本文的所有演示數據,均是基於下方的四張表。下面這四張表大家應該不陌生,這就是網傳50道經典MySQL面試題中使用到的幾張原表。關於下方各表之間的關聯關系,我就不給大家說明了,仔細觀察字段名,應該就可以發現。喜歡本文記得收藏、關注、點贊。
注:技術交流、資料獲取,文末見

pandas中的DataFrame是一個二維表格,數據庫中的表也是一個二維表格,因此在pandas中使用sql語句就顯得水到渠成,pandasql使用SQLite作為其操作數據庫,同時Python自帶SQLite模塊,不需要安裝,便可直接使用。
這裡有一點需要注意的是:使用pandasql讀取DataFrame中日期格式的列,默認會讀取年月日、時分秒,因此我們要學會使用sqlite中的日期處理函數,方便我們轉換日期格式,下方提供sqlite中常用函數大全,希望對你有幫助。
sqlite函數大全:http://suo.im/5DWraE
導入相關庫:
import pandas as pd
from pandasql import sqldf
① 在使用之前,聲明該全局變量;
② 一次性聲明好全局變量;
df1 = pd.read_excel("student.xlsx")
df2 = pd.read_excel("sc.xlsx")
df3 = pd.read_excel("course.xlsx")
df4 = pd.read_excel("teacher.xlsx")
global df1
global df2
global df3
global df4
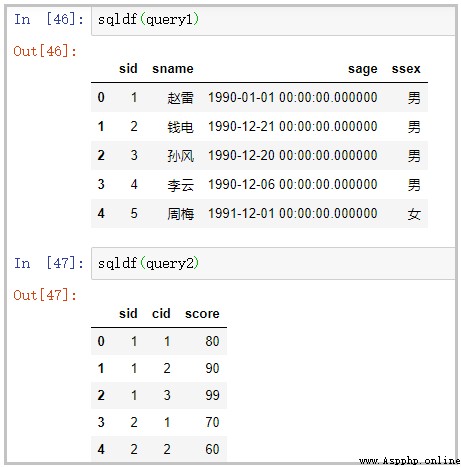
query1 = "select * from df1 limit 5"
query2 = "select * from df2 limit 5"
query3 = "select * from df3"
query4 = "select * from df4"
sqldf(query1)
sqldf(query2)
sqldf(query3)
sqldf(query4)
部分結果如下:
df1 = pd.read_excel("student.xlsx")
df2 = pd.read_excel("sc.xlsx")
df3 = pd.read_excel("course.xlsx")
df4 = pd.read_excel("teacher.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = "select * from df1 limit 5"
query2 = "select * from df2 limit 5"
query3 = "select * from df3"
query4 = "select * from df4"
sqldf(query1)
sqldf(query2)
sqldf(query3)
sqldf(query4)
部分結果如下:
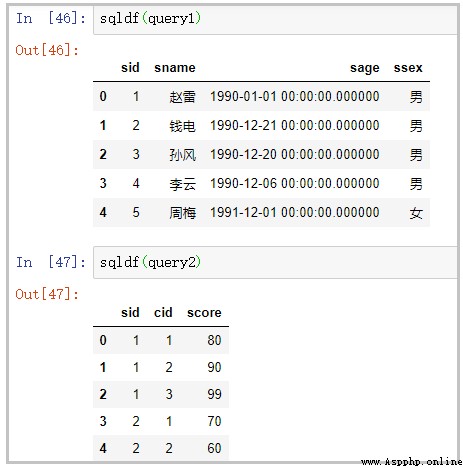
