最近有個好哥們啊浪迫於家裡工資太低,准備從北方老家那邊來深圳這邊找工作,啊浪是學平面設計的知道我在深圳這邊於是向我打聽深圳這邊平面設計薪資水平,當時我有點懵逼這個行業不熟悉啊咋搞呢,准備打開招聘網站先看看再說打開網站輸入招聘職位發先量還挺大,這樣慢慢看不行啊效率太低啦,咋是程序員啊直接把數據拉下來不就行啦於是有啦這篇博客。
import os
import json
import urllib
import requests
數據地址:https://www.lagou.com/
當我在 chrom 中輸入拉勾網站查看頁面源碼時發現頁面上的數據並沒有直接顯示在源碼上。推斷可能是使用 AJAX 異步加載數據,當我打開 chrom 開發者工具在 network 中查看 XHR 時發現一個 https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false 請求點開 response 果然數據都在這個請求中返回。
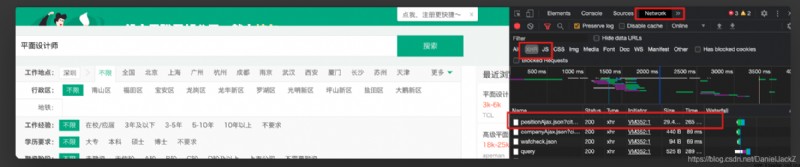
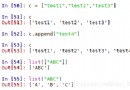
返回的數據格式如下:

可以發現我們需要的數據都存放在 result 中,於是准備直接獲取數據但是使用 request 去模擬請求發現每次都會被攔截。因為拉勾在不登錄的情況下浏覽器也能獲取數據應該不是用戶級別的攔截,猜想可能是在 cookie 層面做的限制,發現請求沒有攜帶網站的 cookie 直接攔截
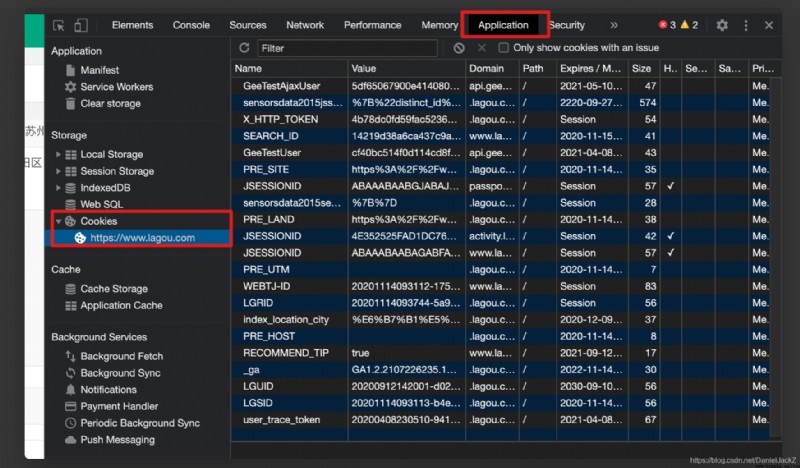
獲取請參數
def get_request_params(city, city_num):
req_url = 'https://www.lagou.com/jobs/list_{}/p-city_{}?&cl=false&fromSearch=true&labelWords=&suginput='.format(urllib.parse.quote(city), city_num)
ajax_url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(urllib.parse.quote(city))
headers = headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://www.lagou.com/jobs/list_{}/p-city_{}?px=default#filterBox".format(urllib.parse.quote(city), city_num),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
return req_url, ajax_url, headers
於是在 請求中加上 cookie, 代碼如下:
def get_cookie(city):
city_num = get_city_num_by_name(city)
req_url, _, headers = get_request_params(city, city_num)
s = requests.session()
s.get(req_url, headers=headers, timeout=3)
cookie = s.cookies
return cookie
雖然加入 cookie 後能獲取到數據但每次都是第一頁的數據且是固定職位的數據,當再次查看請求真實數據地址的鏈接發現請求中每次都會攜帶 query 參數如下:
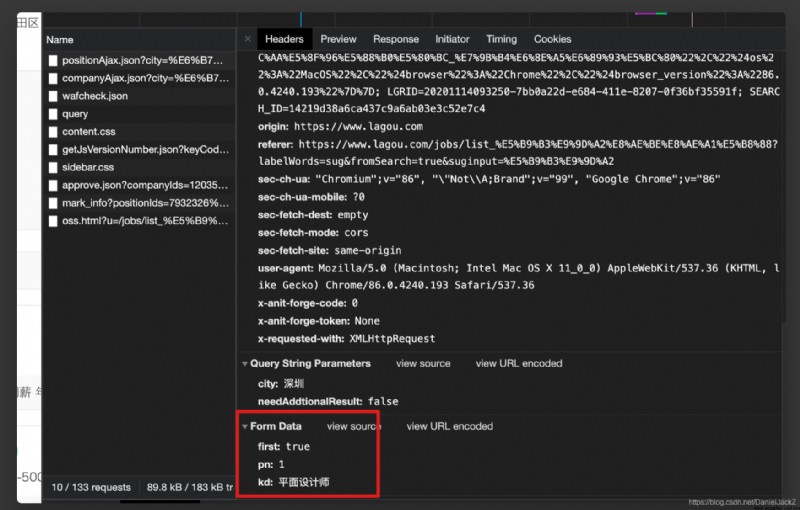
於是增加請求參數獲取:
def get_params(pn, kd):
return {
'first': 'true',
'pn': pn,
'kd': kd
}
雖然我們解決請求參數以及獲取頁面數,但是每次只能爬取固定城市的數據太僵硬啦,查找原因原來是我們在請求數據 url 中攜帶有 city_nun 這個參數,每個城市都有一個對應的數字
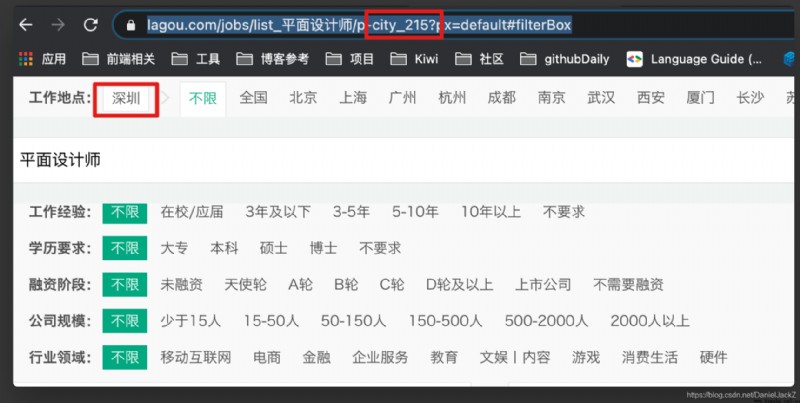
