I don't know when people are bored at work , Is there an impulse : Always want to take out your cell phone , Look at what interesting topics microblog search is discussing , But it is not convenient to open the microblog directly
Browse , Today I'll share with you an interesting little reptile , Regularly collect microblog hot search list & Hot comment , Let's take a look at the specific implementation method .
Hot list home page :https://s.weibo.com/top/summary?cate=realtimehot
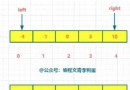
There are 50 pieces of data in the list on the front page of the hot list , On this page , We need to get the ranking 、 degree of heat 、 title , And a link to the details page .
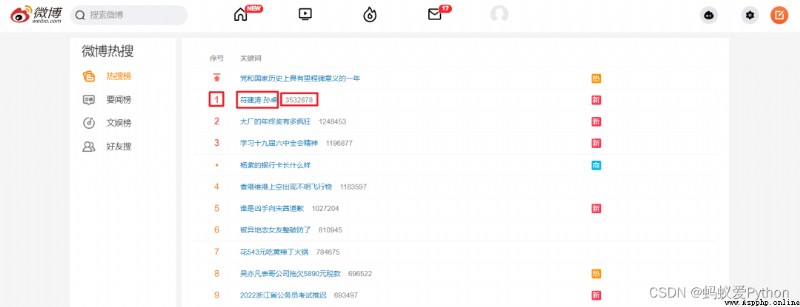
When we open the page, we first Sign in , Then use F12 Open developer tools ,Ctrl + R After refreshing the page, find the first packet . Here you need to record your
Cookie And User-Agent.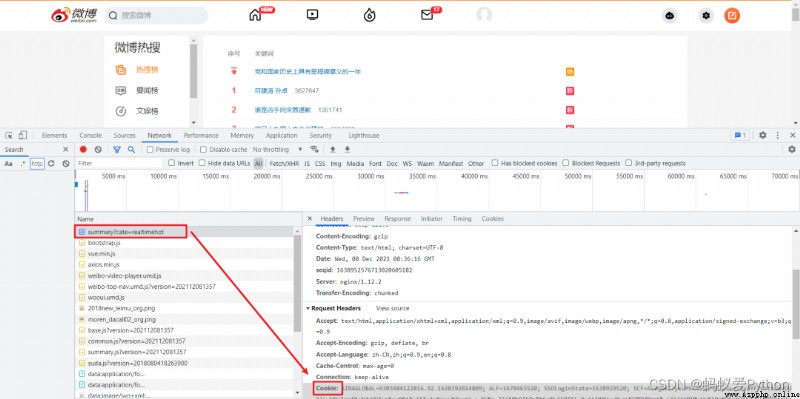
For label positioning , Use it directly Google Tool to get the name of the tag xpath The expression is just .
For the details page , We need to get comment time 、 User name 、 Forwarding times 、 Comment frequency 、 Number of likes 、 Comment content this part of the information .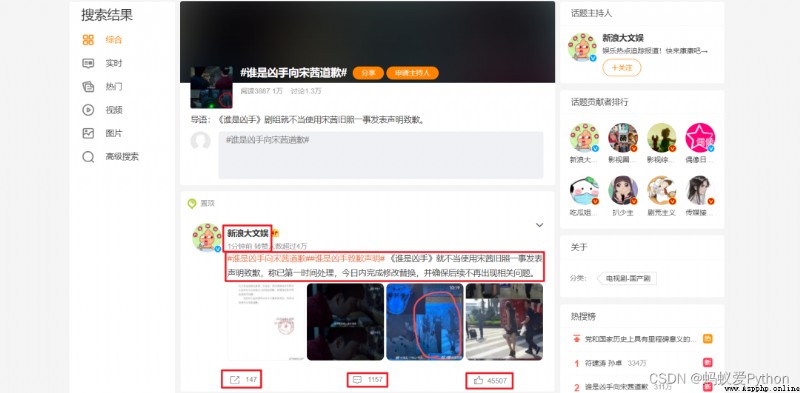
The method is basically the same as the hot search page collection method , Let's see how to implement !