student = pd.read_excel("student.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = """ select sqlite_version(*) """
pysqldf(query1)
結果如下:
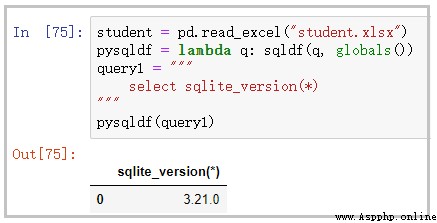
student = pd.read_excel("student.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = """ select * from student where strftime('%Y-%m-%d',sage) = '1990-01-01' """
pysqldf(query1)
結果如下:
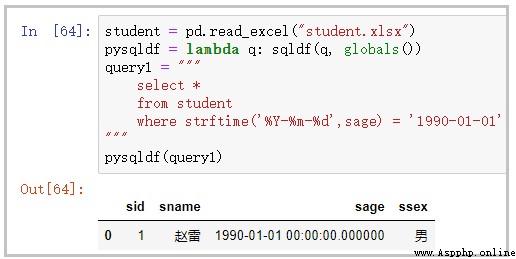
student = pd.read_excel("student.xlsx")
sc = pd.read_excel("sc.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query2 = """ select * from student s join sc on s.sid = sc.sid """
pysqldf(query2)
部分結果如下:
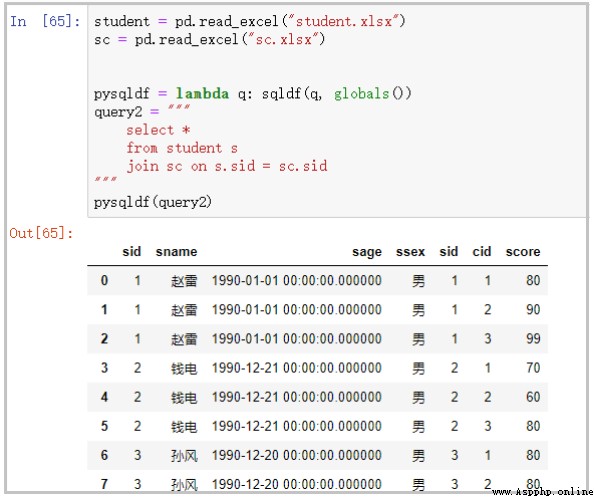
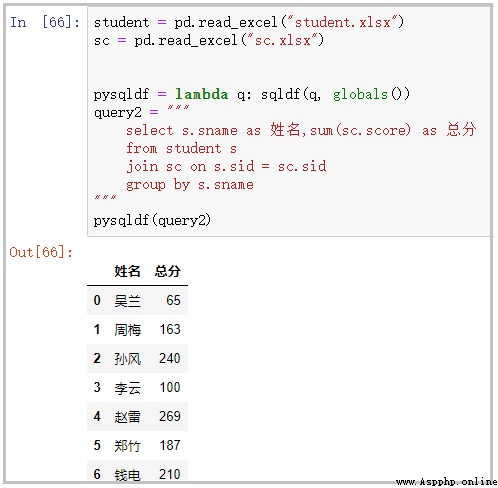
student = pd.read_excel("student.xlsx")
sc = pd.read_excel("sc.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query2 = """ select s.sname as 姓名,sum(sc.score) as 總分 from student s join sc on s.sid = sc.sid group by s.sname """
pysqldf(query2)
結果如下:
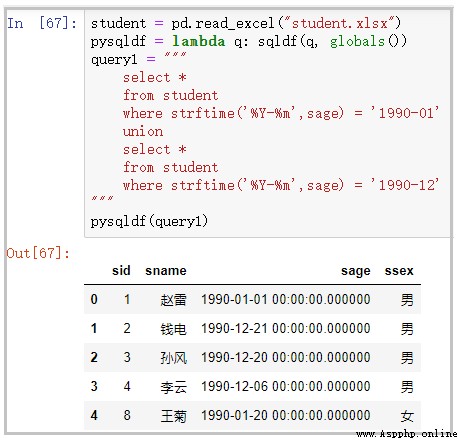
student = pd.read_excel("student.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = """ select * from student where strftime('%Y-%m',sage) = '1990-01' union select * from student where strftime('%Y-%m',sage) = '1990-12' """
pysqldf(query1)
結果如下:
目前開通了技術交流群,群友已超過3000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友
方式①、發送如下圖片至微信,長按識別,後台回復:加群;
方式②、添加微信號:dkl88191,備注:來自CSDN
方式③、微信搜索公眾號:Python學習與數據挖掘,後台回復:加群