作為C++標准不可缺少的一部分,STL應該是滲透在C++程序的角角落落裡的。STL不是實驗室裡的寵兒,也不是程序員桌上的擺設,她的激動人心並非昙花一現。本教程旨在傳播和普及STL的基礎知識,若能借此機會為STL的推廣做些力所能及的事情,到也是件讓人愉快的事情。
2 牛刀小試:且看一個簡單例程
2.1 引子
如果你是一個純粹的實用主義者,也許一開始就可以從這裡開始看起,因為此處提供了一個示例程序,它可以帶給你有關使用STL的最直接的感受。是的,與其紙上談兵,不如單刀直入,實際操作一番。但是,需要提醒的是,假如你在興致昂然地細細品味本章內容的時候,能夠同時結合前面章節作為佐餐,那將是再好不過的。你會發現,前面所提到的有關STL的那些優點,在此處得到了確切的應證。本章的後半部分,將為你演示在一些主流C++編譯器上,運行上述示例程序的具體操作方法,和需要注意的事項。
2.2 例程實作
非常遺憾,我不得不捨棄"Hello World"這個經典的范例,盡管它不只一次的被各種介紹計算機語言的教科書所引用,幾乎成為了一個默認的“標准”。其原因在於它太過簡單了,以至於不具備代表性,無法展現STL的巨大魅力。我選用了一個稍稍復雜一點的例子,它的大致功能是:從標准輸入設備一般是鍵盤)讀入一些整型數據,然後對它們進行排序,最終將結果輸出到標准輸出設備一般是顯示器屏幕)。這是一種典型的處理方式,程序本身具備了一個系統所應該具有的幾乎所有的基本特征:輸入 + 處理 + 輸出。
你將會看到三個不同版本的程序。
第一個是沒有使用STL的普通C++程序,你將會看到完成這樣看似簡單的事情,需要花多大的力氣,而且還未必沒有一點問題真是吃力不討好)。
第二個程序的主體部分使用了STL特性,此時在第一個程序中所遇到的問題就基本可以解決了。同時,你會發現采用了STL之後,程序變得簡潔明快,清晰易讀。
第三個程序則將STL的功能發揮到了及至,你可以看到程序裡幾乎每一行代碼都是和STL相關的。這樣的機會並不總是隨處可見的,它展現了STL中的幾乎所有的基本組成部分,盡管這看起來似乎有點過分了。
有幾點是需要說明的:
這個例程的目的,在於向你演示如何在C++程序中使用STL,同時希望通過實踐,證明STL所帶給你的確確實實的好處。程序中用到的一些STL基本組件,比如:vector一種容器)、sort一種排序算法),你只需要有一個大致的概念就可以了,這並不影響閱讀代碼和理解程序的含義。
很多人對GUI圖形用戶界面)的運行方式很感興趣,這也難怪,漂亮的界面總是會令人賞心悅目的。但是很可惜,在這裡沒有加入這些功能。這很容易解釋,對於所提供的這個簡單示例程序而言,加入GUI特性,是有點本末倒置的。這將會使程序的代碼量驟然間急劇膨脹,而真正可以說明問題的核心部分確被淹沒在諸多無關緊要的代碼中間你需要花去極大的精力來處理鍵盤或者鼠標的消息響應這些繁瑣而又較為規范的事情)。即使你有像Borland C++ Builder這樣的基於IDE集成化開發環境)的工具,界面的處理變得較為簡單了框架代碼是自動生成的)。請注意,我們這裡所談及的是屬於C++標准的一部分STL的第一個字母說明了這一點),它不涉及具體的某個開發工具,它是幾乎在任何C++編譯器上都能編譯通過的代碼。畢竟,在Microsoft Visual C++和Borland C++ Builder裡,有關GUI的處理代碼是不一樣的。如果你想了解這些GUI的細節,這裡恐怕沒有你希望得到的答案,你可以尋找其它相關書籍。
2.2.1 第一版:史前時代--轉木取火
在STL還沒有降生的"黑暗時代",C++程序員要完成前面所提到的那些功能,需要做很多事情不過這比起C程序來,似乎好一點),程序大致是如下這個樣子的:
- // name:example2_1.cpp
- // alias:Rubish
- #include
- #include
- int compare(const void *arg1, const void *arg2);
- void main(void)
- {
- const int max_size = 10; // 數組允許元素的最大個數
- int num[max_size]; // 整型數組
- // 從標准輸入設備讀入整數,同時累計輸入個數,
