Some verification codes are in Chinese , When using, you may find , Chinese recognition is not supported , So how should we solve it ?
Let's take a look at what it looks like to recognize Chinese by default , For example, we need to identify the following figure :

Then we write the following code :
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
image = Image.open(r"C:\Users\22768\Desktop\gzh\chinese_0.jpg")
text = pytesseract.image_to_string(image, lang='eng+osd')
print(text)
Running results :
ffi’:
Lai Hun
Phalaenopsis
It can be seen that it is not recognized , It's garbled ;
python adopt tesseract Identify Chinese garbled codes of graphics , It's because you didn't choose Install in the appropriate language , In the previous article, we installed the next step by default , And the installed version is tesseract-ocr-setup-3.02.02.exe, This version can be installed in other languages , But you Can only choose , and No way to download . And there is no language support package for the corresponding version on the official website , So I found a new one here **5.1.0** Version of the package , There is no problem with this package ;
obtain tesseract The way of software package is :
WeChat official account “ Operation and maintenance home ”, The background to reply :resseract software package
Can get tesseract The network disk download address of the software package ;
tesseract During the installation of this software ,windows Installation path must be selected :
C:\Program Files (x86)\Tesseract-OCR
If it is windows Be sure to select the above path for installation ;
We can choose the language , Click on Additional language data(download) The symbol in front , Will show a lot of languages , If the identified content is complex , It is suggested to select all , Download all the language packs , I'm here to demonstrate , Only those related to Chinese are selected , That is to say, look up “Chinese” Of ;
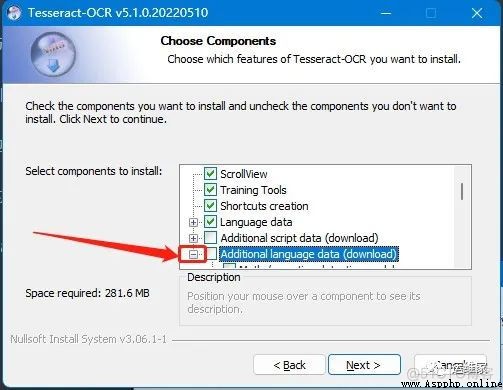
Then click next , Here we will see the following installation interface , It may be slower , Because he will download language packs one by one , Here we can wait patiently ;
The following interface indicates that the installation is successful ;
tesseract The software cannot download the language pack , perhaps tesseract download Language pack failed , If there is such a problem , Because of what ? That's easy , Because his language pack is abroad , Network instability Caused by , So how can we solve it , I have prepared a complete language pack here , Directly decompress and overwrite your resseract In the installation path tessdata This folder will do .
obtain tesseract 5.1.0 The way of language pack is :
WeChat official account “ Operation and maintenance home ”, The background to reply :tesseract Language pack
Can get tesseract The online download address of the language pack ;
Then we need to put C:\Program Files (x86)\Tesseract-OCR\tessdata All contents under this path are copied to C:\Program Files (x86)\Tesseract-OCR Below the table of contents, you can , Otherwise, the following information will be reported incorrectly :
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files (x86)\\Tesseract-OCR\\eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'eng\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
Let's take a look at how many languages he supports now ;
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
print(pytesseract.get_languages())
The operation results are as follows :
['chi_sim', 'chi_sim_vert', 'chi_tra', 'chi_tra_vert', 'eng', 'osd']
After using the language pack I provided above , You will find that there are so many supported languages :
['afr', 'amh', 'ara', 'asm', 'aze', 'aze_cyrl', 'bel', 'ben', 'bod', 'bos', 'bre', 'bul', 'cat', 'ceb', 'ces', 'chi_sim', 'chi_sim_vert', 'chi_tra', 'chi_tra_vert', 'chr', 'cos', 'cym', 'dan', 'deu', 'div', 'dzo', 'ell', 'eng', 'enm', 'epo', 'equ', 'est', 'eus', 'fao', 'fas', 'fil', 'fin', 'fra', 'frk', 'frm', 'fry', 'gla', 'gle', 'glg', 'grc', 'guj', 'hat', 'heb', 'hin', 'hrv', 'hun', 'hye', 'iku', 'ind', 'isl', 'ita', 'ita_old', 'jav', 'jpn', 'jpn_vert', 'kan', 'kat', 'kat_old', 'kaz', 'khm', 'kir', 'kmr', 'kor', 'lao', 'lat', 'lav', 'lit', 'ltz', 'mal', 'mar', 'mkd', 'mlt', 'mon', 'mri', 'msa', 'mya', 'nep', 'nld', 'nor', 'oci', 'ori', 'osd', 'pan', 'pol', 'por', 'pus', 'que', 'ron', 'rus', 'san', 'sin', 'slk', 'slv', 'snd', 'spa', 'spa_old', 'sqi', 'srp', 'srp_latn', 'sun', 'swa', 'swe', 'syr', 'tam', 'tat', 'tel', 'tgk', 'tha', 'tir', 'ton', 'tur', 'uig', 'ukr', 'urd', 'uzb', 'uzb_cyrl', 'vie', 'yid', 'yor']
At this time, let's identify the pictures at the beginning of the article again , Let's see if we can recognize it .
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
image = Image.open(r"C:\Users\22768\Desktop\gzh\1654881934269.jpg")
text = pytesseract.image_to_string(image, lang='chi_sim+chi_sim_vert+chi_tra+chi_tra_vert')
print(text)
The operation results are as follows :
Operation and maintenance home
So let's try again to identify a picture with more characters , for example :
Run code
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
image = Image.open(r"C:\Users\22768\Desktop\gzh\1654882172968.jpg")
text = pytesseract.image_to_string(image, lang='chi_sim+chi_sim_vert+chi_tra+chi_tra_vert')
print(text)
result :
The wind and rain in Zhongshan have made moss , Thousands of heroes cross the river .
The tiger and the dragon are suffering today , Earth shaking and generous .
Second, the remaining tendons will catch up with the poor flat , Don't sell your name and wait for the king .
Heaven swallows love and heaven sets the old , The right path in the world is the right one .
Inevitably there are some typos , But there are few .
thus , In this paper, the end . Relevant contents are updated daily .
For more information, go to VX official account “ Operation and maintenance home ” , Get the latest article .
------ “ Operation and maintenance home ” ------
------ “ Operation and maintenance home ” ------
------ “ Operation and maintenance home ” ------
linux Under the system ,mknodlinux,linux Directory write permission , Chinese cabbage can be installed linux Do you ,linux How the system creates files , Led the g linux How to install software in the system ,linux Text positioning ;
ocr distinguish linux,linux Anchoring suffix ,linux System usage records ,u Dish has linux Image file , Fresh students will not Linux,linux kernel 64 position ,linux Self starting management service ;
linux Calculate folder size ,linux What are the equipment names ,linux Can I use a virtual machine ,linux The system cannot enter the command line , How to create kalilinux,linux Follow so Are the documents the same .