簡介
在當前的很多 IT 應用中,及時發現可疑行為是一項很重要的任務。以信用卡事務為例。如果一個用戶表現出異常的購買行為(例如,平常都是在廉價商店買東西,現在突然購買昂貴的珠寶),那麼最好檢查相應的事務,以跟蹤欺詐行為。除了檢測欺詐行為或惡意操縱外,偏差還可以用於其他一些場景。人力資源部門使用偏差檢測來發現異常的雇員或求職者。如果僅憑固定的規則識別潛在的情況,則這些人可能被忽視。
偏離全局數據分布的數據記錄稱為離群值(outlIEr)。離群值處理通常不是一項完全自動化的任務。相反,數據挖掘用於指出有待分析師或專家進一步分析的數據記錄。然後,析師或專家以此為依據決定是否采取行動。因此,一個先進的用戶界面和交互模型是成功處理離群值的前提條件。Cognos 很適合完成這項任務。實際上,可以使用一個類似於本 系列 的 將 InfoSphere Warehouse 數據挖掘與 IBM Cognos 報告集成,第 1 部分:InfoSphere Warehouse 與 Cognos 集成架構概述 中創建的報告來可視化離群值。但是,要想充分利用 Cognos 顯示離群值的潛力,需要采用一些更高級的技巧。首先,看看如何使用 “穿透鑽取(drill-through)” 來創建交互式 Cognos 報告,以及如何鏈接報告。這將有助於總結信息,同時允許快速訪問相關的異常數據記錄。其次,學習如何從數據挖掘模型中提取出附加信息,這些附加信息可幫助專家理解離群值的性質。
本文中的實例是一個應用程序,該應用程序幫助一家銀行的雇員識別行為異常的客戶。這個應用程序可用於避免欺詐,或檢測出需要特別關注的客戶。下一小節將對偏差檢測作一個概述,並展示如何使用 InfoSphere Warehouse 發現大型數據集中的離群值。隨後的小節則闡述從挖掘模型中穿透鑽取和提取信息的基礎知識,並展示如何使用這兩種技巧使偏差檢測結果更容易理解和利用。
使用 InfoSphere Warehouse 進行偏差檢測
什麼是偏差檢測?
偏差檢測是一項在大型數據集中發現異常數據記錄的任務。這些記錄稱為離群值。“異常” 的確切定義還有待討論,但它與應用偏差檢測的領域有關。通常而言,偏差檢測的目標是發現不符合大多數數據記錄整體統計分布的數據記錄。根據應用領域不同,偏差可能是:
不正確的數據(例如,如果一個人的年齡為 300,這很可能是數據庫中一個不正確的條目)
異常行為(例如,不符合通常模式的信用卡事務)
相應地,偏差檢測可用於不同的任務。如果您猜測數據集包含不正確的數據,那麼可以應用偏差檢測進行數據清洗,從而發現數據庫中不正確的條目。在第二種情況下,數據是正確的,但是反映出某個過程表現出異常的行為。這可用於檢測欺詐,這是偏差檢測的第二個主要應用。前面已指出,異常的行為不一定是欺詐。例如,也可能表明新興的模式,比如 “過度使用在線拍賣的老年客戶”。盡早檢測出新興模式有助於公司盡早提供新的產品或服務,從而獲得競爭優勢。在財務部門就可以發現類似的應用。可以使用偏差檢測來發現有前景的投資,這種投資不符合通常的模式,因而到目前為止還沒有人意識到。在所有這些案例中,必須由分析師來檢查離群值,看看是數據是否正確,是否需要采取措施避免欺詐,或者利用還沒有人意識到的機遇。接下來將了解 InfoSphere Warehouse 如何檢測離群值,以及如何對數據應用偏差檢測。本文剩下的內容討論如何在 Cognos 中交互式地可視化離群值。
InfoSphere Warehouse 中的偏差檢測