- // 直到輸入的是非整型數據為止
- int n;
- for (n = 0; cin >> num[n]; n ++);
- // C標准庫中的快速排序quick-sort)函數
- qsort(num, n, sizeof(int), compare);
- // 將排序結果輸出到標准輸出設備
- for (int i = 0; i < n; i ++)
- cout << num[i] << "\n";
- }
- // 比較兩個數的大小,
- // 如果*(int *)arg1比*(int *)arg2小,則返回-1
- // 如果*(int *)arg1比*(int *)arg2大,則返回1
- // 如果*(int *)arg1等於*(int *)arg2,則返回0
- int compare(const void *arg1, const void *arg2)
- {
- return (*(int *)arg1 < *(int *)arg2) ? -1 :
- (*(int *)arg1 > *(int *)arg2) ? 1 : 0;
- }
這是一個和STL沒有絲毫關系的傳統風格的C++程序。因為程序的注釋已經很詳盡了,所以不需要我再做更多的解釋。總的說來,這個程序看起來並不十分復雜本來就沒有太多功能)。只是,那個compare函數,看起來有點費勁。指向它的函數指針被作為最後一個實參傳入qsort函數,qsort是C程序庫stdlib.h中的一個函數。以下是qsort的函數原型:
- void qsort(void *base, size_t num, size_t width, int (__cdecl *compare )
- (const void *elem1, const void *elem2 ) );
看起來有點令人作嘔,尤其是最後一個參數。大概的意思是,第一個參數指明了要排序的數組比如:程序中的num),第二個參數給出了數組的大小qsort沒有足夠的智力預知你傳給它的數組的實際大小),第三個參數給出了數組中每個元素以字節為單位的大小。最後那個長長的家伙,給出了排序時比較元素的方式還是因為qsort的智商問題)。
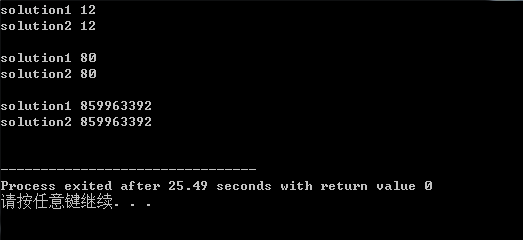
以下是某次運行的結果:
輸入:0 9 2 1 5
輸出:0 1 2 5 9
有一個問題,這個程序並不像看起來那麼健壯Robust)。如果我們輸入的數字個數超過max_size所規定的上限,就會出現數組越界問題。如果你在Visual C++的IDE環境下以控制台方式運行這個程序時,會彈出非法內存訪問的錯誤對話框。這個問題很嚴重,嚴重到足以使你開始重新審視這個程序的代碼。為了彌補程序中的這一缺陷。我們不得不考慮采用如下三種方案中的一種:
第一種方案比較簡單,你所做的只是將max_size改大一點,比如:1000或者10000。但是,嚴格講這並不能最終解決問題,隱患仍然存在。假如有人足夠耐心,還是可以使你的這個經過糾正後的程序崩潰的。此外,分配一個大數組,通常是在浪費空間,因為大多數情況下,數組中的一部分空間並沒有被利用。
再來看看第二種方案,通過在第一個for循環中加入一個限定條件,可以使問題得到解決。
比如:
- for (int n = 0; cin >> num[n] && n < max_size; n ++);
但是這個方案同樣不甚理想,盡管不會使程序崩潰,但失去了靈活性,你無法輸入更多的數。
看來只有選擇第三種方案了。是的,你可以利用指針,以及動態內存分配妥善的解決上述問題,並且使程序具有良好的靈活性。這需要用到new,delete操作符,或者古老的malloc(),realloc()和free()函數。但是為此,你將犧牲程序的簡潔性,使程序代碼陡增,代碼的處理邏輯也不再像原先看起來那麼清晰了。
一個compare函數或許就已經令你不耐煩了,更何況要實現這些復雜的處理機制呢?很難保證你不會在處理這個問題的時候出錯,很多程序的bug往往就是這樣產生的。同時,你還應該感謝stdlib.h,它為你提供了qsort函數,否則,你還需要自己實現排序算法。如果你用的是冒泡法排序,那效率就不會很理想。……,問題真是越來越讓人頭疼了!
