一、項目中搭配使用SVN和Git
安裝SVN;安裝熟悉Git;安裝maven,修改setting.xml文件;安裝eclipse,配置jdk、maven路徑;
建立自己的Git倉庫,熟悉常用的Git命令。熟悉基本Linux命令。ssh登錄線上環境,查看日志。
// #拷貝並跟蹤遠程的master分支。跟蹤的好處是以後可以直接通過pull和push命令來提交或者獲取遠程最新的代碼,而不需要指定遠程分支名字 // git clone //#創建名為branchName的branch //git brach branchName //#切換到branchName的branch //git checkout branchName
二、項目啟動(antx、Autoconfig、JVM參數)
antx中部分配置項依賴於本機環境,要做出修改。antx.properties文件的作用存儲所有placeholders的值,作為AutoConfig的輸入,使配置與代碼隔離。當更換環境時只需要更改antx.properties,方便集中式管理所有變量,讓一套代碼適用多個環境。
在一個項目之中,總會有一些參數在開發環境和生產環境是不同的,或者會根據環境的變化而變化。我們如果通過硬編碼的方式,勢必要經常性的修改項目代碼。那我們可以用一種方式,在項目編譯前將可變的參數改為可配置的。如此,靈活性就大大的增加,也減少了經常修改代碼可能帶來的不穩定風險。Autoconfig就是這樣的一個工具,它通過占位符將需要動態配置的內容替換。核心思想是把一些可變的配置定義為一個模板,在autoconfig運行的時候從這些模板中生成具體的配置文件。AutoConfig不需要提取源碼,也不需要重新build,即可改變目標文件中所有配置文件中placeholders的值,AutoConfig可以對placeholder及其值進行檢查。
解釋下:autoconfig為什麼不需要提取源碼就可以改變目標文件中的待替換值。觀察Ali-Tomcat的啟動流程,我們可以發現,Ali-Tomcat在Tomcat基本組件啟動完全之後,部署項目之前會再次去尋找項目中的auto-config.xml文件,然後完成對placeholder的再次替換,autoconfig的這種優勢是依賴於Ali-Tomcat的,從服務器的啟動日志就可以看出。上圖為Ali-Tomcat的啟動日志。
JVM性能調優過程,也就是修改上述參數的配置文件,如下圖所示,永久代的內存不夠,需要增大PermGen的空間,進行 jvm 參數設置:-Xms512m -Xmx1024m -XX:PermSize=128m -XX:MaxPermSize=256M -Dfile.encoding=UTF-8。JVM各參數的含義上圖。
三、maven學習
什麼是pom,pom作為項目對象模型。通過xml表示maven項目,使用pom.xml來實現。POM包括了所有的項目信息:groupId:項目或者組織的唯一標志,並且配置時生成路徑也是由此生成,如org.myproject.mojo生成的相對路徑為:/org/myproject/mojo。artifactId:項目的通用名稱。version:項目的版本。packaging:打包機制,如pom,jar,maven-plugin,ejb,war,ear,rar,par。
pom繼承關系:要繼承pom就需要有一個父pom,在Maven中定義了超級pom.xml,任何沒有申明自己父pom.xml的pom.xml都將默認繼承自這個超級pom.xml。(項目分級)子pom.xml會完全繼承父pom.xml中所有的元素,而且對於相同的元素,一般子pom.xml中的會覆蓋父pom.xml中的元素,但是有幾個特殊的元素它們會進行合並而不是覆蓋。這些特殊的元素是:dependencies,developers,contributors,plugin列表,resources。當需要繼承指定的一個Maven項目時,我們需要在自己的pom.xml中定義一個parent元素,在這個元素中指明需要繼承項目的groupId、artifactId和version。當被繼承項目與繼承項目的目錄結構不是父子關系的時候,這個時候就需要在子項目的pom.xml文件定義中的parent元素下再加上一個relativePath元素的定義,用以描述父項目的pom.xml文件相對於子項目的pom.xml文件的位置。