打開拉勾頁面源碼將頁面拉到最底部會發現 cityNumMap,查找到這個我們就能控制獲取想要的城市職位信息啦

import os
import json
import urllib
import requests
from cityNumMap import city_num_map
def validate_params(city, key_world):
if not city or not key_world:
raise Exception('輸入參數不能為空')
def get_city_num_by_name(city_name):
city_num = city_num_map.get(city_name)
if not city_name:
raise BaseException('>>>你輸入的城市名有誤,請確認後在重新輸入')
return city_num
def get_request_params(city, city_num):
req_url = 'https://www.lagou.com/jobs/list_{}/p-city_{}?&cl=false&fromSearch=true&labelWords=&suginput='.format(urllib.parse.quote(city), city_num)
ajax_url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(urllib.parse.quote(city))
headers = headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://www.lagou.com/jobs/list_{}/p-city_{}?px=default#filterBox".format(urllib.parse.quote(city), city_num),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
return req_url, ajax_url, headers
def get_params(pn, kd):
return {
'first': 'true',
'pn': pn,
'kd': kd
}
def get_cookie(city):
city_num = get_city_num_by_name(city)
req_url, _, headers = get_request_params(city, city_num)
s = requests.session()
s.get(req_url, headers=headers, timeout=3)
cookie = s.cookies
return cookie
def get_page_info(city, key_world):
params = get_params(1, key_world)
city_num = get_city_num_by_name(city)
_, ajax_url, headers = get_request_params(city, city_num)
html = requests.post(ajax_url, data=params, headers=headers, cookies=get_cookie(city), timeout=5)
result = json.loads(html.text)
total_count = result.get('content').get('positionResult').get('totalCount')
page_size = result.get('content').get('pageSize')
page_remainder = total_count % page_size
total_size = total_count // page_size
if page_remainder == 0:
total_size = total_size
else:
total_size = total_size + 1
print('>>>該職位總計{}條數據'.format(total_size))