關於第一個程序的討論就到此為止,如果你對第三種方案感興趣的話,可以嘗試著自己編寫一個程序,作為思考題。這裡就不准備再浪費筆墨去實現這樣一個讓人不甚愉快的程序了。
2.2.2 第二版:工業時代--組件化大生產
我們應該慶幸自己所生活的年代。工業時代,科技的發展所帶來的巨大便利已經影響到了我們生活中的每個細節。如果你還在以原始人類的方式生活著,那我真該懷疑你是否屬於某個生活在非洲或者南美叢林裡的原始部落中的一員了,難道是瑪雅文明又重現了?
STL便是這個時代的產物,正如其他科技成果一樣,C++程序員也應該努力使自己適應並充分利用這個"高科技成果"。讓我們重新審視第一版的那個破爛不堪的程序。試著使用一下STL,看看效果如何。
- // name:example2_2.cpp
- // alias:The first STL program
- #include
- #include
- #include
- using namespace std;
- void main(void)
- {
- vector num; // STL中的vector容器
- int element;
- // 從標准輸入設備讀入整數,
- // 直到輸入的是非整型數據為止
- while (cin >> element)
- num.push_back(element);
- // STL中的排序算法
- sort(num.begin(), num.end());
- // 將排序結果輸出到標准輸出設備
- for (int i = 0; i < num.size(); i ++)
- cout << num[i] << "\n";
- }
這個程序的主要部分改用了STL的部件,看起來要比第一個程序簡潔一點,你已經找不到那個討厭的compare函數了。它真的能很好的運行嗎?你可以試試,因為程序的運行結果和前面的大致差不多,所以在此略去。我可以向你保證,這個程序是足夠健壯的。不過,可能你還沒有完全看明白程序的代碼,所以我需要為你解釋一下。畢竟,這個戲法變得太快了,較之第一個程序,一眨眼的功夫,那些老的C++程序員所熟悉的代碼都不見了,取而代之的是一些新鮮玩意兒。
程序的前三行是包含的頭文件,它們提供了程序所要用到的所有C++特性包括輸入輸出處理,STL中的容器和算法)。不必在意那個.h,並不是我的疏忽,程序保證可以編譯通過,只要你的C++編譯器支持標准C++規范的相關部分。你只需要把它們看作是一些普通的C++頭文件就可以了。事實上,也正是如此,如果你對這個變化細節感興趣的化,可以留意一下你身旁的佐餐。
同樣可以忽略第四行的存在。加入那個聲明只是為了表明程序引用到了std這個標准名字空間namespace),因為STL中的那些玩意兒全都包含在那裡面。只有通過這行聲明,編譯器才能允許你使用那些有趣的特性。
程序中用到了vector,它是STL中的一個標准容器,可以用來存放一些元素。你可以把vector理解為int [?],一個整型的數組。之所以大小未知是因為,vector是一個可以動態調整大小的容器,當容器已滿時,如果再放入元素則vector會悄悄擴大自己的容量。push_back是vector容器的一個類屬成員函數,用來在容器尾端插入一個元素。main函數中第一個while循環做的事情就是不斷向vector容器尾端插入整型數據,同時自動維護容器空間的大小。
sort是STL中的標准算法,用來對容器中的元素進行排序。它需要兩個參數用來決定容器中哪個范圍內的元素可以用來排序。這裡用到了vector的另兩個類屬成員函數。begin()用以指向vector的首端,而end()則指向vector的末端。這裡有兩個問題,begin()和end()的返回值是什麼?這涉及到STL的另一個重要部件--迭代器Iterator),不過這裡並不需要對它做詳細了解。你只需要把它當作是一個指針就可以了,一個指向整型數據的指針。相應的sort函數聲明也可以看作是void sort(int* first, int* last),盡管這實際上很不精確。
另一個問題是和end()函數有關,盡管前面說它的返回值指向vector的末端,但這種說法不能算正確。事實上,它的返回值所指向的是vector中最末端元素的後面一個位置,即所謂pass-the-end value。這聽起來有點費解,不過不必在意,這裡只是稍帶一提。總的來說,sort函數所做的事情是對那個准整型數組中的元素進行排序,一如第一個程序中的那個qsort,不過比起qsort來,sort似乎要簡單了許多。
程序的最後是輸出部分,在這裡vector完全可以以假亂真了,它所提供的對元素的訪問方式簡直和普通的C++內建數組一模一樣。那個size函數用來返回vector中的元素個數,就相當於第一個程序中的變量n。這兩行代碼直觀的不用我再多解釋了。
