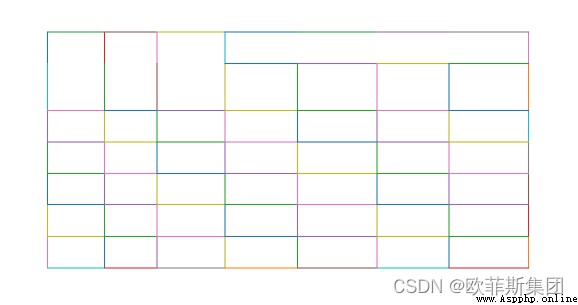
輪廓
contour
現在,讓我們繪制表格 PDF 頁面上存在的所有表格邊界。
camelot.plot(tables[0], kind='contour').show()
線
line
可以繪制表格 PDF 頁面上的所有線段。
camelot.plot(tables[0], kind='line').show()
聯合的
joint
最後,讓我們繪制表格 PDF 頁面上存在的所有線交點。
camelot.plot(tables[0], kind='joint').show()
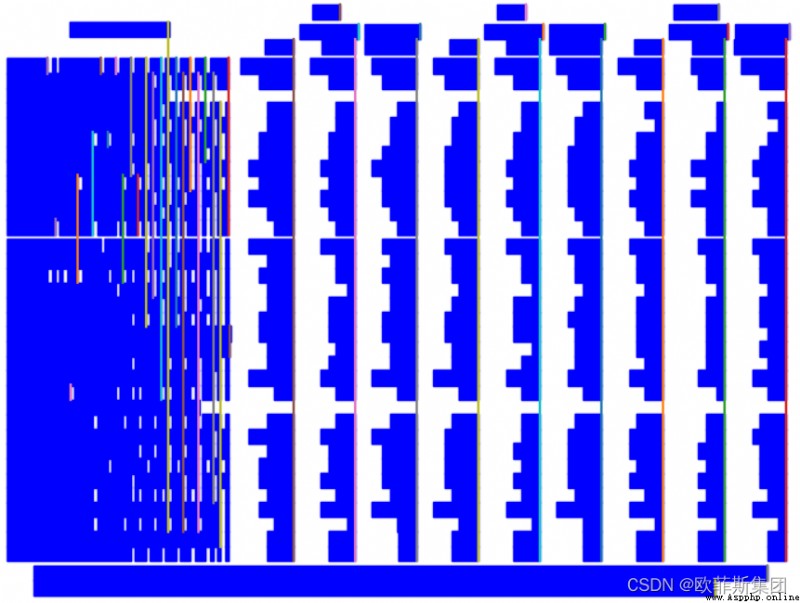
文本邊緣
textedge
您還可以通過指定kind=‘textedge’. 要了解更多關於“textedge”是什麼的信息,您可以查看Anssi Nurminen 碩士論文的第 20、35和 40 頁。
camelot.plot(tables[0], kind='textedge').show()
指定表格區域
在這些情況下,指定准確的表邊界會很有用。您可以在此頁面上繪制文本並注意表格的左上角和右下角坐標。
您希望 Camelot 分析的表格區域可以作為逗號分隔的字符串列表傳遞給read_pdf(),使用table_areas關鍵字參數。
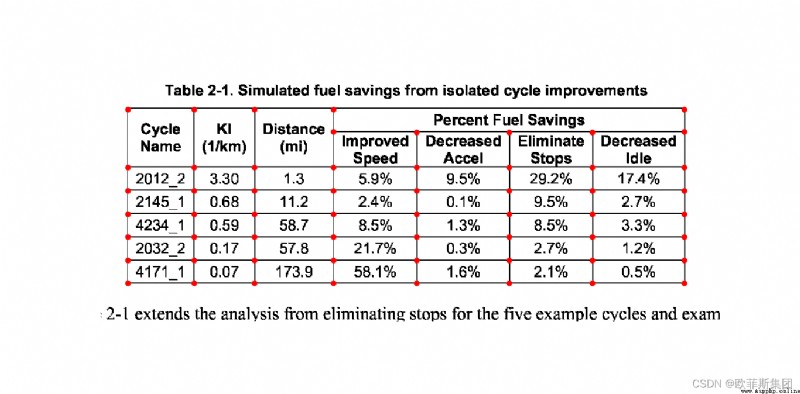
tables = camelot.read_pdf('table_areas.pdf', flavor='stream', table_areas=['316,499,566,337'])
tables[0].df
指定列分隔符
指定列分隔符
在這種情況下,文本彼此非常接近,Camelot 可能會錯誤地猜測列分隔符的坐標。要更正此問題,您可以通過在頁面上繪制文本來明確指定每個列分隔符的x坐標。read_pdf()您可以使用columns關鍵字參數將列分隔符作為逗號分隔的字符串列表傳遞給。如果您傳遞了單列分隔符字符串列表,並且未指定表格區域,則分隔符將應用於整個頁面。當指定了表格區域列表並且您還需要指定列分隔符時,兩個列表的長度應該相等。每個表格區域將使用它們的索引映射到每個列分隔符的字符串。
例如,如果您指定了兩個表格區域,並且只想為第一個表格指定列分隔符,您可以像這樣在列分隔符列表中為第二個表格傳遞一個空字符串,.table_areas=[‘12,54,43,23’, ‘20,67,55,33’]columns=[‘10,120,200,400’, ‘’]
繪制此PDF上存在的文本所得到的x坐標,然後將表格拿出來!
tables = camelot.read_pdf('column_separators.pdf', flavor='stream', columns=['72,95,209,327,442,529,566,606,683'])
tables[0].df

下期為大家分享介紹Camelot更多高級用法