pom聚合關系:說說我對聚合和被聚合的理解,比如說如果projectA聚合到projectB,那麼我們就可以說projectA是projectB的子模塊, projectB是被聚合項目,也可以類似於繼承那樣稱為父項目。對於聚合而言,這個主體應該是被聚合的項目。所以,我們需要在被聚合的項目中定義它的子模塊,而不是像繼承那樣在子項目中定義父項目。具體做法是:修改被聚合項目的pom.xml中的packaging元素的值為pom;在被聚合項目的pom.xml中的modules元素下指定它的子模塊項目。如果子模塊projectB是處在被聚合項目projectA的子目錄下,即與被聚合項目的pom.xml處於同一目錄。這裡使用的module值是子模塊projectB對應的目錄名projectB,而不是子模塊對應的artifactId。這個時候當我們對projectA進行mvn package命令時,實際上Maven也會對projectB進行打包。當被聚合項目與子模塊項目在目錄結構上不是父子關系的時候,需要在module元素中指定以相對路徑的方式指定子模塊。以plutus-web根目錄下的pom為例:
注意:如果有A,B,C三個子工程,並且install的順序是A,B,C,這樣要是A依賴B的話,執行mvn clean install必然報錯,因為install A的時候,B還沒有生成,所以我們在寫modules的時候一定要注意順序。如果projectB繼承projectA,同時需要把projectB聚合到projectA,projectA的pom.xml中需要定義它的packaging為pom,需要定義它的modules,同時在projectB的pom.xml文件中新增一個parent元素,用以定義它繼承的項目信息。
pom依賴關系,項目之間的依賴是通過pom.xml文件裡面的dependencies元素下面的dependency元素進行的。一個dependency元素定義一個依賴關系。在dependency元素中我們主要通過依賴項目的groupId、artifactId和version來定義所依賴的項目。
setting.xml一般存在與兩個地方:maven的安裝目錄/conf/,和/.m2/下。他們的區別是在maven安裝目錄下的setting.xml是所有用戶都可以應用的配置,而user.home下的是針對某一用戶的配置(推薦是在user.home下)。如果兩個都進行了配置,則在應用的時候會將兩個配置文件進行中和,而且user.home下的setting.xml優先級大於maven安裝目錄下的。
maven中的snapshot快照倉庫,maven中的倉庫分為兩種,snapshot快照倉庫和release發布倉庫。snapshot快照倉庫用於保存開發過程中的不穩定版本,release正式倉庫則是用來保存穩定的發行版本。在使用maven過程中,我們在開發階段經常性的會有很多公共庫處於不穩定狀態,隨時需要修改並發布,可能一天就要發布一次,遇到bug時,甚至一天要發布N次。maven的依賴管理是基於版本管理的,對於發布狀態的artifact,如果版本號相同,即使我們內部的鏡像服務器上的組件比本地新,maven也不會主動下載的。如果我們在開發階段都是基於正式發布版本來做依賴管理,那麼遇到這個問題,就需要升級組件的版本號,可這樣就明顯不符合要求和實際情況了。如果是基於快照版本,那麼問題就自熱而然的解決了,maven2會根據模塊的版本號(pom文件中的version)中是否帶有-SNAPSHOT來判斷是快照版本還是正式版本。如果是快照版本,那麼在mvn deploy時會自動發布到快照版本庫中,而使用快照版本的模塊,在不更改版本號的情況下,直接編譯打包時,maven會自動從鏡像服務器上下載最新的快照版本。如果是正式發布版本,那麼在mvn deploy時會自動發布到正式版本庫中,而使用正式版本的模塊,在不更改版本號的情況下,編譯打包時如果本地已經存在該版本的模塊則不會主動去鏡像服務器上下載。所以,我們在開發階段,可以將公用庫的版本設置為快照版本,而被依賴組件則引用快照版本進行開發,在公用庫的快照版本更新後,我們也不需要修改pom文件提示版本號來下載新的版本,直接mvn執行相關編譯、打包命令即可重新下載最新的快照庫了,從而也方便了我們進行開發。
maven的仲裁機制。maven自己的仲裁機制是先看路徑長度,路徑長度一樣再看聲明順序。
