哈奇計劃法(Harch Plan Method),又稱10%轉換法,屬於趨勢投資計劃。
它是以發明人哈奇的名字命名的股票投資方法。
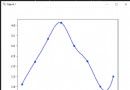
哈奇計劃法的具體操作:投資者將購進的股票在每周末計算周平均值,並在月底再計算出月平均值。若本月的平均數比最後一次的高價下降10%,則股價有可能出現下跌趨勢,投資者便賣出全部股票,而不再購進。等到他賣出股票平均市值,由最低點回升到10%,再行買進。這種方法,也就是當市場趨勢發生了10%的反向變動時,便改變投資地位。
哈奇實施這種方法不作賣空交易,在實行此種計劃的53年中,先後改變了44次地位,所持股票的期限,最短的為3個月,最長的為6年。哈奇在1882年至1936年的54年中,利用這個計劃,將其資產由10萬元提高到1440萬美元。這個計劃,直到哈奇逝世後,才被倫敦金融新聞公布。
harch_plan.py
# coding=utf-8
import os, sys
import datetime
import numpy as np
import pandas as pd
# python 按周分組統計:周平均值
if len(sys.argv) ==2:
scode = sys.argv[1]
else:
print('usage: python harch_plan.py stockcode ')
sys.exit(1)
if len(scode) !=6:
print(' scode is char(6)')
sys.exit(2)
file1 = "./" +scode +'.csv'
if not os.path.exists(file1):
print(file1 +' is not exists.')
sys.exit(3)
# 用pandas讀取csv
df = pd.read_csv(file1)
df = df[['date','close']]
df = df[ df['date'] > '2022-01-01']
df.index = pd.to_datetime(df.date)
# 計算周平均值
df_w = df.groupby(df.index.week).mean()
df_w.rename(columns={'close':'w_avg'}, inplace=True)
#print('df_week:', df_w)
# 周平均值
w_avg = np.array(df_w['w_avg'].values)
# Take diff of net values and computing rate of change
diff = np.diff(w_avg)
diff_percentage = 100.0 * np.diff(w_avg) / w_avg[:-1]
# 四捨五入到所需精度的值
diff = np.around(diff,3)
diff_percentage = np.around(diff_percentage,2)
# DataFrame 新增2列: diff,percent
df_w['diff'] = np.insert(diff,0,[0.0])
df_w['percent'] = np.insert(diff_percentage,0,[0.0])
print('df_week:\n', df_w)
# 計算月平均值
df_m = df.groupby(df.index.month).mean()
df_m.rename(columns={'close':'m_avg'}, inplace=True)
#print('df_month:', df_m)
# 月平均值
m_avg = np.array(df_m['m_avg'].values)
# Take diff of net values and computing rate of change
diff = np.diff(m_avg)
diff_percentage = 100.0 * np.diff(m_avg) / m_avg[:-1]
# 四捨五入到所需精度的值
diff = np.around(diff,3)
diff_percentage = np.around(diff_percentage,2)
# DataFrame 新增2列: diff,percent
df_m['diff'] = np.insert(diff,0,[0.0])
df_m['percent'] = np.insert(diff_percentage,0,[0.0])
print('df_month:\n', df_m)
python harch_plan.py 000661
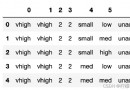
df_week:
w_avg diff percent
date
1 265.955000 0.000 0.00
2 262.621000 -3.334 -1.25
3 224.447000 -38.174 -14.54
4 168.785000 -55.662 -24.80
6 164.493000 -4.292 -2.54
7 170.169000 5.676 3.45
8 183.481000 13.312 7.82
9 180.243000 -3.238 -1.76
10 172.103000 -8.140 -4.52
11 175.933000 3.830 2.23
12 172.027000 -3.906 -2.22
13 166.303000 -5.724 -3.33
14 162.608333 -3.695 -2.22
15 158.823000 -3.785 -2.33
16 150.435000 -8.388 -5.28
17 145.051000 -5.384 -3.58
18 154.610000 9.559 6.59
19 155.139000 0.529 0.34
20 151.685000 -3.454 -2.23
21 152.951000 1.266 0.83
22 165.557500 12.607 8.24
23 172.257000 6.700 4.05
24 188.012000 15.755 9.15
25 211.330000 23.318 12.40
df_month:
m_avg diff percent
date
1 228.583421 0.000 0.00
2 173.248125 -55.335 -24.21
3 173.236304 -0.012 -0.01
4 154.038158 -19.198 -11.08
5 154.295000 0.257 0.17
6 188.042059 33.747 21.87