First import the required modules .
python plug-in unit / material / Source code plus Q Group :903971231####
import requests
from time import sleep
import pandas as pd
import numpy as np
from lxml import etree
import re
Define global variables .
•headers: Request header
•all_df:DataFrame, Save the collected data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36',
'Cookie': ''' Yours Cookie'''
}
all_df = pd.DataFrame(columns=[' Ranking ', ' degree of heat ', ' title ', ' Comment on time ', ' User name ', ' Forwarding times ', ' Comment frequency ', ' Number of likes ', ' Comment content '])
Hot search list collection code , adopt requests Initiate request , After getting the link to the details page , Jump to the details page get_detail_page.
def get_hot_list(url):
''' Microblog hot search page collection , After getting the link to the details page , Jump to the details page :param url: Microblog hot search page link :return: None '''
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
tr_list = tree.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr')
for tr in tr_list:
parse_url = tr.xpath('./td[2]/a/@href')[0]
detail_url = 'https://s.weibo.com' + parse_url
title = tr.xpath('./td[2]/a/text()')[0]
try:
rank = tr.xpath('./td[1]/text()')[0]
hot = tr.xpath('./td[2]/span/text()')[0]
except:
rank = ' Roof placement '
hot = ' Roof placement '
get_detail_page(detail_url, title, rank, hot)
Follow the link on the details page , Parse the required page data , And save it to a global variable all_df in , For each hot search, only the first three hot reviews are collected , If the hot comments are not enough, skip .
def get_detail_page(detail_url, title, rank, hot):
''' Follow the link on the details page , Parse the required page data , And save it to a global variable all_df :param detail_url: Details page link :param title: title :param rank: ranking :param hot: degree of heat :return: None '''
global all_df
try:
page_text = requests.get(url=detail_url, headers=headers).text
except:
return None
tree = etree.HTML(page_text)
result_df = pd.DataFrame(columns=np.array(all_df.columns))
# Crawling 3 A hot comment message
for i in range(1, 4):
try:
comment_time = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{
i}]/div[2]/div[1]/div[2]/p[1]/a/text()')[0]
comment_time = re.sub('\s','',comment_time)
user_name = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{
i}]/div[2]/div[1]/div[2]/p[2]/@nick-name')[0]
forward_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{
i}]/div[2]/div[2]/ul/li[1]/a/text()')[1]
forward_count = forward_count.strip()
comment_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{
i}]/div[2]/div[2]/ul/li[2]/a/text()')[0]
comment_count = comment_count.strip()
like_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{
i}]/div[2]/div[2]/ul/li[3]/a/button/span[2]/text()')[0]
comment = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{
i}]/div[2]/div[1]/div[2]/p[2]//text()')
comment = ' '.join(comment).strip()
result_df.loc[len(result_df), :] = [rank, hot, title, comment_time, user_name, forward_count, comment_count, like_count, comment]
except Exception as e:
print(e)
continue
print(detail_url, title)
all_df = all_df.append(result_df, ignore_index=True)
Scheduling code , towards get_hot_list Of the incoming hot search page url , Finally, save it .
if __name__ == '__main__':
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
get_hot_list(url)
all_df.to_excel(' Working documents .xlsx', index=False)
python plug-in unit / material / Source code Q Group :903971231####
For some places where errors may occur during the collection process , In order to ensure the normal operation of the program , Are ignored through exception handling , The overall impact is small !
Working documents .xlsx
thus , The acquisition code has been completed , Want to run code automatically every hour , have access to 「 Task scheduler 」.
