ShowMeAI日報系列全新升級!覆蓋AI人工智能 工具&框架 | 項目&代碼 | 博文&分享 | 數據&資源 | 研究&論文 等方向。點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送。點擊 專題合輯&電子月刊 快速浏覽各專題全集。點擊 這裡 回復關鍵字 日報 免費獲取AI電子月刊與資料包。
https://github.com/cerlymarco/tspiral
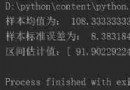
tspiral 直接為時間序列預測提供 scikit-learn 估計器,可以輕松地將復雜的時間序列預測問題映射到表格監督回歸任務中,然後使用標准方法解決問題。tspiral 提供了 4 種優化的預測技術:Recursive Forecasting、Direct Forecasting、Stacking Forecasting、Rectified Forecasting。
https://github.com/fastmachinelearning/hls4ml
https://fastmachinelearning.org/
hls4ml 使用高級合成語言(HLS)創建機器學習算法的固件實現,將傳統的開源機器學習包模型轉換為可針對用例進行配置的 HLS!
https://github.com/citrusvanilla/tinyflux
TinyFlux 是 TinyDB 的時間序列版本,也是用 Python 編寫的,沒有外部依賴性。它是小型分析工作流程和應用程序、家庭物聯網數據存儲的最佳伴侶。
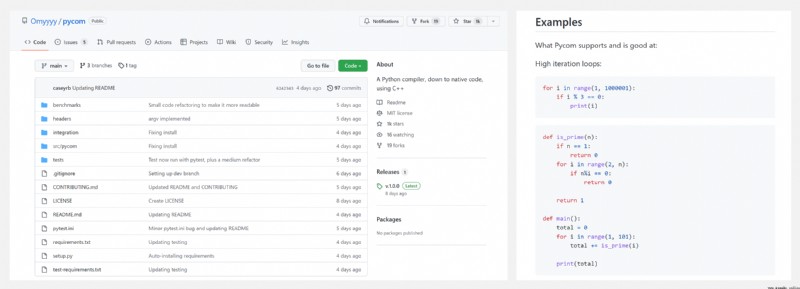
https://github.com/Omyyyy/pycom
雖然 Python 的許多優化大大提高了其運行速度,但 Python 無法生成獨立可執行文件,達不到C/C++ 的速度和可移植性水平,因此 Python 的運行速度是公認較慢的。Pycom 解決了這個問題。Pycom 實際上是 Python 代碼的編譯器,使用 C++ 作為『中間表示』,生成的獨立可執行文件是 Python 解釋速度的 20-30 倍。不過,當前版本還不能不支持所有版本的所有 Python 功能。
https://github.com/microsoft/Efficient-Large-LM-Trainer
https://github.com/jinfagang/AI-Infer-Engine-From-Zero
現在的很多開源推理引擎,大部分僅僅停留在“用工具”的層面,對於想掌握技術的本源是遠遠不夠的。作者將『自建AI推理引擎』相關的博客文章整理成一個索引,記錄了作者建造過程中踩過的坑,以及關於 C++語言、框架架構、算子推理設計、用戶體驗設計 的一些實踐和思考。

https://github.com/reanalytics-databoutique/webscraping-open-project
作者花費了幾年的時間,尋找收集爬蟲的『最佳實踐』(技術棧、工具和軟件等),以提升項目的可擴展性和維護效率,並為 Python 網絡爬蟲社區建立一個參考點。

https://github.com/Ying1123/awesome-neural-symbolic
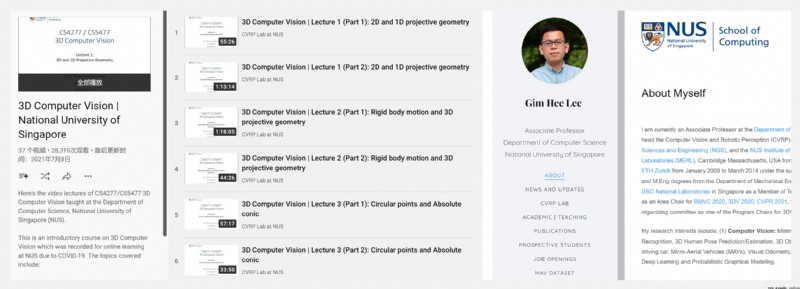
https://www.youtube.com/playlist?list=PLxg0CGqViygP47ERvqHw_v7FVnUovJeaz
這是一門關於 3D 計算機視覺的入門課程,包含的主題包括:
- 2D and 1D projective geometry / 二維和一維投射幾何學
- Rigid body motion and 3D projective geometry / 剛體運動和三維投射幾何學
- Circular points and Absolute conic / 圓點和絕對圓錐體
- Robust homography estimation / 穩健的同構圖估計
- Camera models and calibration / 相機模型和校准
- Single view metrology / 單視圖計量學
- The fundamental and essential matrices / 基本和重要矩陣
- Absolute pose estimation from points or lines / 從點或線進行絕對姿態估計
- Three-view geometry from points and/or lines / 基於點和/或線的三視圖幾何學
- Structure-from-Motion (SfM) and bundle adjustment / 從運動中產生的結構(SfM)和捆綁調整
- Two-view and multi-view stereo / 雙視角和多視角立體圖
- Generalized cameras / 通用相機
- Auto-Calibration / 自動校准

