I often think about it recently ,Python What positions can I take office in ?
So I took aim at the ByteDance school recruitment website https://jobs.bytedance.com/campus/position?, Want to use requests Module to crawl Python Related positions
But as we all know ,get It is not difficult to request to crawl to the web page source code , The hard part is to find the corresponding target data post request
To avoid this “ Fucking ” One of the , Operate directly in the browser —— therefore selenium Here it comes
 And requests Different ,selenium Just enter a get The request is done. First edit the target url Parameters of :
And requests Different ,selenium Just enter a get The request is done. First edit the target url Parameters of :
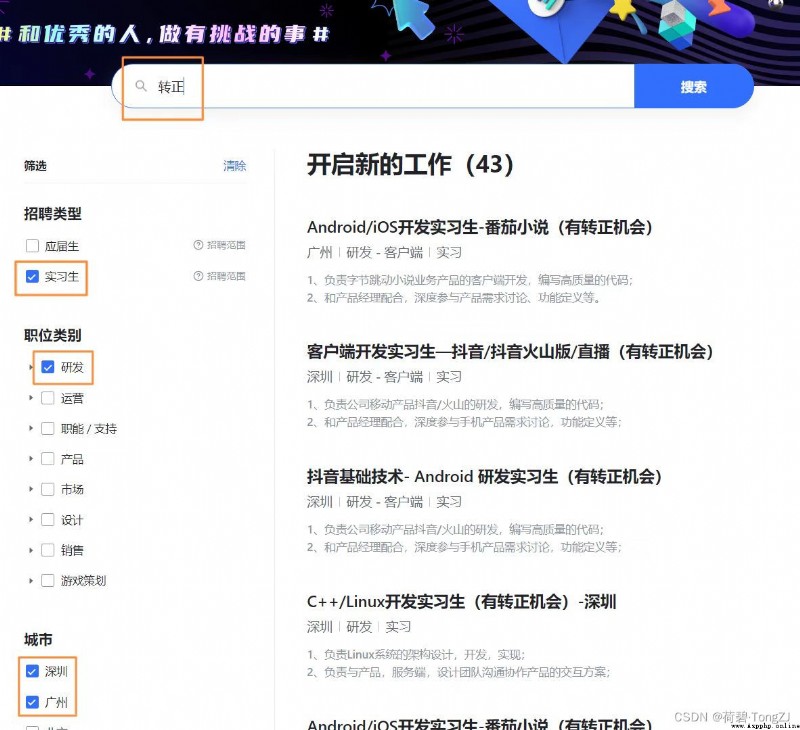
https://jobs.bytedance.com/campus/position?keywords= become a regular worker &location=CT_128%2CCT_45&type=3¤t=1&limit=10
Parse the key value pairs in the new URL , And modify the code params Dictionary keywords、location、category、type, Use for Loop can be spliced to get the final url
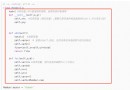
import pandas as pd
from selenium.webdriver import Edge
from tqdm import tqdm
url = f'https://jobs.bytedance.com/campus/position?'
params = {
'keywords': ' become a regular worker ', # Search keywords
'location': 'CT_45%2CCT_128', # Work city : Guangzhou , Shenzhen
'category': '6704215862603155720%2C6704215862557018372%2C6704215956018694411%2C6704215886108035339%2C6704215957146962184%2C6704215897130666254%2C6704215958816295181%2C6704215888985327886%2C6704215963966900491%2C6704216109274368264%2C6704217321877014787%2C6704219452277262596%2C6704216635923761412%2C6704219534724696331%2C6704216296701036811%2C6938376045242353957',
# Position type : Research and development
'type': 3, # Recruitment type : The intern
'limit': 10000 # The page position displays
}
for key in params:
url += f'{key}={params[key]}&'And requests The difference is ,selenium Unwanted post request , But you need to wait for the page to load , So you need a while Loop to wait for the page to load , Reuse xpath Locate nodes
def xpath(root, value, verbose=False):
''' selenium Node element positioning
root: Root node
value: xpath expression
verbose: Output debugging information '''
while 1:
try:
result = root.find_elements('xpath', value)
if result:
return result if len(result) != 1 else result[0]
except:
if verbose: print('\r No corresponding element found ...', end='')Check through the web page , Find the location of the corresponding position link , Copy xpath Modify the wave again , You can get links to all positions on this page