四、Socket
socket,通常也稱作"套接字",用於描述IP地址和端口,是網絡上運行的兩個程序間雙向通訊的一端,它既可以接受請求,也可以發送請求,利用它可以較為方便的編寫網絡上的數據的傳遞。Socket通訊過程:服務端監聽某個端口是否有連接請求,客戶端向服務端發送連接請求,服務端收到連接請求向客戶端發出接收消息,這樣一個連接就建立起來了。客戶端和服務端都可以相互發送消息與對方進行通訊。
Socket編程中的重要方法,Accept方法用於產生”阻塞”,直到接受到一個連接,並且返回一個客戶端的Socket對象實例。getInputStream方法獲得網絡連接輸入,即一個輸入流,同時返回一個IutputStream對象實例,客戶端的Socket對象上的 getInputStream方法得到的輸入流其實就是從服務器端發回的數據流;服務器端的輸入流就是接受客戶端發來的數據流。getOutputStream方法實現一個輸出流,同時返回一個OutputStream對象實例。客戶端的輸出流就是將要發送到服務器端的數據流,服務器端的輸出流就是發給客戶端的數據流。注意:getInputStream和getOutputStream方法均會產生一個IOException,它必須被捕獲;getInputStream和getOutputStream方法返回的是流對象,通常都會被另一個流對象使用。所以還要對這兩種方法獲取的數據進行封裝,以便更方便的使用。
單線程代碼有一個問題,就是Server只能接受一個Client請求,當第一個Client連接後就占據了這個位置,後續Client不能再繼續連接。所以需要做些改動,當Server每接受到一個Client連接請求之後,都把處理流程放到一個獨立的線程裡去運行,然後等待下一個Client連接請求,這樣就不會阻塞Server端接收請求了。每個獨立運行的程序在使用完Socket對象之後要將其關閉。改進後的代碼同樣在上面的git地址。
五、並發編程學習(線程之間的互斥和同步)
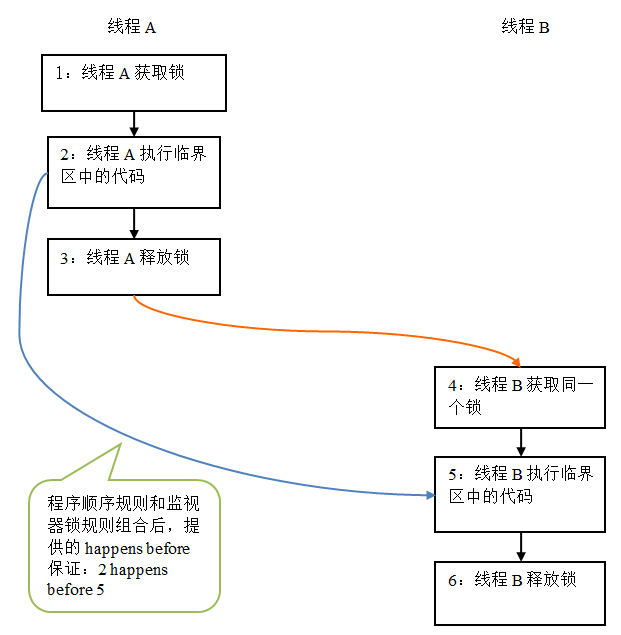
synchronized鎖重入,關鍵字synchronized擁有鎖重入的功能。也就是在使用synchronized時,當一個線程得到一個對象鎖後,再次請求此對象鎖時,是可以再次得到該對象的鎖的。所以在一個synchronized方法/塊的內部調用本類的其他synchronized方法/塊時,是永遠可以得到鎖的。可重入鎖就是自己可以再次獲取自己的內部鎖,當存在父子類繼承關系時,子類是完全可以通過“可重入鎖”調用父類的同步方法的。
synchronized同步語句塊,對其他synchronized同步方法或者synchronized(this)同步代碼塊調用呈阻塞狀態。同一時間只有一個線程可以執行synchronized同步方法中的代碼。
synchronized(非this對象x),當多個線程同時執行synchronized(x){}同步代碼塊時呈同步效果;當其他線程執行x對象中synchronized同步方法時呈同步效果;當其他線程執行x對象方法裡面的synchronized(this)代碼塊時也呈現同步效果;但是如果其他線程調用不加synchronized關鍵字的方法時,還是異步調用。
synchronized與volatile比較,volatile性能比synchronized要好,並且volatile只能修飾於變量,而synchronized可以修飾方法,以及代碼塊。多線程訪問volatite不會發生阻塞,而synchronized會出現阻塞。volatite能保證數據的可見性,但不能保證原子性;而synchronized可以保證原子性,也可以間接保證可見性,因為它會將私有內存和公共內存中的數據做同步。volatite解決的是變量在多個線程之間的可見性;而synchronized關鍵字解決的是多個線程之間訪問資源的同步性。volatite提示線程每次從共享內存中讀取變量,而不是從私有內存中讀取,這樣就保證了同步數據的可見性。
Lock接口最大的優勢是為讀和寫分別提供了鎖,讀寫鎖ReadWriteLock擁有更加強大的功能,它可細分為讀鎖和寫鎖。讀鎖可以允許多個進行讀操作的線程同時進入,但不允許寫進程進入;寫鎖只允許一個寫進程進入,在這期間任何進程都不能再進入。
