Scrapy Yes, it is Python The implementation of a web site in order to crawl data 、 Application framework for extracting structural data .
Scrapy Often used in including data mining , In a series of programs that process or store historical data .
Usually we can simply pass Scrapy The framework implements a crawler , Grab the content or pictures of the specified website .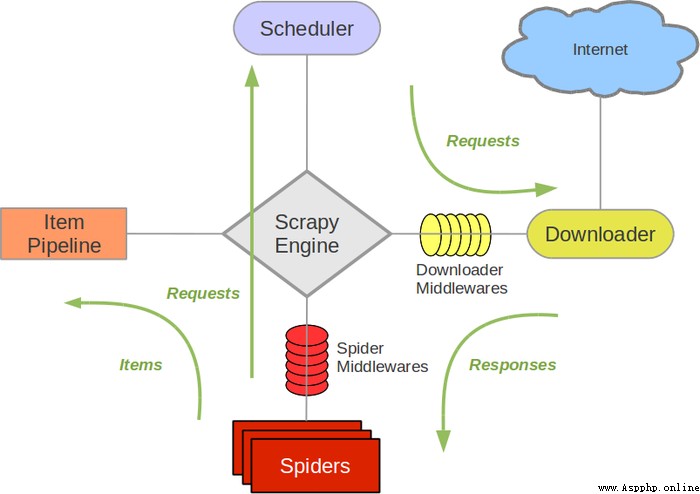
Scrapy Engine( engine ): be responsible for Spider、ItemPipeline、Downloader、Scheduler Intermediate communication , The signal 、 Data transfer, etc .
Scheduler( Scheduler ): It's responsible for receiving what the engine sends Request request , And in accordance with a certain way to arrange the arrangement , The team , When the engine needs , Give it back to the engine .
Downloader( Downloader ): Responsible for downloading Scrapy Engine( engine ) All sent Requests request , And get it Responses Return to Scrapy Engine( engine ), Engine to Spider To deal with it ,
Spider( Reptiles ): It handles everything Responses, Analyze and extract data from it , obtain Item The data required for the field , And will need to follow up URL Submit to engine , Once again into the Scheduler( Scheduler ).
Item Pipeline( The Conduit ): It handles Spider Obtained in Item, And carry out post-processing ( Detailed analysis 、 Filter 、 Storage, etc ) The place of .
Downloader Middlewares( Download Middleware ): Think of it as a component that you can customize to extend the download functionality .
Spider Middlewares(Spider middleware ): You can understand it as a custom extension and operation engine and Spider Functional components of intermediate communication ( Such as into the Spider Of Responses; And from the Spider Out of the Requests)
Make Scrapy Reptiles Total needs 4 Step :
1、 New projects (scrapy startproject xxx): Create a new crawler project
2、 Clear objectives ( To write items.py): Identify the goals you want to capture
3、 Making reptiles (spiders/xxspider.py): Make a crawler to start crawling the web
4、 Store content (pipelines.py): Design pipeline to store crawling content
Before you start crawling , You have to create a new Scrapy project . Enter the custom project directory , Run the following command :
scrapy startproject mySpider
among , mySpider Is the project name , As you can see, it's going to create a mySpider Folder , The directory structure is roughly as follows :
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
Let's briefly introduce the functions of each main file :
scrapy.cfg: The configuration file for the project .
mySpider/: Project Python modular , The code will be referenced from here .
mySpider/items.py: The project's target file .
mySpider/pipelines.py: Pipeline files for the project .
mySpider/settings.py: The setup file for the project .
mySpider/spiders/: Store crawler code directory .
We're going to grab it http://www.itcast.cn/channel/teacher.shtml Names of all lecturers on the website 、 Title and personal information .
open mySpider In the catalog items.py.
Item Define structured data fields , Used to save crawled data , It's kind of like Python Medium dict, But it provides some extra protection to reduce errors .
You can do this by creating a scrapy.Item class , And the definition type is scrapy.Field Class property to define a Item( It can be understood as similar to ORM The mapping relation of ).
Next , Create a ItcastItem class , And build item Model (model).
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
The crawler function is divided into two steps :
Enter a command in the current directory , Will be in mySpider/spider Create a directory called itcast The reptiles of , And specify the scope of the crawl domain :
scrapy genspider itcast "itcast.cn"
open mySpider/spider In the directory itcast.py, The following code has been added by default :
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
In fact, it can also be created by ourselves itcast.py And write the above code , But using commands can save you the trouble of writing fixed code
To build a Spider, You have to use scrapy.Spider Class creates a subclass , And three mandatory properties are determined and One way .
name = “” : The identifying name of this crawler , Must be unique , Different names must be defined in different crawlers .
allow_domains = [] Is the domain name range of the search , That's the constraint area of the crawler , The crawler only crawls the web page under this domain name , There is no the URL Will be ignored .
start_urls = () : The crawl URL Yuan Zu / list . This is where the crawler starts to grab data , therefore , The first download of data will come from these urls Start . Other children URL It will start with these URL In inheritance generation .
parse(self, response) : The method of analysis , Each initial URL When the download is complete, it will be called , Call when passed in from each URL Back to the Response Object as the only parameter , The main functions are as follows :
Responsible for parsing the returned web page data (response.body), Extract structured data ( Generate item)
Generate... That requires the next page URL request .
take start_urls The value of is changed to the first one that needs to be crawled url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
modify parse() Method
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
Then run it and see , stay mySpider Execute under directory :
scrapy crawl itcast
Yes , Namely itcast, Look at the code above , It is ItcastSpider Class name attribute , That is to use scrapy genspider The only crawler name of the command .
After running , If the printed log appears [scrapy] INFO: Spider closed (finished), On behalf of the executive . After that, there will be a teacher.html file , Inside is all the source code information of the web page we just want to crawl .
scrapy There are four simple ways to save information ,-o Output file in specified format , The order is as follows :
scrapy crawl itcast -o teachers.json
json lines Format , The default is Unicode code
scrapy crawl itcast -o teachers.jsonl
csv Comma expression , You can use Excel open
scrapy crawl itcast -o teachers.csv
xml Format
scrapy crawl itcast -o teachers.xml