寫寫對簡單的匹配原理的理解,還是以php為主。
首先,正則引擎主要可分為兩大類:DFA和NFA,反正引擎見多了就不奇怪了,簡單理解就是不同的匹配方式,就好比在數組中查找數據時,有的是從頭開始順序,查找,有的從中間開始查找,所用的方式不同。相對來說NFA有更長的歷史,使用NFA的工具或者語言更多,但也有兩個引擎混合使用的。某書上舉的例子非常貼切:NFA好比汽油機,DFA好比電動機,它們都能使汽車運行但有使用不同的機理。由於NFA和DFA都發展了很多年,所以又出台了一個被稱為POSIX的標准,它規定作為一個正則引擎應該支持的元字符和特性,以及最終用戶想要得到的准確結果。
NFA,以(正則)表達式為主導進行匹配,DFA則以待匹配的字符串為主導進行匹配。php使用的是傳統型的NFA引擎,當然了Perl也是。無論哪種引擎,有兩個通用的原則:1. 優先匹配最靠左端的結果;2. 標准量詞(+、?、*、{m,n})均是匹配優先的。
現有表達式如下,要匹配字符串'tonight'
'/to(nite|knite|night)/'
NFA:以表達式為主導,從表達式的第一部分開始,同時檢查當前文本是否匹配,如果是,繼續到表達式的下一部分,直到表達式全部都能匹配,整個匹配成功。表達式的第一個字符時t,它將在字符串中按順序從左到右反復查找,直到找到一個t字符,如果找不到就宣告失敗,如果找到,表達式下一個字符時o,繼續在待匹配字符串中查找,開頭兩個都能匹配上,進入到由括號分組的一個選擇分支中,匹配nite、knite或者night,它依次嘗試這種三種可能。第一個分支嘗試到nig時失敗,第二個分支嘗試到表達式中第一個n時失敗,第三個分支恰好完全匹配。以正則表達主導的引擎,就必須檢查完表達式才能得出最終結論。
DFA:與NFA不同,DFA在掃描字符串時,會記錄當前有效的所有匹配可能,從最開始的t,它會在當前的匹配可能中添加一種可能,如果存在的話,一直掃描到字符串中的n時,它會記錄兩種可能,nite和night兩處的n(它是從待匹配的字符串角度看表達式),繼續掃描到i還是nite和night兩種可能,接著到g只剩下night一種可能了,當h和t匹配完成後,引擎發現掃描字符串已掃描結束,報告成功(貌似有點深度與廣度的意味)。
所以,一般情況下文本主導的DFA引擎要更快一些,表達式主導的NFA必須檢測完所有的模式,在沒有抵達模式結束之前,不知道匹配的成功與否,即使前面某個表達式匹配成功了,說不定後面繼續要對它檢測一下,這可能會浪費很多時間。而DFA以字符串為主導,到一個地方頂多記錄幾種可能性,目標文本中的字符最多只會檢測一次。
但是多選分支的順序,對於不同目標字符串的影響也很大,恰好符合的分支在前面,當然能更快找到。
由於NFA以表達式為主,表達式書寫的不同會產生很大的影響,也能讓我們更加靈活的控制它,也具有更多的可變性。這其中,對於NFA來說(本來也是以php為主),有一個重要的特性:回溯---遇到需要從兩個可能成功的匹配中選擇時,先選擇一種,並記住另外一種,以作稍後可能的需要,這種情形主要出現在標准量詞和多選分支(|)。
盜圖一張: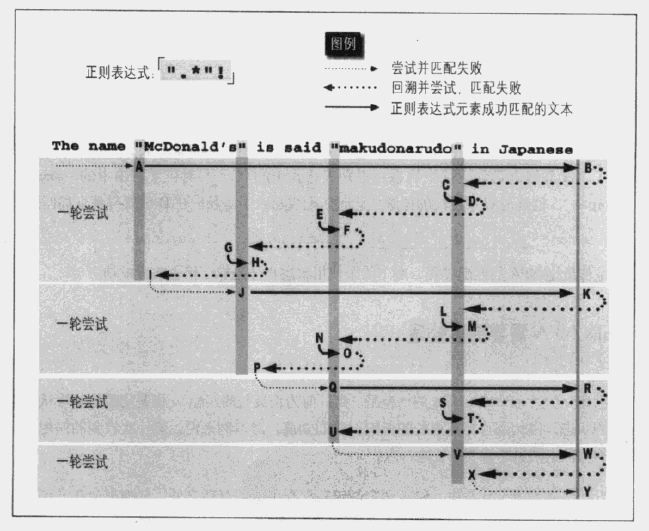
從表達式('/".*"!/')出發,首先找到雙引號A處,接著由於是點號匹配任意字符(默認不包括換行符,這兒不用考慮),再加上元字符*表示可以匹配多個,由於標准量詞的匹配優先機理,它一下子來到了字符串的結尾B處,因為在這之間*可以是0個、1個或多個,也就是說,這幾種形式都是有可能匹配成功的,因此,引擎會記住這兩種狀態,即在一個位置可能匹配,也可以不匹配它,只要是*元字符經過的地方,從M到結尾都會記錄。
