Douban reading can search the corresponding type of books through the tag , But for now I can only see 1000 Ben .
So write one Douban_spider class , It is convenient to query the corresponding types of books .
def __init__(self, keyword):
self.keyword = keyword
self.url = "https://book.douban.com/tag/"+self.keyword
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"
}
def get_page(self, start):
params = {
"start": start*20,
"type": "T"
}
response = requests.get(self.url, params=params,
headers=self.headers).text
return response
The first is to define the initial attributes , Including the initial url、 Request header .keyword The parameter is the type of book you want to search , For example, novels .
Then get the web page source code . Through observation url It is easy to construct start Parameters , That is the next page of Douban book list .
An initial class attribute is also defined here , That is, an empty list is defined . Write at the end of the article .
def get_book(self, html):
doc = pq(html)
for items in doc("li.subject-item ").items():
book = items.find("h2").text()
message = items.find("div.pub").text()
score = items.find("span.rating_nums").text()
number = items.find("span.pl").text()[1:-1]
yield{
"book": book,
"message": message,
"score": score,
"number": number
}
def get_sort(self, html):
for j in self.get_book(html):
self.ls.append(j)
self.ls.sort(key=lambda x: x["score"], reverse=True)
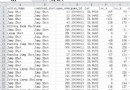
Here use pyquery Parse original web page , Get the title of the book , Press price and other information , score , Number of evaluators . among get_sort The method is to write the result to txt Sort the books according to their scores . If it's writing excel Of csv This method is not used for files of type . Write dictionary type data directly to txt Need to use json Library dumps Method . Write the dictionary directly into csv Files need to use csv library ,csv For a detailed description of the library, please refer to the relevant materials . And pay attention to writing csv When you file, add encoding and newline Two parameters , Otherwise, there will be chaos . Finally, integrate the code .
import time
import re
import requests
import json
import os
import random
import csv
from pyquery import PyQuery as pq
class Douban_spider(object):
ls = []# Class properties , Empty list , For subsequent writing txt Sorting of documents
def __init__(self, keyword):
self.keyword = keyword
self.url = "https://book.douban.com/tag/"+self.keyword
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"
}
def get_page(self, start):
params = {
"start": start*20,
"type": "T"
}
response = requests.get(self.url, params=params,
headers=self.headers).text
return response
def get_book(self, html):
doc = pq(html)
for items in doc("li.subject-item ").items():
book = items.find("h2").text()
message = items.find("div.pub").text()
score = items.find("span.rating_nums").text()
number = items.find("span.pl").text()[1:-1]
yield{
"book": book,
"message": message,
"score": score,
"number": number
}
def get_sort(self, html):
for j in self.get_book(html):
self.ls.append(j)
self.ls.sort(key=lambda x: x["score"], reverse=True)
def write_book(self):
with open(self.keyword+".txt", "w", encoding="utf-8") as file:
file.write(json.dumps(self.ls, indent=2, ensure_ascii=False))
def write_csv(self, data):
with open(self.keyword+".csv", "a", encoding="utf-8-sig", newline='') as file:
fieldnames = ["book", "message",
"score", "number"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
if __name__ == "__main__":
""" Write results to txt The document can use this code a=Douban_spider(" A novel ") for i in range(50): html=a.get_page(i) a.get_sort(html) time.sleep(random.randint(3,5)) a.write_book()"""
# write in csv The file uses the following code
a = Douban_spider(" A novel ")
for i in range(50):
html = a.get_page(i)
for data in a.get_book(html):
a.write_csv(data)
time.sleep(random.randint(3, 5))
# Delay is set here to prevent being blocked