我想我的耐心講解應該可以使你大致看懂上面的程序了,事實上STL的運用使程序的邏輯更加清晰,使代碼更易於閱讀。試問,有誰會不明白begin、end、size這樣的字眼所表達的含義呢除非他不懂英語)?試著運行一下,看看效果。再試著多輸入幾個數,看看是否會發生數組越界現象。實踐證明,程序運行良好。是的,由於vector容器自行維護了自身的大小,C++程序員就不用操心動態內存分配了,指針的錯誤使用畢竟會帶來很多麻煩,同時程序也會變得冗長無比。這正是前面第三種方案的缺點所在。
再仔細審視一下你的第一個STL版的C++程序,回顧一下第一章所提到的那些有關STL的優點:易於使用,具有工業強度……,再比較一下第一版的程序,我想你應該有所體會了吧!
2.2.3 第三版:唯美主義的傑作
事態的發展有時候總會趨向極端,這在那些唯美主義者當中猶是如此。首先聲明,我並不是一個唯美主義者,提供第二版程序的改進版,完全是為了讓你更深刻的感受到STL的魅力所在。在看完第三版之後,你會強烈感受到這一點。或許你也會變成一個唯美主義者了,至少在STL方面。這應該不是我的錯,因為決定權在你手裡。下面我們來看看這個絕版的C++程序。
- // name:example2_3.cpp
- // alias:aesthetic version
- #include
- #include
- #include
- #include
- using namespace std;
- void main(void)
- {
- typedef vector int_vector;
- typedef istream_iterator istream_itr;
- typedef ostream_iterator ostream_itr;
- typedef back_insert_iterator< int_vector > back_ins_itr;
- // STL中的vector容器
- int_vector num;
- // 從標准輸入設備讀入整數,
- // 直到輸入的是非整型數據為止
- copy(istream_itr(cin), istream_itr(), back_ins_itr(num));
- // STL中的排序算法
- sort(num.begin(), num.end());
- // 將排序結果輸出到標准輸出設備
- copy(num.begin(), num.end(), ostream_itr(cout, "\n"));
- }
在這個程序裡幾乎每行代碼都是和STL有關的除了main和那對花括號,當然還有注釋),並且它包含了STL中幾乎所有的各大部件容器container,迭代器iterator, 算法algorithm, 適配器adaptor),唯一的遺憾是少了函數對象functor)的身影。
還記得開頭提到的一個典型系統所具有的基本特征嗎?--輸入+處理+輸出。所有這些功能,在上面的程序裡,僅僅是通過三行語句來實現的,其中每一行語句對應一種操作。對於數據的操作被高度的抽象化了,而算法和容器之間的組合,就像搭積木一樣輕松自如,系統的耦合度被降到了極低點。這就是閃耀著泛型之光的STL的偉大力量。如此簡潔,如此巧妙,如此神奇!就像魔術一般,以至於再一次讓你摸不著頭腦。怎麼實現的?為什麼在看第二版程序的時候如此清晰的你,又墜入了五裡霧中竊喜)。
請留意此處的標題唯美主義的傑作),在實際環境中,你未必要做到這樣完美。畢竟美好願望的破滅,在生活中時常會發生。過於理想化,並不是一件好事,至少我是這麼認為的。正如前面提到的,這個程序只是為了展示STL的獨特魅力,你不得不為它的出色表現所折服,也許只有深谙STL之道的人才會想出這樣的玩意兒來。如果你只是一般性的使用STL,做到第二版這樣的程度也就可以了。
實在是因為這個程序太過"簡單",以至於我無法肯定,在你還沒有完全掌握STL之前,通過我的講解,是否能夠領會這區區三行代碼,我將盡我的最大努力。
前面提到的迭代器可以對容器內的任意元素進行定位和訪問。在STL裡,這種特性被加以推廣了。一個cin代表了來自輸入設備的一段數據流,從概念上講它對數據流的訪問功能類似於一般意義上的迭代器,但是C++中的cin在很多地方操作起來並不像是一個迭代器,原因就在於其接口和迭代器的接口不一致比如:不能對cin進行++運算,也不能對之進行取值運算--即*運算)。為了解決這個矛盾,就需要引入適配器的概念。istream_iterator便是一個適配器,它將cin進行包裝,使之看起來像是一個普通的迭代器,這樣我們就可以將之作為實參傳給一些算法了比如這裡的copy算法)。