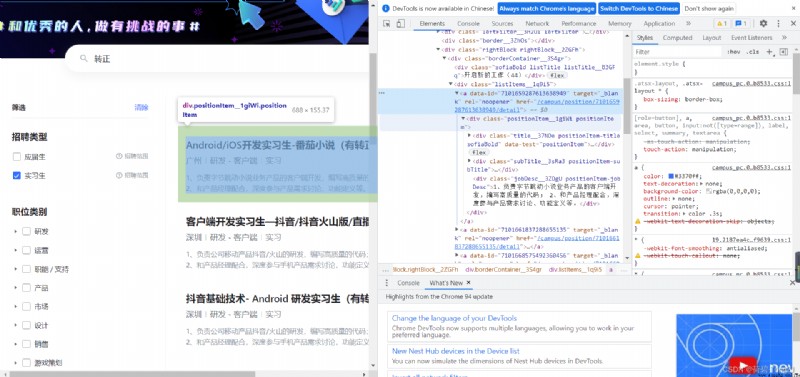
In a similar , Find the position connection “ Job requirements ” The location of ( You can also find the position of the title ), You can write the main function
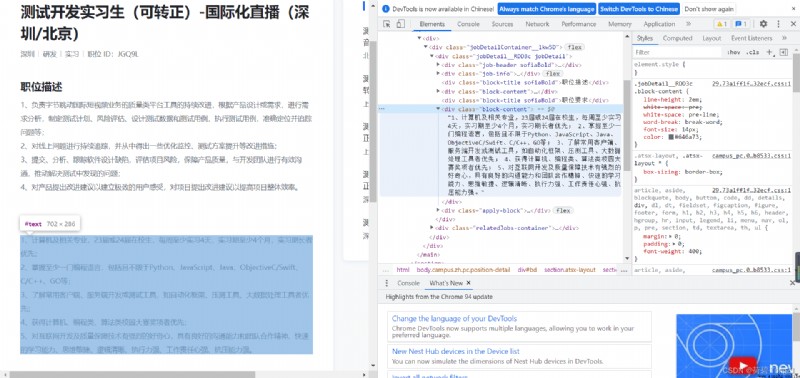
def byte_dance(keywords=[], stopwords=[]):
''' keywords: Keyword sequence
stopwords: Stop word sequence '''
web = Edge()
web.get(url)
# Find links to each position
links = xpath(web, '//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a', verbose=True)
links = list(map(lambda link: link.get_attribute('href'), links))
# Screen the school enrollment information
desired = []
for link in tqdm(links):
web.get(link)
box = xpath(web, '//*[@id="bd"]/section/section/main/div/div/div[1]')
# Read position name 、 Job requirements
title = xpath(box, 'div[1]/span').text
require = xpath(box, 'div[6]').text
# Check whether the keyword is not in the job requirements
fail = list(filter(lambda kwd: kwd not in require, keywords)) + \
list(filter(lambda swd: swd in require, stopwords))
if not fail: desired.append({'link': link, 'title': title, 'require': require})
web.quit()
return pd.DataFrame(desired)Finally using pandas Of ExcelWriter Write the filtered data to Excel
def excel_dump(dataframe, file, sheet_name='tzj', float_format='%.4f'):
writer = pd.ExcelWriter(file)
dataframe.to_excel(writer, sheet_name=sheet_name, float_format=float_format)
writer.save()
desired = byte_dance(keywords=['Python'], stopwords=[])
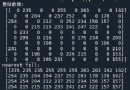
print(desired)
excel_dump(desired, ' I'm sorry .xlsx')all “ Job requirements ” It appears that “Python” The positions are :
link Test development interns ( Can become a regular )- International live broadcast ( Shenzhen / Beijing ) - Add byte jitter Tiktok graphic image algorithm intern ( Can become a regular ) - Add byte jitter Background development intern - Storage ( There is a chance to become a regular ) - Add byte jitter Background development intern - Infrastructure — There is a chance to become a regular - Add byte jitter Back end development interns - Tiktok / Volcano / International video ( There is a chance to become a regular ) - Add byte jitter Background development intern — Advertising system ( Can become a regular ) - Add byte jitter Recommend algorithm interns - Tiktok ( There is a chance to become a regular ) - Add byte jitter Algorithm Intern — Direction of risk control — There is a chance to become a regular - Add byte jitter Test development interns - Advertising system ( Can become a regular ) - Add byte jitter