ReentrantLock是一個可重入的互斥鎖 Lock,它具有與使用 synchronized 方法和語句所訪問的隱式監視器鎖相同的一些基本行為和語義,但功能更強大。ReentrantLock 將由最近成功獲得鎖,並且還沒有釋放該鎖的線程所擁有。當鎖沒有被另一個線程所擁有時,調用lock的線程將成功獲取該鎖並返回。如果當前線程已經擁有該鎖,此方法將立即返回。可以使用isHeldByCurrentThread()和getHoldCount()方法來檢查此情況是否發生。
Condition 將Object監視器方法(wait、notify 和 notifyAll)分解成截然不同的對象,以便通過將這些對象與任意 Lock 實現組合使用,為每個對象提供多個等待集合。其中,Lock 替代了 synchronized 方法和語句的使用,Condition 替代了 Object 監視器方法的使用。Condition實例實質上被綁定到一個鎖上。要為特定Lock實例獲得Condition實例,請使用其newCondition()方法。
ReentrantReadWriteLock,可重入讀寫鎖。它實現ReadWriteLock接口,此鎖允許 reader 和 writer 按照 ReentrantLock 的樣式重新獲取讀取鎖或寫入鎖。在寫入線程保持的所有寫入鎖都已經釋放後,才允許重入 reader 使用它們。鎖降級:重入還允許從寫入鎖降級為讀取鎖,其實現方式是:先獲取寫入鎖,然後獲取讀取鎖,最後釋放寫入鎖。但是,從讀取鎖升級到寫入鎖是不可能的。它對Condition的支持。寫入鎖提供了一個 Condition 實現,對於寫入鎖來說,該實現的行為與 ReentrantLock.newCondition() 提供的 Condition 實現對 ReentrantLock 所做的行為相同。當然,此 Condition 只能用於寫入鎖。讀取鎖不支持 Condition,readLock().newCondition() 會拋出 UnsupportedOperationException。
六、線程間的通信
wait()方法,wait()的作用是使當前執行代碼的線程進行等待,當前線程釋放鎖。調用之前線程必須獲得該對象的對象鎖。
notify()方法,不會使當前線程馬上釋放對象鎖,呈wait()狀態的的線程也不能馬上獲取該對象的對象鎖,要等到執行notify()方法的線程將程序執行完,退出synchronized代碼塊後才會釋放鎖。
notifyALL()方法,可以使所有正在等待隊列中等待同意共享資源的全部線程從等待狀態退出,進入可運行狀態。
wait和sleep方法的不同,這兩個方法來自不同的類分別是,sleep來自Thread類靜態方法,和wait來自Object類成員方法。(sleep是Thread的靜態類方法,誰調用的誰去睡覺,即使在a線程裡調用了b的sleep方法,實際上還是a去睡覺,要讓b線程睡覺要在b的代碼中調用sleep。)最主要是sleep方法沒有釋放鎖,而wait方法釋放了鎖,使得其他線程可以使用同步控制塊或者方法。(sleep不出讓系統資源;wait是進入線程等待池等待,出讓系統資源,其他線程可以占用CPU。一般wait不會加時間限制,因為如果wait線程的運行資源不夠,再出來也沒用,要等待其他線程調用notify/notifyAll喚醒等待池中的所有線程,才會進入就緒隊列等待OS分配系統資源。sleep(milliseconds)可以用時間指定使它自動喚醒過來,如果時間不到只能調用interrupt()強行打斷。)Thread.Sleep(0)的作用是“觸發操作系統立刻重新進行一次CPU競爭”。使用范圍:wait,notify和notifyAll只能在同步控制方法或者同步控制塊裡面使用,而sleep可以在任何地方使用。sleep必須捕獲異常(InterruptedException),而wait,notify和notifyAll不需要捕獲異常。總結:最大的不同是在等待時wait會釋放鎖,而sleep一直持有鎖。Wait通常被用於線程間交互,sleep通常被用於暫停執行。
join()的作用是使所屬的線程對象x正常執行run()方法中的任務,而使當前線程z進行無限期的阻塞,等待線程x銷毀後再繼續執行線程z後面的代碼。方法join具有使線程排隊運行的作用類似於同步的運行效果。join與synchronized的區別是:join在內部使用wait()方法進行等待(所以具有釋放鎖的特點),而synchronized關鍵字使用的是“對象監視器”原理作為同步。