等到結尾發現沒有",於是回溯,需要說明,引擎總是回溯到最近記錄的狀態(類似棧),一個個往前回溯,直到遇到一個雙引號的地方(C),然後匹配匹配到雙引號後面(D),發現不是感歎號!,失敗,再次回溯(狀態記錄不為空),到E處又找到了一個雙引號,與剛才情況相同,繼續匹配(F)發現沒有感歎號,失敗,繼續回溯到G,同樣由於後邊(H)不是感歎號,仍需要回溯,到I,這時記錄的狀態已經沒有了,也無法繼續回溯了,第一輪匹配失敗告終,但還沒完,引擎的傳動裝置繼續從A處雙引號的下一個位置開始繼續尋找第一個符合條件的雙引號,到J,然後類似上一輪的過程繼續上演。最終也沒找到 "..."! 這樣的字符串,過程卻很曲折。
從上面的例子可以看出:一是 .* 這種形式的效率非常低,尤其在失敗的時候(當然平常我們那幾行代碼幾乎忽略不計),而且很容易出錯,比如用 /".*/" 匹配一對雙引號包圍的字符串來匹配 ab"cde"fgh""ijk"lmn,最終的結果是"cde"fgh""ijk",最開始的雙引號和最末尾的雙引號中間的全部內容;二是如果有類似 ((...)*)*、((...)+)*之類的,外面裡面同時記錄不定狀態的,回溯次數呈指數級上升,甚至形成死循環,更加耗時。當然對於改進狀態的引擎提前檢測這種狀況,並報告錯誤,如同浏覽器在自己跳轉自己的頁面那樣報錯。
因此在用到量詞時,比如+,它可以匹配一個到多個,大於一個時,不是必須的,有兩種選擇狀態,可以有也可以沒有,這兩種狀態就是日後可能會在回溯中用到的狀態,稱為備用狀態,?也是如此。
對於匹配雙引號及之間的字符,中間不包括轉義後的雙引號的情況,我們可以使用忽略優先,'/".*?"/' ,忽略優先按量詞的最小限度匹配, *最小是沒有,相當於先檢測空串,沒有先匹配一個字符馬上檢測雙引號,這在一定只要檢測到右邊有一個雙引號匹配即成功結束,它匹配上圖中的 "McDonald's"也省去了很多回溯。
當然,對於這種需要檢測兩個字符間的其他字符,還有一種辦法,如 '/"[^"]"/',排除型字符組,它也達到了相同的需求,但情況不總是這樣。
比如,匹配<b>與</b>之間的字符,使用 '/<b>[^<\/b>]*<\/b>/' ?注意字符組一次只能匹配一個字符,這裡是匹配在<b>和</b>之間的,非<、/、b、>的任意一個字符,字符組不能把裡邊的字符當一個整體,對於整體、多個字符的檢測,可以選擇環視。環視與位置相關,生來就是限定周圍的字符,一個或多個均可。這裡需要否定型環視,因為我們需要的不能是</b>的字符,為了好看中間隔開。
'/<b>( (?!<\/b>) . )*<\/b>/' // 否定型環視
但是上面仍能匹配"<b>abc<b>def</b>",所以還要在其之間排除<b>,中間環視檢測</?b>,/可以有或沒有都行
'/<b> ( (?! <\/? b >) . )* <\/b>/'
上一篇寫到了“交還”,在回溯過程中就伴隨著交還,如上面的'/".*"!/',因發現雙引號後面不是感歎號,而不得不回溯,此時選擇另一種備用狀態---不匹配剛才匹配到的字符,進行回退,是一個明顯的交還。例子:
$pattern_1 = '/(\w+)(\d?)/';
$pattern_2 = '/(\w+)(\d+)/';
$pattern_3 = '/(\w+)(\d*)/';
$subject = 'abc12345';
preg_match($pattern_1, $subject, $match_1);
preg_match($pattern_2, $subject, $match_2);
preg_match($pattern_3, $subject, $match_3);
echo 'match=><pre>';