Before that, we need to briefly modify the... In the above code Cookie And the saving path of the last file ( Absolute path is recommended ), If in Jupyter notebook You need to export a .py file
Open task scheduler ,【 Create tasks 】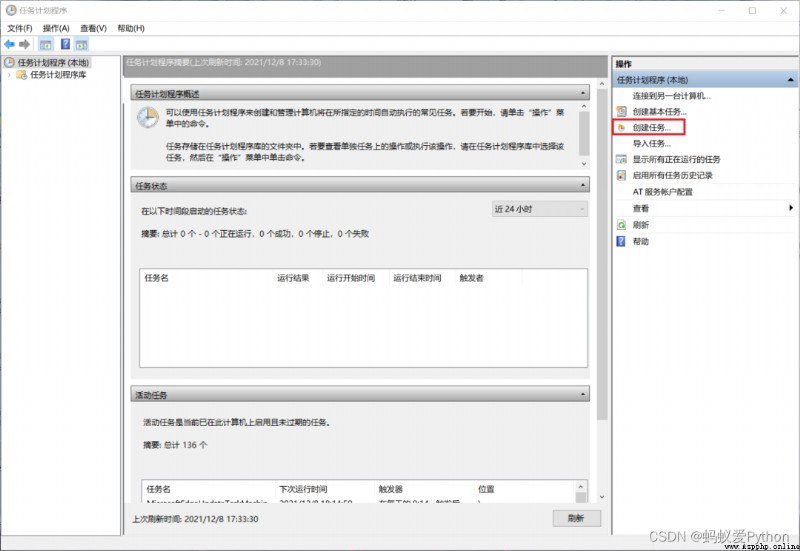
Enter a name , Just name it casually .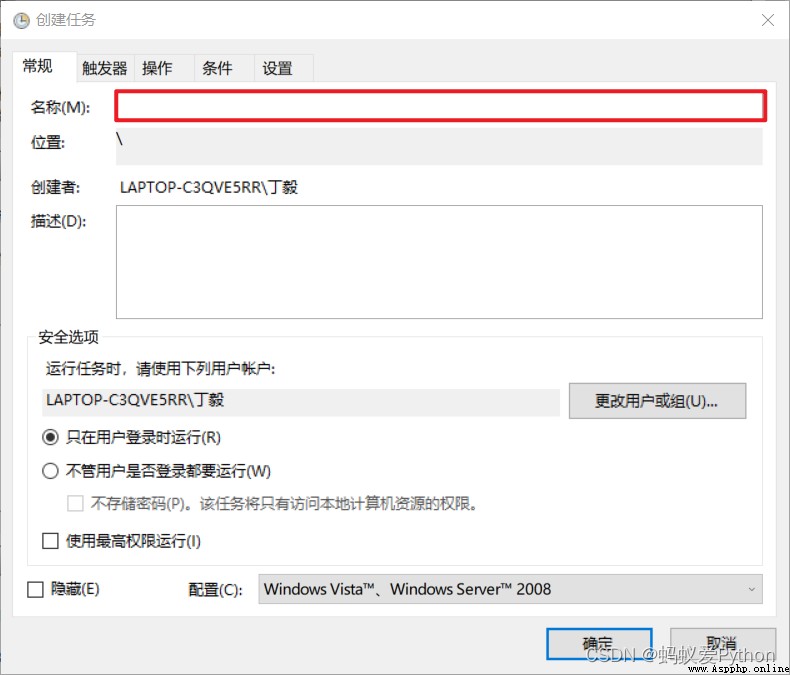
choice 【 trigger 】>>【 newly build 】>>【 Set the trigger time 】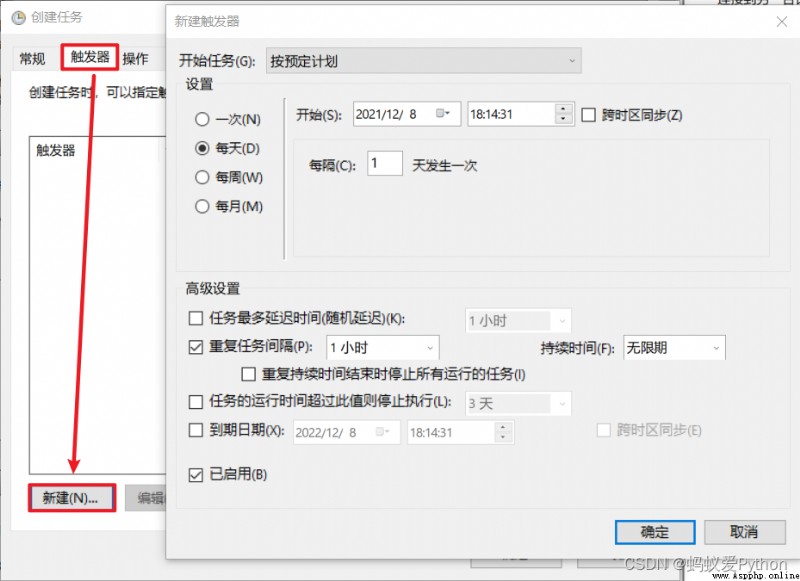
