I'm going to introduce you today Pandas Two rarely used data reading file methods in :
- Read data from online files
- Read clipboard data
Statement : This case and online data are only for academic sharing
This function represents the direct reading of online html file , It is usually in the form of a table ; take HTML Convert table to DataFrame A quick and convenient way to .
This method is very useful for quickly merging tables from different web pages , It saves the time of crawling data and then reading .
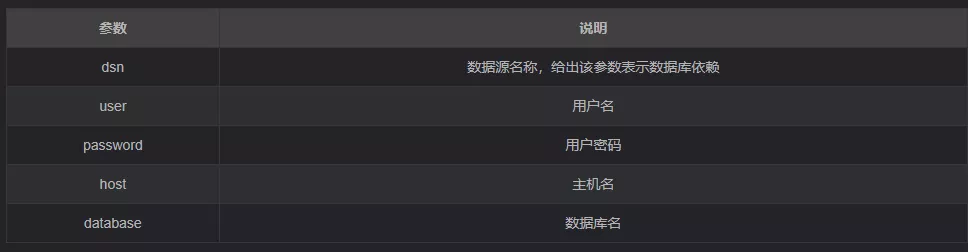
The parameters of the specific function are :
pandas.read_html(io, # file io object ; The path or io.Strings object
match='.+', # str Or compiled regular expressions , Optional
flavor=None, # The parsing engine to use , None Is the default value
header=None, # File header
index_col=None, # Indexes
skiprows=None, # Skip lines
attrs=None, # attribute
parse_dates=False, # Date resolution
thousands=',', # Thousandths
encoding=None, # code
decimal='.', # Characters recognized as decimal points
converters=None, # Property transfer
na_values=None, # Null value information
keep_default_na=True, # Whether to keep null
displayed_only=True # Should I parse a file with “display:none” The elements of
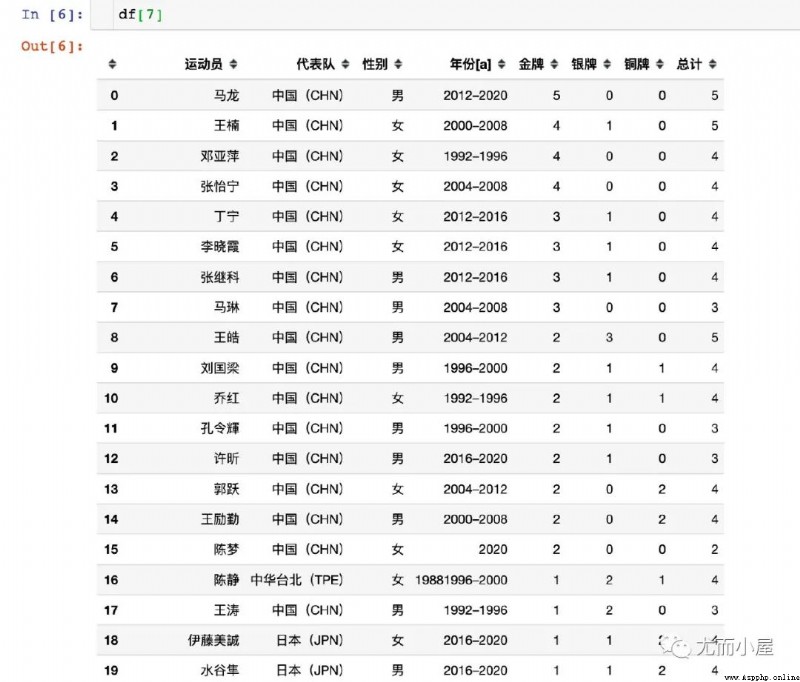
)Read the relevant data of a previous Olympic table tennis champion on Wikipedia . Some tabular data under this address :

In [3]:
url = "https://zh.m.wikipedia.org/zh/%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B9%92%E4%B9%93%E7%90%83%E5%A5%96%E7%89%8C%E5%BE%97%E4%B8%BB%E5%88%97%E8%A1%A8"
df = pd.read_html(url)
dfOut[3]:
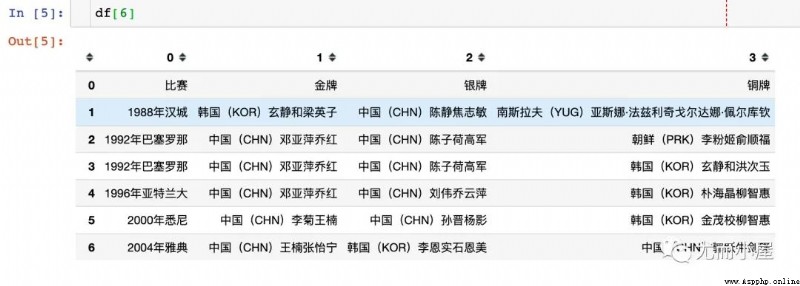