近年來產生了很多不同的用於檢測偏差的方法。InfoSphere Warehouse 使用一種特別強大的方法來進行偏差檢測,這種方法基於數據集群。集群是一種數據挖掘技術,這種技術根據數據記錄的屬性將相近的數據記錄指定到集群中。我們來看看 圖 1。圖中每個點表示一個客戶。在這個簡單的案例中,客戶只以年齡和平均余額來描述。InfoSphere Warehouse 使用一個統計集群算法將在這兩個維上相近的客戶分到集群中。可以看到,有些集群比其他集群更大,更集中(集群 1 相對於集群 3)。InfoSphere Warehouse 結合一些屬性為每個集群賦予一個 “偏差” 度。這個度越高,則該集群中的記錄越有可能是離群值。
圖 1. 基於集群的偏差檢測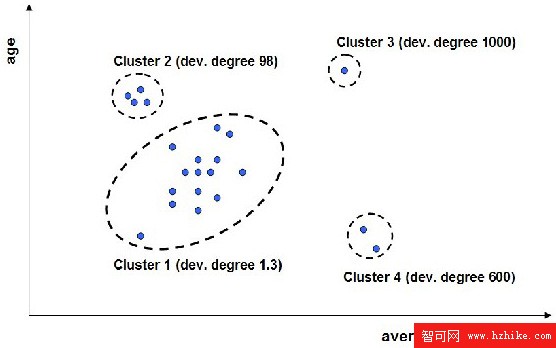
查看原圖(大圖)
離群值與非離群值之間並沒有明顯的區別。實際上,用戶必須指定一個阈值,以便界定離群值。偏差度高於這個阈值的所有集群被標記為離群值集群,它們的成員都是離群值。這個阈值可通過兩種方式來設置。首先,如果檢查離群值的專家有限,那麼可以使用具有最高偏差度的集群的數據記錄。如果要尋找有投資前景的公司,那麼可以先從具有最高偏差度的集群開始,然後在資源允許的情況下,逐漸轉向偏差度較低的集群。其次,阈值可以是固定的。一個例子就是警報場景,在此場景中,當有新的數據記錄分配到具有高於給定阈值的偏差度的集群時,則需要采取行動。InfoSphere Warehouse 同時支持這兩種方式,您只需為每個數據記錄賦予一個集群 id 和相應的偏差度。您可以過濾記錄,也可以對它們進行排序,從而獲得想要查看或必須檢查的離群值。接下來的小節將提供一個例子,以逐步演示如何用 InfoSphere Warehouse 發現離群值,以及如何為各個數據記錄賦予偏差度。
一個實例
接下來的例子對關於銀行客戶的條目應用偏差檢測。圖 2 中顯示了相應表中的示例數據。表 BANK.BANKCUSTOMERS 是 InfoSphere Warehouse 的示例中附帶的。
圖 2. BANK.BANKCUSTOMERS 表中的示例數據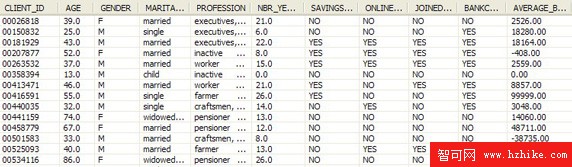
查看原圖(大圖)
為了檢測這個表中的離群值:
像 將 InfoSphere Warehouse 數據挖掘與 IBM Cognos 報告集成,第 1 部分:InfoSphere Warehouse 與 Cognos 集成架構概述 中描述的那樣,創建一個新的挖掘流。
同樣,像上一篇文章那樣,您必須將一個 table source 操作符拖到編輯器中。
雙擊打開這個操作符,指定 BANK.BANKCUSTOMERS 作為源數據庫表,並單擊 OK 確認。
現在,將一個 “Find Deviations” 操作符拖到畫布上 table source 旁邊的位置,並將 table source 的輸出端連接到 “Find deviations” 的輸入端。將 “Find Deviations” 操作符生成的集群模型的模型名稱改為 IDMMX.OUTLIERMODEL。雙擊該操作符打開屬性,在向導的第二頁更改模型名稱。
最後,從 “Find Deviations” 操作符輸出端的右鍵菜單中選擇 “Create Suitable Table...”,創建適當的目標表。在向導的第一個頁面上,選擇模式 BANK,並輸入表名 CUSTOMERS_OL。單擊 Finish。一個 “Table Target” 操作符將被連接到流中。如果想要多次運行這個流,那麼可以在 “Table Target” 操作符的屬性中勾選復選框 “Delete Previous Content”。
這個流裝載客戶表,將它傳遞到偏差檢測算法,並將結果寫到一個新表中(如 圖 3 所示)。在 圖 4 中可以看到具體的結果。
圖 3. 用於檢測偏差的挖掘流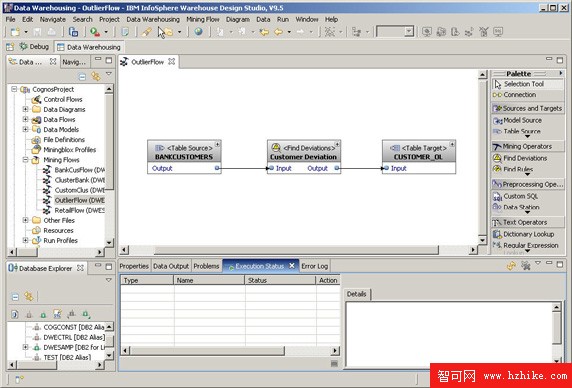
查看原圖(大圖)