var_dump($match_1, $match_2, $match_3);
使用捕獲型括號,分組,引擎記住兩個括號中匹配的文本。結果如下:

從上到下依次為$match_1、$match_2、$match_3,由於\w與\d有公共部分,而且兩個量詞都是匹配優先,從結果來看,前一個+量詞匹配得最多(鍵值為1的項),pattern_1中,\d?沒有匹配,pattern_2中,\d+只匹配了一個,pattern_3中,\d*沒有匹配,而它們讷的過程都類似於,先讓\w+匹配到末尾,然後引擎看剩余的模式,\d?可有可無,那就無,因為無正則匹配也是成功,不交還。\d+必須匹配一個,否則將導致匹配失敗,這裡它會交還一個,因為它必須服從使得全局匹配的成功。對於\d*也是如此,可以不匹配,不交還。
假如這裡的pattern是'/(\w+)(\d\d)/',那麼它就必須交還兩個數字,如果沒有交還或是帶匹配字符串中沒有,就只能報告失敗。所以有兩個規律:
1. 先來先服務原則,匹配優先的量詞在前,先盡量滿足自己;
2. 必須服從全局匹配結果,有造成失敗的可能,引擎會強迫匹配優先量詞交還,否則整個匹配失敗。
如果不交還呢?就會提前報告失敗。必須談到占有優先量詞和固化分組,以+為例形式是 \w++、 (?>\w+)
$pattern = '/\w+:/';
$subject = 'abcdefghijk';
如例,我們人當然能一眼看出來,字符串結尾沒有冒號肯定失敗,但是程序不會這樣,它會一輪又一輪的匹配-回溯,因為它記住了一些可選擇性的狀態,但現在我們已經明確知道了這些狀態是沒用的,回溯也是白費力氣,回溯前就已經失敗了。所以可以 \w++: 或者 (?>\w+): ,有了占有優先或者固化分組,這些可選擇性的狀態都會被拋棄,\w+一直匹配到字符串結尾,單詞沒了,然後檢測冒號存不存在,冒號不存在,但是現在有沒有可供回溯的狀態,立即報告失敗,如果是幾十萬行的文本會節省很多時間。
需要注意的是,固話分組或是占有優先對嵌套在裡面的量詞也是有作用的,這點跟?:只分組不捕獲不同
(?> (\d+)+ ) // 裡面的\d+的狀態也會被拋棄
(?: abc (\d\d) ) // 外層的括號不會被捕獲,但裡面的括號不受影響,\1仍記錄著數字字符
最後記錄下選擇分支的一個坑,例
$pattern = '/cat/';
$subject = 'indicate big cat';
cat當然會匹配indicate中間的cat,因為它在前面。再看這個
$pattern = 'fat|cat|belly|your';
$subject = 'The dragging belly indicates that your cat is too fat';
NFA以表達式為主導,從表達式的角度看字符串,因此先檢測到的是fat,結果是fat嗎?結果仍是cat!所以NFA的引擎始終優先匹配選擇分支選擇最左端的匹配結果,哪怕它位於選擇分支的後邊。
這也說明,NFA引擎的正則,只要表達式中還存在可能的多選分支,正則引擎會回溯到存在尚未嘗試的多選分支的地方,這個過程不斷重復,直到完成全局匹配,如果不是這樣,上例中fat先匹配成功就已經作為結果返回了。多選狀態不是匹配優先,也不是忽略優先,但是嘗試是從左到右。而對於DFA和某些POSIX NFA,匹配的不是最靠字符串左端的文本,而是選擇分支中最長的分支。
正則的細節太多,扯不清楚,還是得看書理解,尤其是對於正則的調校,以及某些常用的判斷技巧,比如匹配" "包圍的字符串,中間可以有\"和其他轉義序列,還是很麻煩的,推薦《精通正則表達式》,中文翻譯挺棒,讀起來也不生硬,而且還有很多技巧性的東西,比如“消除循環”是一大利器。end