We observe what we read at this time df It's a list , The total length is 15
listIn [4]:
len(df)Out[4]:
9View some elements in the list : At this point, it is one by one DataFrame Data in form
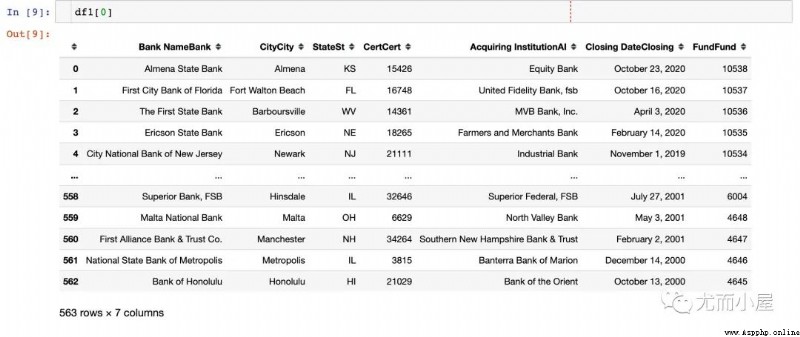
Data under a foreign website :https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list/
In [7]:
df1 = pd.read_html("https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list")
type(df1)Out[7]:
listIn [8]:
len(df1)Out[8]:
1In [9]:
df1[0]Out[9]:
To read GitHub the previous CSV File as an example :
The way 1: Direct reading
url="https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
pd.read_csv(url)
The way 2: adopt io.Strings object
url="https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
response=requests.get(url).content # First request
df2 = pd.read_csv(io.StringIO(response.decode('utf-8')))
df2 # The effect same as above pandas.read_clipboard(sep='\\s+', **kwargs)
Official website address :https://pandas.pydata.org/docs/reference/api/pandas.read_clipboard.html
A simple example shows that the function uses : Suppose there is such a in the local directory Excel Table data 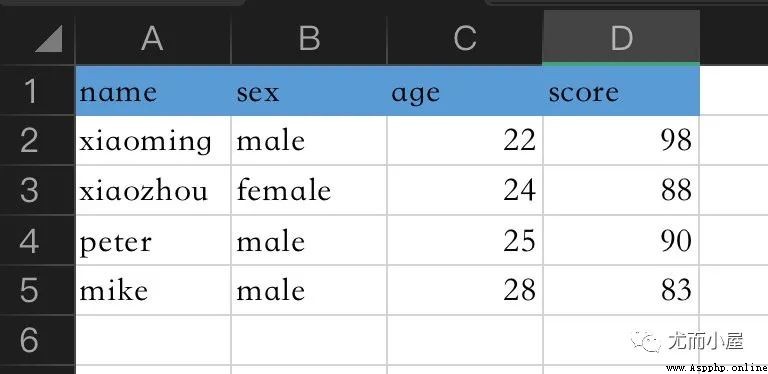
1、 Cut and paste the data first :【Ctrl + C】
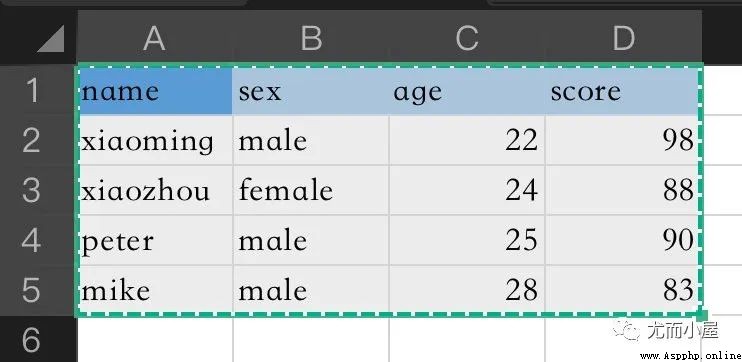
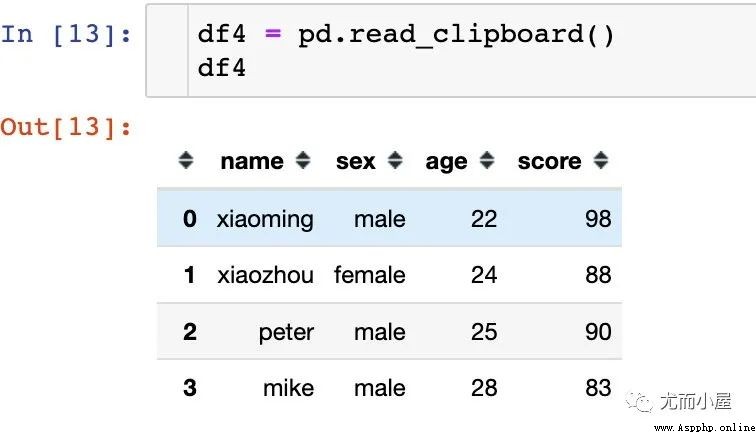
2、 Run the code below , Press down MacOS Medium 【 Up arrow 】 + 【 Enter key 】, Finish read
Windows The following should be 【Shift + Enter】
If there is less data , Pass... Is omitted Excel perhaps CSV Time of file reading mode :
- END -
contrast Excel The cumulative sales of the series of books reached 15w book , Make it easy for you to master data analysis skills , You can click on the link below to learn about purchasing :