可以看到,這裡有兩個附加列,即 DEV_DEGREE 和 CLUSTER_ID。前一個列表明記錄傾向於離群值的程度。cluster id 是記錄所屬的 “離群值” 集群的 id。可以通過分析 find deviation 操作符內部創建的集群模型,提取關於這些集群的更多信息。(本文還將對此進行詳細討論)。
圖 4. 結果表 BANK.CUSTOMER_OL 中的示例數據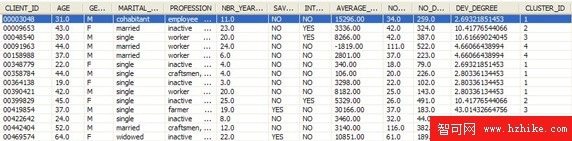
查看原圖(大圖)
為偏差檢測創建交互式 Cognos 報告
在本節中,學習如何創建允許交互式查看離群值的 Cognos 報告。開始時可以使用一個類似於本系列第一篇文章中所用的報告。但是,這次不是一個病人列表(其中有一個關於哪些病人應該進行體檢的指示器),而是一個客戶列表,其中有一個關於應該檢查哪些客戶的指示器,看是否存在欺詐或潛在機會。這種方法適用於有較少數量客戶的列表,但不適用於有數千個條目的列表。而且,分析師可能還想看是什麼使得一個特定的客戶成為一個 “離群值”。需要更多的信息才能完成這個任務。因此,讓我們從兩個方面來擴展這個簡單的方法:
將客戶按職業分組,並提供關於每種職業發現多少離群值的概述。這種分組方式對於處理大量的信息是一個好方法。例如,可以讓一個特定的雇員負責一個類別,使每個類別都得到檢查。除了職業外,其他方面也可以用於分組(比如位置)。
對於每個記錄,添加將其劃分為離群值的信息。如前所述,每個記錄被指定到一個集群,一個集群的所有成員具有相同的偏差度。因此,可以使用一個集群的屬性來描述離群值。例如,如果一個集群中大部分是年輕人,而他們有較高的平均余額,那麼這可以很好地解釋為什麼這個集群被認為是離群值集群。
接下來的小節首先展示如何用附加信息擴展離群值。然後,您將創建一個交互式報告,該報告將客戶按職業分組,並且允許使用 Cognos 的 “穿透鑽取” 特性交互式地選擇一個特定類別中的離群值。
從挖掘模型中提取附加信息
表 CUSTOMER_OL 包含關於離群值的相關信息。如前所述,每個記錄被指定到一個集群。“Find Deviations” 操作符在後台創建一個集群模型,其中存儲關於這些集群的詳細信息。該信息以 PMML(Predictive Model Markup Language)格式存儲在數據庫中。它包含關於以下方面的信息:
集群中值的分布
集群中記錄的數量
每個集群的偏差的重要性
集群的同質性
其他
可以使用 InfoSphere Warehouse 附帶的存儲過程將該信息提取到結果集中,以便 Cognos 進一步處理。這樣的結果集可以看作是 “視圖”,它們不是顯式地在數據庫中創建的,而是由存儲過程動態地創建的。
如果要提取關於集群的文本信息,可使用以下命令:
SELECT ID, DESCRIPTION FROM TABLE(IDMMX.DM_GETCLUSTERS((SELECT MODEL FROM IDMMX.CLUSTERMODELS WHERE MODELNAME='IDMMX.OUTLIERMODEL'))) AS CT
這樣可以得到一個包含以下列的表:
ID:集群的 id(對應於 CUSTOMER_OL 表中的 ID)
DESCRIPTION:集群的文本描述
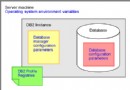
Cognos 可以使用這些結果集作為視圖或表。惟一要注意的是,DB2 中沒有包括這些存儲過程,它們是由 InfoSphere Warehouse 提供的。我們稍後對此進行討論。圖 5 總結了從 InfoSphere 提取信息到 Cognos 的兩種方法:使用簡單的數據庫視圖/表,或者使用存儲過程從挖掘模型中提取信息。這些存儲過程不僅可以用於集群模型,還可以用於其他挖掘模型。要獲得所有可用的模型提取函數的列表,請參閱 InfoSphere Warehouse 文檔。接下來,我們將展示如何使用 Cognos framework manager 合並這兩種信息。