生產者消費者,操作棧List實現,List最大容量是1,解決wait條件改變與假死,多生產者多消費者實現。
七、線程池
為什麼使用線程池?線程啟動一個新線程的成本是比較高的,因為它涉及與操作系統交互,在這種情形下,使用線程池可以很好的提高性能,尤其是當程序中需要創建大量生存期很短暫的線程時,更應該考慮使用線程池。線程池在系統啟動時即創建大量空閒的線程,程序將一個Runnable對象傳給線程池,線程池就會啟動一條線程來執行該對象的run()方法,當run()方法執行結束後,該線程並不會死亡,而是再次返回線程池中成為空閒狀態,等待執行下一個Runnable對象的run方法。使用線程池可以有效地控制系統中並發線程的數量,當系統中包含大量並發線程時,會導致系統性能劇烈下降,甚至導致JVM崩潰,而線程池的最大線程數參數可以控制系統中並發線程數目不超過此數目。
ThreadPoolExecutor重要參數,corePoolSize:核心池的大小,這個參數跟後面講述的線程池的實現原理有非常大的關系。在創建了線程池後,默認情況下,線程池中並沒有任何線程,而是等待有任務到來才創建線程去執行任務,除非調用了prestartAllCoreThreads()或者prestartCoreThread()方法,從這2個方法的名字就可以看出,是預創建線程的意思,即在沒有任務到來之前就創建corePoolSize個線程或者一個線程。默認情況下,在創建了線程池後,線程池中的線程數為0,當有任務來之後,就會創建一個線程去執行任務,當線程池中的線程數目達到corePoolSize後,就會把到達的任務放到緩存隊列當中。maximumPoolSize:線程池最大線程數,這個參數也是一個非常重要的參數,它表示在線程池中最多能創建多少個線程。keepAliveTime:表示線程沒有任務執行時最多保持多久時間會終止。默認情況下,只有當線程池中的線程數大於corePoolSize時,keepAliveTime才會起作用,直到線程池中的線程數不大於corePoolSize,即當線程池中的線程數大於corePoolSize時,如果一個線程空閒的時間達到keepAliveTime,則會終止,直到線程池中的線程數不超過corePoolSize。但是如果調用了allowCoreThreadTimeOut(boolean)方法,在線程池中的線程數不大於corePoolSize時,keepAliveTime參數也會起作用,直到線程池中的線程數為0。
對參數的個人理解:如果當前線程池中的線程數目小於corePoolSize,則每來一個任務,就會創建一個線程去執行這個任務。當前線程池中的線程數目>=corePoolSize,則每來一個任務,會嘗試將其添加到任務緩存隊列當中,若添加成功,則該任務會等待空閒線程將其取出去執行;若添加失敗(一般來說是任務緩存隊列已滿),則會嘗試創建新的線程去執行這個任務。如果當前線程池中的線程數目達到maximumPoolSize,則會采取任務拒絕策略進行處理。如果線程池中的線程數量大於 corePoolSize時,如果某線程空閒時間超過keepAliveTime,線程將被終止,直至線程池中的線程數目不大於corePoolSize;如果允許為核心池中的線程設置存活時間,那麼核心池中的線程空閒時間超過keepAliveTime,線程也會被終止。
ThreadPoolExecutor的重要方法,execute()方法實際上是Executor中聲明的方法,在ThreadPoolExecutor進行了具體的實現,這個方法是ThreadPoolExecutor的核心方法,通過這個方法可以向線程池提交一個任務,交由線程池去執行。submit()方法是在ExecutorService中聲明的方法,在AbstractExecutorService就已經有了具體的實現,在ThreadPoolExecutor中並沒有對其進行重寫,這個方法也是用來向線程池提交任務的,但是它和execute()方法不同,它能夠返回任務執行的結果,去看submit()方法的實現,會發現它實際上還是調用的execute()方法,只不過它利用了Future來獲取任務執行結果。shutdown()和shutdownNow()是用來關閉線程池的。