因為算法只認得迭代器,而不會接受cin。對於上面程序中的第一個copy函數而言,其第一個參數展開後的形式是:istream_iterator(cin),其第二個參數展開後的形式是:istream_iterator()如果你對typedef的語法不清楚,可以參考有關的c++語言書籍)。其效果是產生兩個迭代器的臨時對象,前一個指向整型輸入數據流的開始,後一個則指向"pass-the-end value"。這個函數的作用就是將整型輸入數據流從頭至尾逐一"拷貝"到vector這個准整型數組裡,第一個迭代器從開始位置每次累進,最後到達第二個迭代器所指向的位置。或許你要問,如果那個copy函數的行為真如我所說的那樣,為什麼不寫成如下這個樣子呢?
- copy(istream_iterator(cin), istream_iterator(), num.begin());
你確實可以這麼做,但是有一個小小的麻煩。還記得第一版程序裡的那個數組越界問題嗎?如果你這麼寫的話,就會遇到類似的麻煩。原因在於copy函數在"拷貝"數據的時候,如果輸入的數據個數超過了vector容器的范圍時,數據將會拷貝到容器的外面。此時,容器不會自動增長容量,因為這只是簡單地拷貝,並不是從末端插入。
為了解決這個問題,另一個適配器back_insert_iterator登場了,它的作用就是引導copy算法每次在容器末端插入一個數據。程序中的那個back_ins_itr(num)展開後就是:back_insert_iterator(num),其效果是生成一個這樣的迭待器對象。終於將講完了三分之一真不容易!),好在第二句和前一版程序沒有差別,這裡就略過了。
至於第三句,ostream_itr(cout, "\n")展開後的形式是:ostream_iterator(cout, "\n"),其效果是產生一個處理輸出數據流的迭待器對象,其位置指向數據流的起始處,並且以"\n"作為分割符。第二個copy函數將會從頭至尾將vector中的內容"拷貝"到輸出設備,第一個參數所代表的迭代器將會從開始位置每次累進,最後到達第二個參數所代表的迭代器所指向的位置。
這就是全部的內容。
2.3 歷史的評價
歷史的車輪總是滾滾向前的,工業時代的文明較之史前時代,當然是先進並且發達的。回顧那兩個時代的C++程序,你會真切的感受到這種差別。簡潔易用,具有工業強度,較好的可移植性,高效率,加之第三個令人目眩的絕版程序所體現出來的高度抽象性,高度靈活性和組件化特性,使你對STL背後所蘊含的泛型化思想都有了些微的感受。
真幸運,你可以橫跨兩個時代,有機會目睹這種"文明"的差異。同時,這也應該使你越加堅定信念,使自己順應時代的潮流。
2.4 如何運行
在你還沒有真正開始運行前面後兩個程序之前,最好先浏覽一下本節。這裡簡單介紹了在特定編譯器環境下運行STL程序的一些細節,並提供了一些可能遇到的問題的解決辦法。
此處,我選用了目前在Windows平台下較為常見的Microsoft Visual C++ 6.0和Borland C++ Builder 6.0作為例子。盡管Visual C++ 6.0對最新的ANSI/ISO C++標准支持的並不是很好。不過據稱Visual C++ .NET也就是VC7.0)在這方面的性能有所改善。
你可以選用多種方式運行前面的程序,比如在Visual C++下,你可以直接在DOS命令行狀態下編譯運行,也可以在VC的IDE下采用控制台應用程序Console Application)的方式運行。對於C++ Builder,情況也類似。
對於Visual C++而言,如果是在DOS命令行狀態下,你首先需要找到它的編譯器。假定你的Visual C++裝在C:\Program Files\Microsoft Visual Studio\VC98下面,則其編譯器所在路徑應該是C:\Program Files\Microsoft Visual Studio\VC98\Bin,在那裡你可以找到cl.exe文件。編譯時請加上/GX和/MT參數。如果一切正常,結果就會產生一個可執行文件。如下所示:
cl /GX /MT example2_2.cpp
前一個參數用於告知編譯器允許異常處理Exception Handling)。在P. J. Plauger STL中的很多地方使用了異常處理機制即try…throw…catch語法),所以應該加上這個參數,否則會有如下警告信息:
warning C4530: C++ exception handler used, but unwind semantics are not enabled.