圖 5. 在 Cognos 中訪問和挖掘相關信息的兩種方法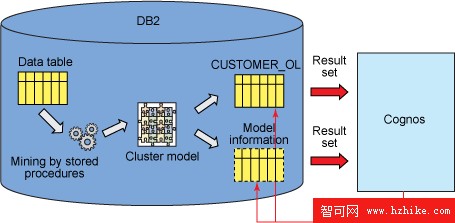
在 Cognos Framework Manager 中導入和合並挖掘結果
對於這個報告,Cognos 項目中需要兩個查詢主題,然後通過連接它們獲得每個離群值的文本描述:
一個簡單的訪問第一節中創建的離群值表 BANK.CUSTOMER_OL 的查詢主題。這個查詢主題包含客戶記錄和偏差度以及集群 id。
查詢主題使用存儲過程訪問由挖掘算法創建的集群模型的集群信息。如前所述,集群信息包括對集群的簡短文本描述(在這裡就是對這個集群中所有離群值記錄的描述)和其他信息。
首先,需要創建一個 Cognos Framework Manager 項目,該項目連接到 InfoSphere Warehouse 的示例數據庫 DWESAMP,並且有前面創建的 BANK.CUSTOMERS_OL 表。本系列的 將 InfoSphere Warehouse 數據挖掘與 IBM Cognos 報告集成,第 1 部分:InfoSphere Warehouse 與 Cognos 集成架構概述 提供這個步驟的詳細說明。一個很好的做法是在 PresentationVIEw 名稱空間中創建一個查詢主題,這個查詢主題包含必要的數據庫中的信息,以便擁有從 SQL 語句創建的查詢主題上的抽象層。這也使得您可以將列名改成更具描述性的文本,還可以添加更多的列。您需要一個離群值標記項,以表明一個記錄是否為離群值。可以根據偏差度查詢項 DEV_DEGREE 計算出這個標記項。
為了創建報告使用的離群值表查詢主題:
在 PresentationView 名稱空間中從模型(已有的查詢主題和查詢項)創建一個新的查詢主題 “OutlIErTable”。
添加 CUSTOMER_OL 查詢主題中的所有查詢項,並將它們的名稱改成更具描述性的名稱。
用以下表達式定義添加一個新的查詢項:IF ([PresentationView].[OutlIErTable].[Deviation factor] > 1000) then (1) else (0)
如果偏差大於 1000,這個查詢項的值將為 “1”;否則,它將為 “0”。偏差系數 1000 用作數據集的敏感分界系數。將這個偏差敏感度參數化有助於返回更多或更少的記錄作為離群值。
查詢主題定義看上去應該如圖 6 所示:
圖 6. 離群值表的查詢主題定義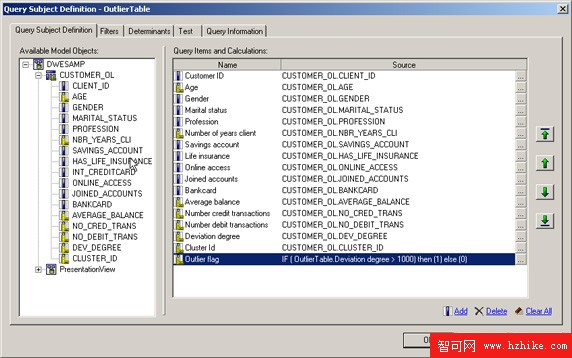
查看原圖(大圖)
第二個查詢項是一個表,其中包含關於集群模型的集群的信息,這個集群模型是在 find deviation 運行期間創建的。可以在 InfoSphere Warehouse Data Mining 中使用用戶定義函數 IDMMX.DM_GETCLUSTERS 提取集群模型的列表描述。該函數返回一個表,其中包含模型中的集群,以及關於這個集群中字段分布的簡短文本描述。在 IDMMX.CLUSTERMODELS 表中,集群模型被保存為 CLOBS,另外,該表中還包括一個 “MODELNAME” 列,用於選擇適當的模型。用戶定義函數需要打包到 SELECT 語句中,以供 Gognos 使用。由於 InfoSphere Warehouse Mining 表函數不是標准的 DB2 函數,所以在創建這個查詢主題之前,需要更改一些 Cognos 選項。
為了從 DB2 表函數創建集群描述查詢主題,您需要:
