一、概述
WeakHashMap是Map的一種,根據其類的命令可以知道,它結合了WeakReference和HashMap的兩種特點,從而構造出了一種Key可以自動回收的Map。
前面我們已經介紹了WeakReference的特點及實現原理,以及HashMap的實現原理,所以我們本文重點介紹WeakReference的在這類Map中的使用,以及其和原來的HashMap有什麼不一樣的地方。
二、實現原理分析
還是按之前的方式,我們從幾個方面去分析Map的具體實現。
1. 初始化
WeakHashMap和普通的HashMap的初始化方式類似,可以指定初始容量和加載因子,若不指定則使用默認值,也可以用一個現有的Map來填充,如下:

第一個構造函數的實現方式如下:
public WeakHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Initial Capacity: "+
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load factor: "+
loadFactor);
int capacity = 1;
//找到一個最合適的大小
while (capacity < initialCapacity)
capacity <<= 1;
table = newTable(capacity);
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
}
從上面的實現來看沒有什麼特別的,就是根據參數來計算了實際的容量和阈值。
2. 添加元素
和前幾篇一樣,我們還是來看下put的實現:
1 public V put(K key, V value) {
2 Object k = maskNull(key);
3 int h = hash(k);
4 Entry<K,V>[] tab = getTable();
5 int i = indexFor(h, tab.length);
6
7 for (Entry<K,V> e = tab[i]; e != null; e = e.next) {
8 if (h == e.hash && eq(k, e.get())) {
9 V oldValue = e.value;
10 if (value != oldValue)
11 e.value = value;
12 return oldValue;
13 }
14 }
15
16 modCount++;
17 Entry<K,V> e = tab[i];
18 tab[i] = new Entry<>(k, value, queue, h, e);
19 if (++size >= threshold)
20 resize(tab.length * 2);
21 return null;
22 }
這段代碼大體上看來,和HashMap的實現是差不多的,為了更好的便於對於,我們把HashMap裡的相關實現也貼出來:
1 public V put(K key, V value) {
2 if (table == EMPTY_TABLE) {
3 inflateTable(threshold);
4 }
5 if (key == null)
6 return putForNullKey(value);
7 int hash = hash(key);
8 int i = indexFor(hash, table.length);//table中的位置
9 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
10 Object k;
11
12 //entry相同的條件 , hash相同 , key的引用相同,或者equals()
13 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
14 V oldValue = e.value;
15 e.value = value;
16 e.recordAccess(this);
17 return oldValue;
18 }
19 }
20
21 modCount++;
22
23 //新增
24 addEntry(hash, key, value, i);
25 return null;
26 }
接下來,我們先總結一下有哪些主要的區別,然後再詳細分析WeakHashMap為什麼要這樣做。
通過對比代碼,我們得知主要的區別如下:
1)WeakHashMap沒有空表判斷:這個很好理解,因為初始化時就已經創建了Entry數組,所以沒必要判斷空表
2)對key進行了maskNull封裝:由於這個實現比較簡單就不貼代碼了,前面我們也介紹過maskNull的用法,主要用在那些原生的null表示不存在,但又需要支持null值的場合下,也就是說,用一個特殊的“null”,來代表對於空指針key的支持。因為WeakHashMap中的key是弱引用構造的,作為弱引用的引用對象,其自身是不能為null的。
3)沒有直接使用table,而是使用了getTable(): 這個下面詳細解釋
4)使用了eq()來判斷,且使用e.get()來獲取key: 這個也好理解,弱引用對象就是通過get()方法來獲取其所引用的對象,這裡的key就是其引用對象。
5)在創建一個新的Entry時,多了一個queue的參數:這個queue的類型為ReferenceQueue類型,前面我們介紹過,這個是用於存儲引用目標已經被回收的那些弱引用。
經過上面的分析,我們發現其它的都比較好懂,就是不清楚getTable()都做了些什麼事,下面看一下其源碼實現:
1 private Entry<K,V>[] getTable() {
2 expungeStaleEntries();
3 return table;
4 }
5
6
7 /**
8 * 根據英文的解釋,移除陳舊的數據
9 * 這個方法的具體實際其實比較簡單,就是將遍歷隊列中的每一個元素,這個元素就是一個entry,
10 * 在內部數組中找到它,並將其移除,移除比較簡單,就是將值置為空.
11 *
12 * 那麼通過這個反推,queue裡面存儲的就是所有失效的key了.