後一個參數則用於使程序支持多線程,它需要在鏈接時使用LIBCMT.LIB庫文件。不過P. J. Plauger STL並不是線程安全的thread safety)。如果你是在VC環境下使用像STLport這樣的STL實現版本,則需要加上這個參數,因為STLport是線程安全的。
如果在IDE環境下,可以在新建工程的時候選擇控制台應用程序。
至於那些參數的設置,則可以通過在Project功能菜單項中的Settings功能Alt+F7】中設置編譯選項來完成。
有時,在IDE環境下編譯STL程序時,可能會出現如下警告信息前面那幾個示例程序不會出現這種情況):
warning C4786: '……' : identifier was truncated to '255' characters in the debug information
這是因為編譯器在Debug狀態下編譯時,把程序中所出現的標識符長度限制在了255個字符范圍內。如果超過最大長度,這些標識符就無法在調試階段查看和計算了。而在STL程序中大量的用到了模板函數和模板類,編譯器在實例化這些內容時,展開之後所產生的標識符往往很長沒准會有一千多個字符!)。如果你想認識一下這個warning的話,很簡單,在程序裡加上如下一行代碼:
- vector string_array; // 類似於字符串數組變量
對於這樣的warning,當然可以置之不理,不過也是有解決辦法的。 你可以在文件開頭加入下面這一行:#pragma warning(disable: 4786)。它強制編譯器忽略這個警告信息,這種做法雖然有點粗魯,但是很有效。
至於C++ Builder,其DOS命令行狀態下的運行方式是這樣的。假如你的C++ Builder裝在C:\Program Files\Borland\CBuilder6。則其編譯器所在路徑應該是C:\Program Files\ Borland\CBuilder6\Bin,在那裡你可以找到bcc32.exe文件,輸入如下命令,即大功告成了:
bcc32 example2_2.cpp
至於IDE環境下,則可以在新建應用程序的時候,選擇控制台向導Console Wizard)。
現在你可以在你的機器上運行前面的示例程序了。不過,請恕我多嘴,有些細節不得不提請你注意。小心編譯器給你留下的陷阱。比如前面第三個程序中有如下這一行代碼:
- typedef back_insert_iterator< int_vector > back_ins_itr;
請留意">"前面的空格,最好不要省去。如果你吝惜這點空格所占用的磁盤空間的話,那就太不劃算了。其原因還是在於C++編譯器本身的缺陷。上述代碼,相當於如下代碼編譯器做的也正是這樣的翻譯工作):
- typedef back_insert_iterator< vector > back_ins_itr;
如果你沒有加空格的話,編譯器會把">>"誤認為是單一標識看起來很像那個數據流輸入操作符">>")。為了回避這個難題,C++要求使用者必須在兩個右尖括號之間插入空格。所以,你最好還是老老實實照我的話做,以避免不必要的麻煩。不過有趣的是,對於上述那行展開前的代碼,在Visual C++裡即使你沒有加空格,編譯器也不會報錯。而同樣的代碼在C++ Builder中沒有那麼幸運了。不過,最好還是不要心存僥幸,如果你采用展開後的書寫方式,則兩個編譯器都不會給你留情面了。
好了,請原諒我的絮叨,現在你可以親身感受一下STL所帶給你的真正獨特魅力了,祝你好運!