在 Project VIEwer 中,選擇 Data Sources 文件夾中的數據庫 DWESAMP,在屬性視圖中將 “Query Processing” 屬性改為 “Limited Locale”。這樣就啟用了來自 SQL 的 Cognos 不能識別的查詢主題。
在 PresentationView 名稱空間中創建一個新的查詢主題 “OutlIErClusters”,並選擇從一個數據源對該查詢主題建模。如果從一個存儲過程中對它進行建模,那麼只支持 Cognos 能識別的存儲過程。
在 “Select a data source” 頁面上,選擇 DWESAMP,並取消對選擇 Run database query subject wizard 復選框。查詢主題向導只適用於標准 SQL。單擊 Finish。
創建查詢主題後,會出現 Query Subject Definition 向導。輸入 SQL 代碼,以返回模型中的集群,其中 IDMMX.OUTLIERMODEL 是 “find deviations” 運行期間生成的集群模型的名稱。 SELECT * FROM TABLE(IDMMX.DM_GETCLUSTERS((SELECT MODEL
FROM IDMMX.CLUSTERMODELS WHERE MODELNAME='IDMMX.OUTLIERMODEL'))) AS CT
由於 Cognos 不能識別這個的 SQL,因此需要將查詢的 SQL 類型設為 “Native”,這告訴 Cognos 將 SQL 傳遞給數據庫,而不是解釋它。要改變這個設置,可以打開查詢主題屬性的 “Query Information” 選項卡。選擇 “Options”,將 “SQL settings” 下的 “SQL type” 改為 “Native”。
“Test Sample” 運行後應該返回一個表,其中包含模型中的集群,如圖 7 所示:
圖 7. 離群值集群查詢主題的測試結果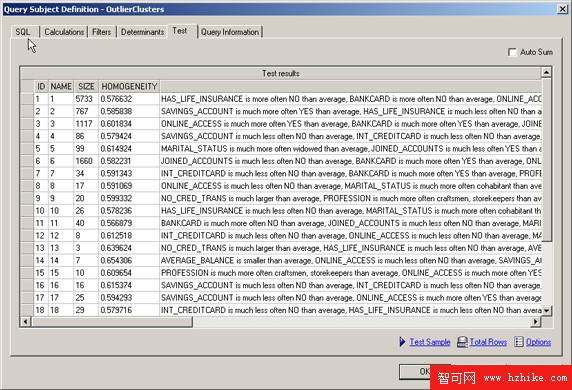
查看原圖(大圖)
使用存儲過程作為查詢主題輸入有一個好處,那就是不需要在數據庫中創建不必要的表或視圖。更重要的是,存儲過程將在報告生成期間執行。這使得它可以在報告生成期間動態地執行挖掘計算。本系列後面的文章將更詳細地討論這個專題。
為了創建連接 OutlierTable 表和 OutlIErClusters 查詢主題的報告,需要在離群值記錄中的集群 id 與集群表中的集群 id 之間建立一個關系。
為了在 OutlierTable 與 OutlIErClusters 查詢主題之間建立一個關系,您需要:
從 OutlIErTable 的上下文菜單中選擇 Create Relationship。
對於左邊的查詢主題,選擇 OutlIErTable 的集群 id,並將基數設為 1..n,因為有多個記錄屬於同一個集群。
對於右邊的查詢主題,添加 OutlIErClusters 查詢主題,選擇 ID 列,並將基數設為 1..1,因為對於每個集群有一行記錄。
選擇 OK。
圖 8. OutlierTable 與 OutlIErClusters 查詢主題之間的關系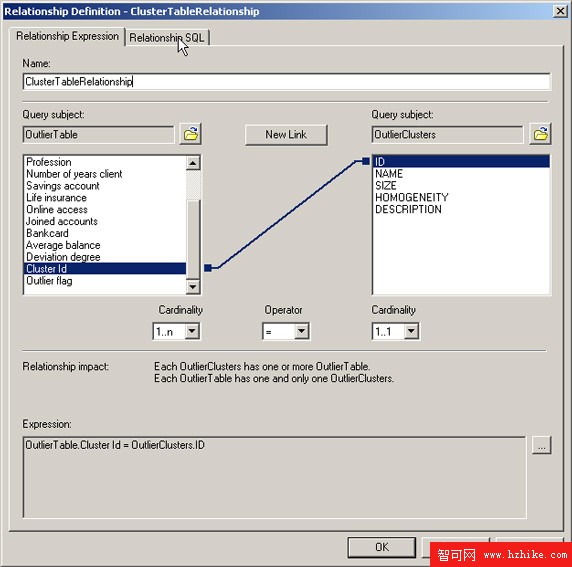
查看原圖(大圖)
您已經創建了 Cognos 報告所需的查詢主題,現在可以將一個包含項目的 PresentationView 的 “OutlIErsPackage” 部署到 Cognos Content Store。可以像本系列 將 InfoSphere Warehouse 數據挖掘與 IBM Cognos 報告集成,第 1 部分:InfoSphere Warehouse 與 Cognos 集成架構概述 創建和部署這個包。