13 * Expunges stale entries from the table.
14 */
15 private void expungeStaleEntries() {
16 for (Object x; (x = queue.poll()) != null; ) {
17 synchronized (queue) {
18 @SuppressWarnings("unchecked")
19 Entry<K,V> e = (Entry<K,V>) x;//it's a entry
20 int i = indexFor(e.hash, table.length);
21
22 Entry<K,V> prev = table[i];
23 Entry<K,V> p = prev;
24 while (p != null) {
25 Entry<K,V> next = p.next;
26 if (p == e) {
27 if (prev == e)
28 table[i] = next;
29 else
30 prev.next = next;
31 // Must not null out e.next;
32 // stale entries may be in use by a HashIterator
33 e.value = null; // Help GC
34 size--;
35 break;
36 }
37 prev = p;
38 p = next;
39 }
40 }
41 }
42 }
上面的代碼是一個雙重循環,看似復雜,但如果了解了queue的定義,我們理解起來也就方便了。前面提到queue裡存儲的是一些弱引用實例,它們共同的特點是其引用目標已經被垃圾回收器回收。
在這個大前提下,這段代碼做了以下幾件事:
1)依次取出queue中的所有元素進行處理直到queue為空
2)每個出隊的元素都是map中的一個entity,所以可以根據其hash值找到對應的存儲位置。
3)判斷entity的位置,根據其是否為散列表的表頭來決定怎麼將其從列表中移除了,當然,由於其key已經被回收,所以只需將其value置為null即可。
4)處理完畢後,表示存儲中少了一個entity,size-1
所以這個方法就是完成了對於WeakHashMap的自動回收元素的處理,如果不這樣處理則仍然有內存洩露的風險,另外大小也就不准確了。這個方法是典型的對於弱引用失效隊列的監控和處理,值得學習。
3. 刪除
刪除的方法如下:
1 public V remove(Object key) {
2 Object k = maskNull(key);
3 int h = hash(k);
4 Entry<K,V>[] tab = getTable();
5 int i = indexFor(h, tab.length);
6 Entry<K,V> prev = tab[i];
7 Entry<K,V> e = prev;
8
9 while (e != null) {
10 Entry<K,V> next = e.next;
11 if (h == e.hash && eq(k, e.get())) {
12 modCount++;
13 size--;
14 if (prev == e)
15 tab[i] = next;
16 else
17 prev.next = next;
18 return e.value;
19 }
20 prev = e;
21 e = next;
22 }
23
24 return null;
25 }
可見刪除方法的邏輯也跟之前的HashMap差不多,惟一變化的就是在table的獲取上使用了getTable(), 而這個方法我們前面已經介紹了。
如果有興趣,還可以再看下其它的處理方法,基本上所有的操作都會先執行getTable(),來對自動失效的key進行相應的清理。在此就不一一分析。
另外我們可以看到Entity實際上就是一個弱引用對象,其引用的目標為key, 代碼截圖如下:
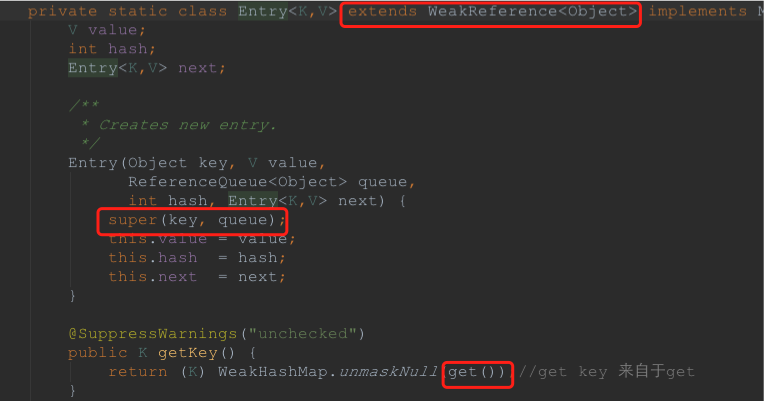
至此,對於WeakHashMap的實現原理便一目了然了。
三、總結
WeakHashMap由於其弱引用的特點,使得其非常適合用於做緩存的存儲結構,這樣當緩存中的數據不再使用之後,垃圾回收器可以自動回收,從而實現不需要人工干預且能自動釋放內存的效果。
同時,這也是一個學習如何使用弱引用的很好的例子。