hello , Hello everyone .
Now when we do data analysis , It is inevitable to deal with text data , Today, I will share with you in data analysis , How to mine similar text .
This article starts with the question , To solve the problem , And then to the three aspects of algorithm principle .
Suppose in an e-commerce APP in , We want to find out what's in a product review , About “ The express delivery is poor ” The comments , What to do ?
If you only use string matching , You might go through all the comments , Judge whether each comment contains “ The express delivery is poor ” character string .
However, this approach is invalid for the following comments
To solve the above problems , Need help Latent semantic index (Latent Semantic Indexing, hereinafter referred to as LSI) Algorithm .
LSI The algorithm can mine similar text , therefore , adopt LSI Algorithms can be found with “ The express delivery is poor ” Similar comments .
Let's take the previous article 《 Explore the topic of Zhang's video comments 》 For example , practice LSI Algorithm .
Classmate Zhang's Video Comments
The last article captured the Tiktok video of Zhang 1.2w comments , Corresponding to the above picture text Column .
First , Comment participle , And remove the stop words .
origin_docs = df['text'].values documents = [jieba.lcut(doc)fordocinorigin_docs] texts = [[wordforwordindocifwordnotinfilter_wrods]fordocindocuments]
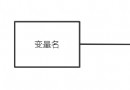
texts Variable
then , use gensim Build a comment Dictionary , And count the number of times each word appears in each comment ( Word frequency ).
from gensim import corpora, models, similarities # Building a dictionary , Number each word dictionary = corpora.Dictionary(texts) # The frequency of each word in each comment corpus = [dictionary.doc2bow(text)fortextintexts]
corpus Variable
dictionary take texts The text in the variable becomes a numeric number . Such as : Hot good The number of is 0, rice The number of is 1.
doc2bow() Medium bow yes Bag-of-Words Abbreviation , representative The word bag model , The model is used to calculate the word frequency in comments .
corpus Variables and texts Variables correspond to .corpus[0] The first tuple in (0, 1) The number of times the word "hot" appeared in the first comment is 1, Second tuple (1, 1) The number of times the rice appears is 1.
next , structure LSI Model
lsi = models.LsiModel( corpus, id2word=dictionary, power_iters=100, num_topics=10 )
num_topics Is the number of topics commented , In the last article, we found out 8 Three themes are better , The number of topics we set here is 10 individual , A little larger is better for mining similar text later .
Last , Build each comment vector The index of , It is convenient to inquire later .
# lsi[corpus] Is the vector of all comments index = similarities.MatrixSimilarity(lsi[corpus])
In classmate Zhang's Video Comments , A lot of people are right “ feed a dog ” The lens is impressive .
Let's query and “ Think you eat , The result is to feed the dog ” Similar comments .
query =' Think you eat , The result is to feed the dog ' # The word bag model , Count the frequency of words vec_bow = dictionary.doc2bow(jieba.lcut(query)) # Calculation query The corresponding vector vec_lsi = lsi[vec_bow] # Calculate each comment and query The similarity sims = index[vec_lsi]
after LSI After processing , Every comment can be made with vector Express , alike ,query It can also be used. vector Express .
therefore ,index[vec_lsi] It's actually calculation vector The similarity between , The method used here is Cosine similarity . The closer the result is 1 explain query The more similar to this comment .
The following is inverted according to the similarity , Output and query Similar comments .
# Output ( Original document , Similarity degree ) Binary result = [(origin_docs[i[0]],i[1])foriinenumerate(sims)] # Sort in reverse order according to similarity sorted(result ,key=lambda x: -x[1])
Similar text
You can see , The effect is good , It can mine many similar texts .
LSI As we said before LDA similar , Can be used to calculate the topic of each text .
LSI Is based on Singular value decomposition (SVD) Method to get the theme of the text .SVD The approximate formula is :
among ,m Represents the number of words in all comments ,n Represents the number of comments ,k Represents the number of topics after decomposition .
matrix Corresponding n Comments , There are... Under each comment m Word .
matrix Corresponding k A theme , Under each theme ,m Probability distribution of words .
matrix After transpose is n*k Matrix , Corresponding n document , Under each document ,k Probability distribution of topics .
therefore , Each line in the is actually the of each comment vector , This matrix corresponds to the code above , yes lsi[corpus].
Above we mentioned the use of Cosine similarity Calculate vector similarity . In high school mathematics , The cosine similarity of two vectors is actually the angle between two vectors
Angle 0 When the degree of , Two vectors coincide ( equal ), The similarity is 1
Angle 90 When the degree of , Two vectors are perpendicular ( Unrelated ), The similarity is 0
Angle 180 When the degree of , Two vectors are reversed , The similarity is -1
Come here , be based on LSI The similar text mining of . After learning this article , You can see that LSI It can not only mine similar text , You can even make text recommendations 、 Search engines and so on .
Of course, it has disadvantages , Interested friends can continue to study deeply .