// #shutdown()和shutdownNow()區別: // shutdown():不會立即終止線程池,而是要等所有任務緩存隊列中的任務都執行完後才終止,但再也不會接受新的任務 // shutdownNow():立即終止線程池,並嘗試打斷正在執行的任務,並且清空任務緩存隊列,返回尚未執行的任務
BlockingQueue,阻塞隊列(BlockingQueue)是一個支持兩個附加操作的隊列。這兩個附加的操作是:在隊列為空時,獲取元素的線程會等待隊列變為非空。當隊列滿時,存儲元素的線程會等待隊列可用。 阻塞隊列常用於生產者和消費者的場景,生產者是往隊列裡添加元素的線程,消費者是從隊列裡拿元素的線程。阻塞隊列就是生產者存放元素的容器,而消費者也只從容器裡拿元素。用wait和notify實現阻塞隊列;用ReentrantLock實現阻塞隊列。
靜態方法上synchronzied和非靜態方法上synchronized關鍵字的區別是什麼?在使用synchronized塊來同步方法時,非靜態方法可以通過this來同步,而靜態方法必須使用class對象來同步,非靜態方法也可以通過使用class來同步靜態方法。但是靜態方法中不能使用this來同步非靜態方法。這點在使用synchronized塊需要注意。synchronized是對類的當前實例進行加鎖,防止其他線程同時訪問該類的該實例的所有synchronized塊,注意這裡是“類的當前實例”, 類的兩個不同實例就沒有這種約束了。static synchronized是要控制類的所有實例的訪問了,static synchronized是限制線程同時訪問jvm中該類的所有實例同時訪問對應的代碼塊。在類中某方法或某代碼塊中有 synchronized,那麼在生成一個該類實例後,該類也就有一個監視塊,放置線程並發訪問該實例synchronized保護塊,而static synchronized則是所有該類的實例公用一個監視塊了,也也就是兩個的區別了,也就是synchronized相當於 this.synchronized,而static synchronized相當於Something.synchronized。
八、spring
九、MyBatis
MyBatis要達到目的就是把用戶關心的和容易變化的數據放到配置文件中配置,方便用戶管理。而把流程性的、固定不變的交給ibatis來實現。這樣是用戶操作數據庫簡單、方便。以前用jdbc有很多操作是與業務和數據無關的,但我們只需要一個運行sql語句的功能,還有取回結果的功能,但是jdbc要求你處理連接、會話、statement,尤其是還要你注意關閉資源,還要寫try catch處理異常。ibatis 就是幫你把這些亂七八糟的東西都做了。ibatis通過 SQL Map將Java對象映射成SQL語句和將結果集再轉化成Java對象,與其他ORM框架相比,既解決了Java對象與輸入參數和結果集的映射,又能夠讓用戶方便的手寫使用 SQL語句。
//#總結起來有一下幾個優點: //ibatis把sql語句從Java源程序中獨立出來,放在單獨的XML文件中編寫,給程序的維護帶來了很大便利。 //ibatis封裝了底層JDBC API的調用細節,並能自動將結果集轉換成Java Bean對象,大大簡化了Java數據庫編程的重復工作。 //因為ibatis需要我們自己去編寫sql語句,程序員可以結合數據庫自身的特點靈活控制sql語句,因此能夠實現比hibernate等全自動orm框架更高的查詢效率,能夠完成復雜查詢。相對簡單易於學習,易於使用, 非常實用。
Mybatis原理,該框架的一個重要組成部分就是其 SqlMap 配置文件,SqlMap 配置文件的核心是 Statement 語句包括 CIUD。 MyBatis通過解析 SqlMap 配置文件得到所有的 Statement 執行語句,同時會形成 ParameterMap、ResultMap 兩個對象用於處理參數和經過解析後交給數據庫處理的 Sql 對象。這樣除去數據庫的連接,一條 SQL 的執行條件已經具備了。數據的映射大體的過程是這樣的:根據 Statement 中定義的 SQL 語句,解析出其中的參數,按照其出現的順序保存在 Map 集合中,並按照 Statement 中定義的 ParameterMap 對象類型解析出參數的 Java 數據類型。並根據其數據類型構建 TypeHandler 對象,參數值的復制是通過 DataExchange 對象完成的。