choice 【 operation 】>>【 newly build 】>>【 Choose the program 】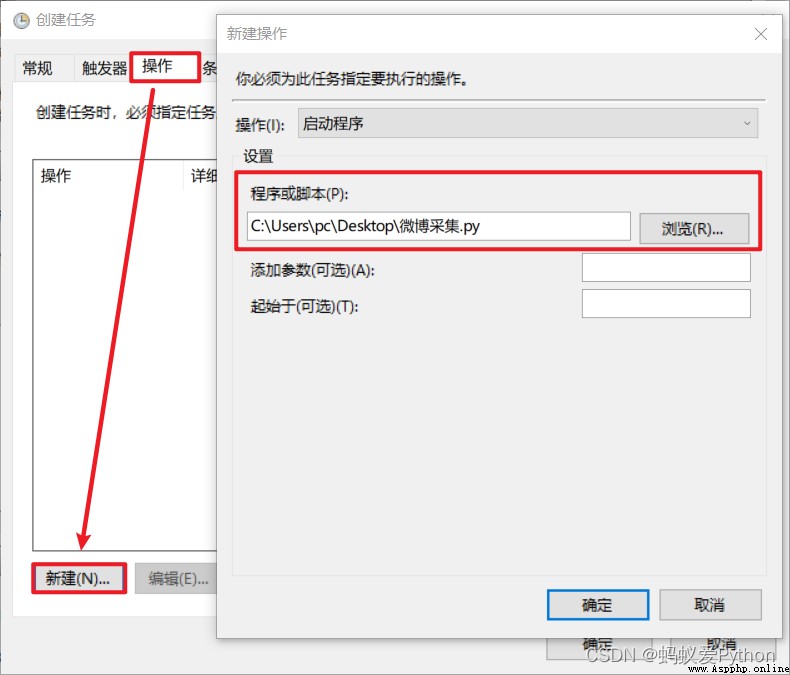
Finally confirm . When the time comes, it will run automatically , Or right-click the task to run it manually .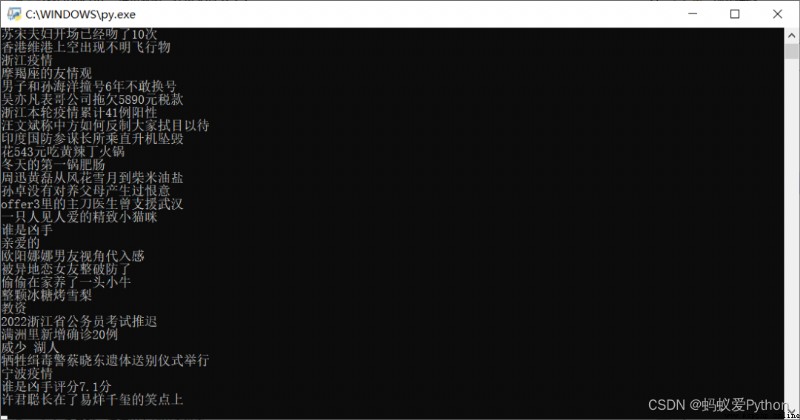
「 Running effect 」
That's what I want to share today , The overall difficulty is not big , I hope you can get something , The code in the article can be spliced together to run , If you have any questions, you can contact
It's me !