return total_size
def get_page_data(city, key_world, total_size):
path = os.path.dirname(__file__)
path = os.path.join(path, 'lagou.txt')
f = open(path, mode='w+')
city_num = get_city_num_by_name(city)
_, ajax_url, headers = get_request_params(city, city_num)
for i in range(1, total_size):
print('>>>開始獲取第{}頁數據'.format(i))
params = get_params(i, key_world)
html = requests.post(ajax_url, data=params, headers=headers, cookies=get_cookie(city), timeout=5)
result = json.loads(html.text)
data = result.get('content').get('positionResult').get('result')
page_size = result.get('content').get('pageSize')
for i in range(page_size):
company_name = data[i].get('companyFullName')
company_size = data[i].get('companySize')
company_label = data[i].get('companyLabelList')
salary = data[i].get('salary')
education = data[i].get('education')
result_str = '{}&&{}&&{}&&{}&&{}\n'.format(company_name, company_size, company_label, salary, education)
f.write(result_str)
print('>>>數據獲取完成')
if __name__ == "__main__":
city = input('>>>請輸入你要搜索職位的城市:').strip()
kb = input('>>>請輸入你要搜索的職位:').strip()
validate_params(city, kb)
total_size = get_page_info(city, kb)
get_page_data(city, kb, total_size)
在本地執行 pythin3 lagou.py 輸入查找的地址以及職位會在當前同級目錄下生成 lagou.txt 文件存儲數據結果

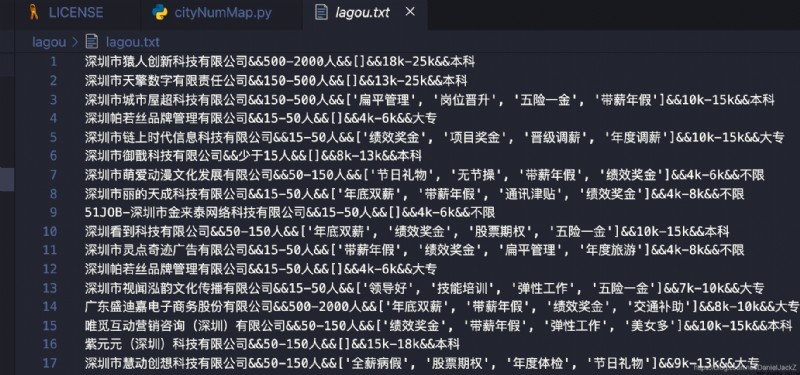
項目地址:完整代碼
 Python polynomial logistic regression for multi category classification and cross validation accuracy box graph visualization
Python polynomial logistic regression for multi category classification and cross validation accuracy box graph visualization
Link to the original text :htt
 The latest research is coming: the history of pandas eating bamboo may be traced back to 6million years ago
The latest research is coming: the history of pandas eating bamboo may be traced back to 6million years ago
In recent days, , The scientif