Crawlers are often used in the data collection stage of graduation design , Many students' requirements and reactions , Let students grow up with an article on reptiles .
This article will describe and analyze how crawlers are used , And give an example .
The so-called crawler is to write code to crawl the data you want from the web page , The quality of the code determines whether you can accurately crawl the data you want , Whether the data can be analyzed intuitively and correctly .
Python Undoubtedly, it is the most suitable language for reptiles .Python It's very simple , But to really use it well, you need to learn a lot of third-party library plug-ins . such as matplotlib library , Is an imitation matalab A powerful drawing library , With it, you can draw a pie chart of the data you climb down 、 Broken line diagram 、 Scatter plot and so on , Even 3D Figure to show intuitively .
Python Third party libraries can be installed manually , But it is easier to enter a line of code directly on the command line to automatically search resources and install . And very intelligent , You can identify the type of your computer and find the most suitable version .
Pip install + The third-party library you need
Or is it easy install + The third-party library you need
Here we suggest you use pip install , because pip You can install or uninstall , The other method can only install . If you want to use a new version of the third-party library , Use pip The advantages of will appear .
🧿 Topic selection guidance , Project sharing :
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
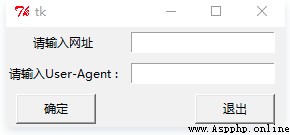
def web():
root = Tk()
Label(root,text=' Please enter the web address ').grid(row=0,column=0) # Yes Label The contents are arranged in tabular format
Label(root,text=' Please enter User-Agent :').grid(row=1,column=0)
v1=StringVar() # Set a variable
v2=StringVar()
e1 = Entry(root,textvariable=v1) # Used to store Input content
e2 = Entry(root,textvariable=v2)
e1.grid(row=0,column=1,padx=10,pady=5) # Perform tabular layout
e2.grid (row=1,column=1,padx=10,pady=5)
url = e1.get() # Assign the URL obtained from the input box to url
head = e2.get()
Use crawlers to crawl any blog , And stutter and segment all his articles . So as to extract keywords , Analyze the frequency of the blogger using the currently popular Internet related vocabulary .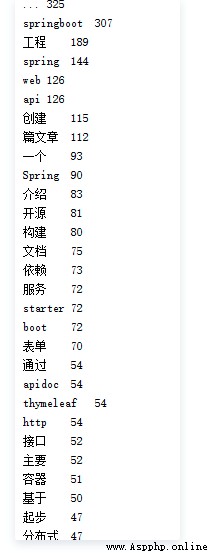
First write a function download() obtain url, Then write a function parse_descrtion() Parsing from
url From html, Final stutter participle .
def download(url): # By giving url Climb out of the data
if url is None:
return None
try:
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36', })
if (response.status_code == 200):
return response.content
return None
except:
return None
def parse_descrtion(html):
if html is None:
return None
soup = BeautifulSoup(html, "html.parser") #html String creation BeautifulSoup
links = soup.find_all('a', href=re.compile(r'/forezp/article/details'))
for link in links:
titles.add(link.get_text())
def jiebaSet():
strs=''
if titles.__len__()==0:
return
for item in titles:
strs=strs+item;
tags = jieba.analyse.extract_tags(strs, topK=100, withWeight=True)
for item in tags:
print(item[0] + '\t' + str(int(item[1] * 1000)))
The first function has nothing to say .
The second function uses beautifulsoup, Through the analysis of the web , So as to find all the conditions that meet
href=re.compile(r’/forezp/article/details’) Of a What's in the label .
The third function is stutter segmentation . Next, I will make a brief introduction to stuttering participle .
Three word segmentation modes are supported .
Accurate model : Try to cut the sentence as precisely as possible , Suitable for text analysis .
All model : Scan the sentences for all the words that can be made into words , Very fast , But it doesn't solve the ambiguity .
Search engine model : On the basis of exact patterns , Again shred long words , Increase recall rate , Suitable for search engine segmentation .
for instance , Stuttering participle “ I came to tsinghua university in Beijing ” this sentence .
【 All model 】: I / Came to / Beijing / tsinghua / Tsinghua University / Bgi, / university
【 Accurate model 】: I / Came to / Beijing / Tsinghua University
I'm going to use mongoDB database , Students can choose the database they are familiar with or meet the requirements
client = pymongo.MongoClient(“localhost”, 27017)
This sentence is to use a given host location and port .pymongo Of Connection() This method is not recommended , Officials recommend new methods MongoClient().
db = client[‘local’]
This sentence will create a good mongoDB One of the two databases that exist by default “local” Assign to db, such
db In the later program, it represents the database local.
posts = db.pymongo_test
post_id = posts.insert(data)
take local A default set in “pymongo_test” Assign a value to posts, And use insert Method single insert data . Finally, return to a loop program in stuttering participle , Insert data in sequence .
The above is the core code about connecting to the database , Next, how to start mongoDB database .( I couldn't connect to it at the beginning of programming , Later, it was found that the database itself did not start , alas , There are too many stupid things happening in programming .)
Microsoft logo +R, Input cmd, look for “mongodb” The path of , And then run mongod Open command , Simultaneous use –dbpath The designated data storage location is “db” Folder .
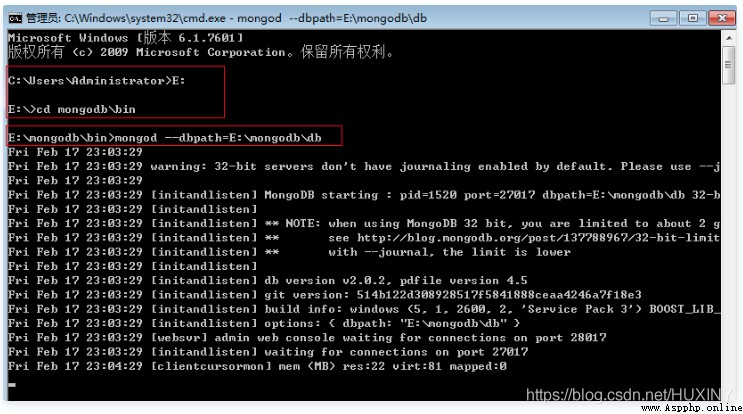
start-up mongoDB
I put it here E disc , You can set it yourself according to your needs . Finally, we need to see if it is successful , From the information in the picture ,mongodb use 27017 port , Then we will lose in the browser http://localhost:27017, After opening mongodb Tell us in 27017 On Add 1000 It can be used http Mode view mongodb Management information for .
🧿 Topic selection guidance , Project sharing :
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md