關於數據抓取之xpath提取text為空問題的原因和解決方案
今天在抓取淘寶網網頁的時候,使用了:
- #店名
- shopname = driver.find_element_by_xpath(".//*[@id='page']/div[2]/div/div[2]/ul/li[1]/a/span").text.strip()
- #掌櫃名
- dealername = driver.find_element_by_xpath("./html/head/title").text.strip()
- dealername = dealername[dealername.find('-')+1:dealername.rfind('-')]
對於xpath,當然好用,畢竟Firefox和Chrome可以自動生成,所以爬蟲開發的速度會更快。然而,得到的結果很驚訝,全部為空。我突然之間陷入了迷惑,不可能是因為版本的問題吧,畢竟selenium已經這麼成熟了。下午試了很多次,都是無功而返,我非常沮喪。
晚上繼續,首先要找到問題出在什麼地方。使用page_source查看,發現網頁代碼一應俱全。難道是非得把鼠標移動到特定位置,彈出菜單激活Js?於是使用:
- driver.get('https://shop594784981.taobao.com')
- time.sleep(3)
- menu = driver.find_element_by_xpath("//*[@id='header-content']/div[2]/p/span[1]/span[1]/a")
- ActionChains(driver).move_to_element(menu).perform()
- time.sleep(2)
彈出了隱含層,又如何呢,還是不行啊。~~~接著再嘗試,試試其他
- print(driver.find_element_by_id("J_TEnterShop").text)
使用ID就可以了。然後,我就非常仔細地觀察了ID這塊的HTML結構特點,發現確實和之前要抓的結構不一樣。接著我又試了一下這個Id的xpath,順利提取。看來不是text方法的問題,也不是xpath的問題。而是結構的問題,對於xpath能提取什麼樣的結構我之前是沒有弄清楚,現在舉例說明一下:
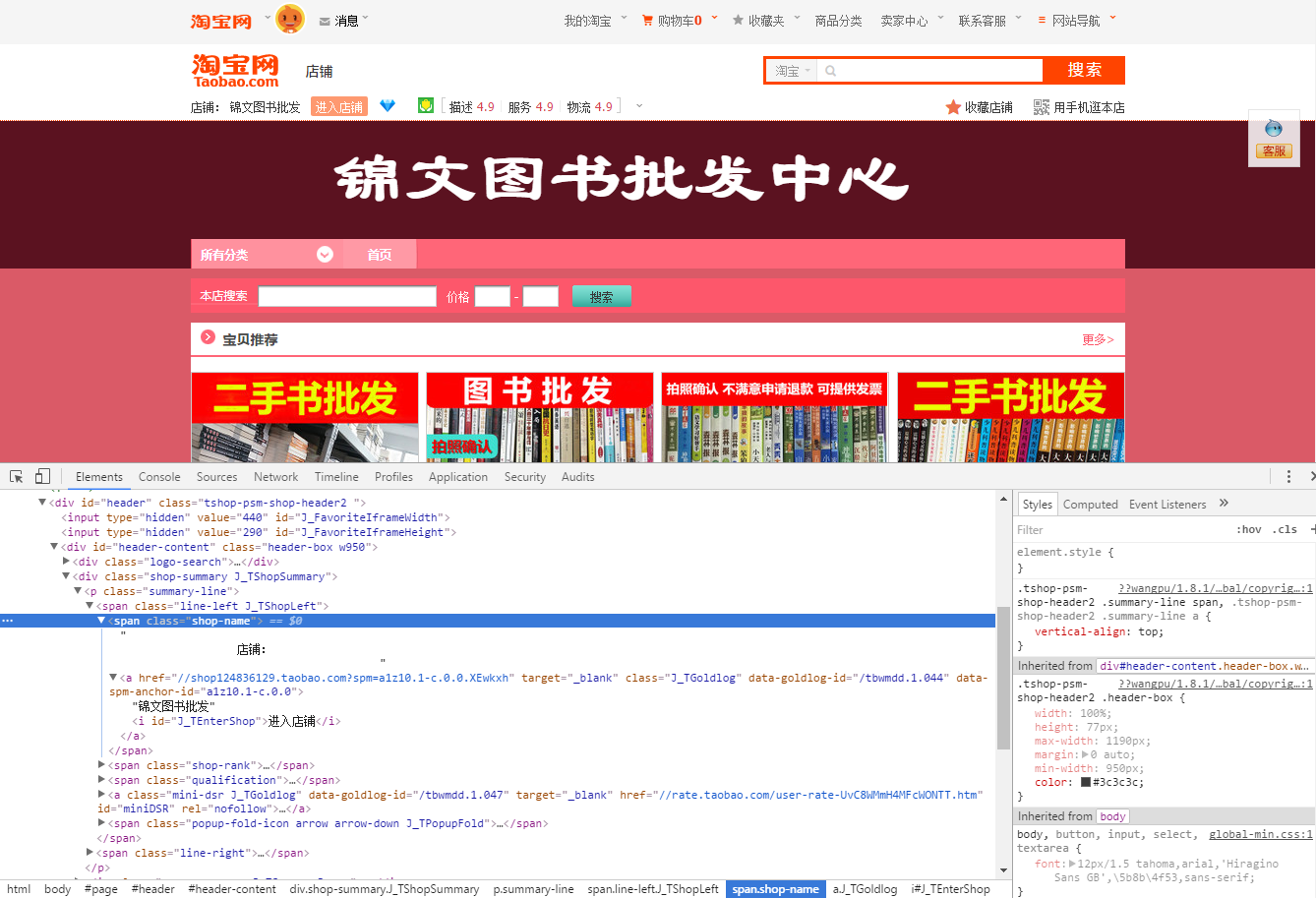
- <span class="shop-name">
- 店鋪:
- <a href="//shop124836129.taobao.com?spm=a1z10.1-c.0.0.XEwkxh" target="_blank" class="J_TGoldlog" data-goldlog-id="/tbwmdd.1.044" data-spm-anchor-id="a1z10.1-c.0.0">錦文圖書批發<i id="J_TEnterShop">進入店鋪</i></a>
- </span>
我只想提取店鋪名稱,但店鋪名稱在XX
YY結構中,目標是XX,使用xpath提取的XX路徑使用text提取的結果是空。但YY的xpath提取則是“進入店鋪”,使用整個a鏈接的xpath是“錦文圖書批發進入店鋪”。所以xpath看來要使用標簽封閉結構才行。
那麼問題來了,怎麼提取“錦文圖書批發”呢?
有兩種方法,一是換一個具有“錦文圖書批發”的地方提取,二是使用XXYY - YY的方式。