public class Test {
public static void main(String[] args) {
Class.forName("oracle.jdbc.driver.OracleDriver");
Connection conn = DriverManager.getConnection(url, user, password);
java.sql.PreparedStatement st = conn.prepareStatement(sql);
st.setInt(0, 1);
st.execute();
java.sql.ResultSet rs = st.getResultSet();
while (rs.next()) {
String result = rs.getString(colname);
}
}
}
上述代碼展現了原始的java操作數據庫的代碼,Mybatis就是將上面這幾行代碼分解包裝。但是最終執行的仍然是這幾行代碼。前兩行是對數據庫的數據源的管理包括事務管理,3、4 兩行ibatis通過配置文件來管理 SQL 以及輸入參數的映射,6、7、8 行是 iBATIS 獲取返回結果到 Java 對象的映射,他也是通過配置文件管理。
spring和Mybatis的事務機制,MyBatis的SqlMapSession 對象的創建和釋放根據不同情況會有不同,因為 SqlMapSession 負責創建數據庫的連接,包括對事務的管理,iBATIS 對管理事務既可以自己管理也可以由外部管理,iBATIS 自己管理是通過共享 SqlMapSession 對象實現的,多個 Statement 的執行時共享一個 SqlMapSession 實例,而且都是線程安全的。如果是外部程序管理就要自己控制 SqlMapSession 對象的生命周期。
spring對事務的解決辦法其實分為2種:編程式實現事務,AOP配置聲明式解決方案。spring提供了許多內置事務管理器實現,對於ibatis是DataSourceTransactionManager:位於org.springframework.jdbc.datasource包中,數據源事務管理器,提供對單個javax.sql.DataSource事務管理,用於Spring JDBC抽象框架、iBATIS框架的事務管理。注解形式@Transactional實現事務管理,只能被應用到public方法上,對於其它非public的方法,如果標記了@Transactional也不會報錯,但方法沒有事務功能。在public方法上面使用了@Transactional注解,當有線程調用此方法時,Spring會首先掃描到@Transactional注解,進入DataSourceTransactionManager繼承自AbstractPlatformTransactionManager的getTransaction()方法,在getTransaction()方法內部,會調用doGetTransaction()方法,@Transactional的注解中,存在一個事務傳播行為的概念,即propagation參數,默認等於PROPAGATION_REQUIRED,表示如果當前沒有事務,就新建一個事務,如果存在一個事務,方法塊將使用這個事務。
//#Spring的transactionAttributes的配置 //PROPAGATION_REQUIRED--支持當前事務,如果當前沒有事務,就新建一個事務。這是最常見的選擇。 //PROPAGATION_SUPPORTS--支持當前事務,如果當前沒有事務,就以非事務方式執行。 //PROPAGATION_MANDATORY--支持當前事務,如果當前沒有事務,就拋出異常。 //PROPAGATION_REQUIRES_NEW--新建事務,如果當前存在事務,把當前事務掛起。 //PROPAGATION_NOT_SUPPORTED--以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。 //PROPAGATION_NEVER--以非事務方式執行,如果當前存在事務,則拋出異常。 //PROPAGATION_NESTED--如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則進行與PROPAGATION_REQUIRED類似的操作
十、