可以點擊 這裡 回復關鍵字日報,免費獲取整理好的論文合輯。
科研進展
- 2022.07.18 『機器學習』 Why do tree-based models still outperform deep learning on tabular data?
- 2022.07.19 『計算機視覺』 PoserNet: Refining Relative Camera Poses Exploiting Object Detections
- 2022.07.21 『計算機視覺』 AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection
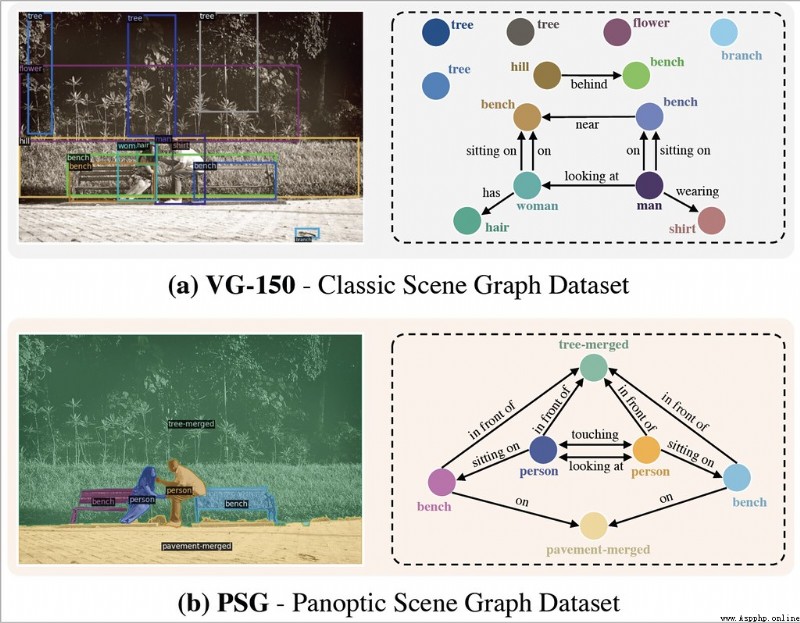
- 2022.07.18 『計算機視覺』 Panoptic Scene Graph Generation
論文時間:18 Jul 2022
所屬領域:機器學習
對應任務:結構化數據建模
論文地址:https://arxiv.org/abs/2207.08815
代碼實現:https://github.com/leogrin/tabular-benchmark
論文作者:Léo Grinsztajn, Edouard Oyallon, Gaël Varoquaux
論文簡介:While deep learning has enabled tremendous progress on text and image datasets, its superiority on tabular data is not clear./雖然深度學習在文本和圖像數據集上取得了巨大的進展,但它在結構化表格數據上的優勢並不明顯。
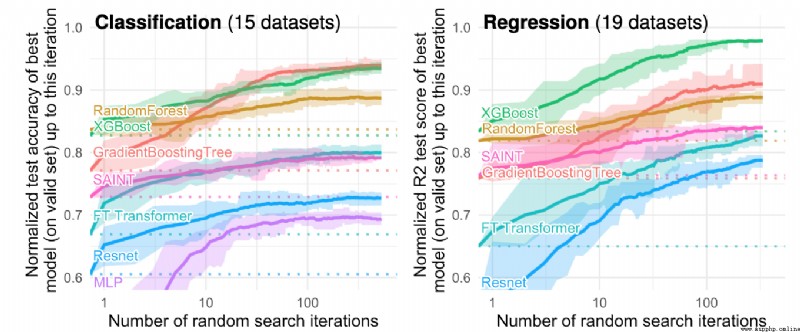
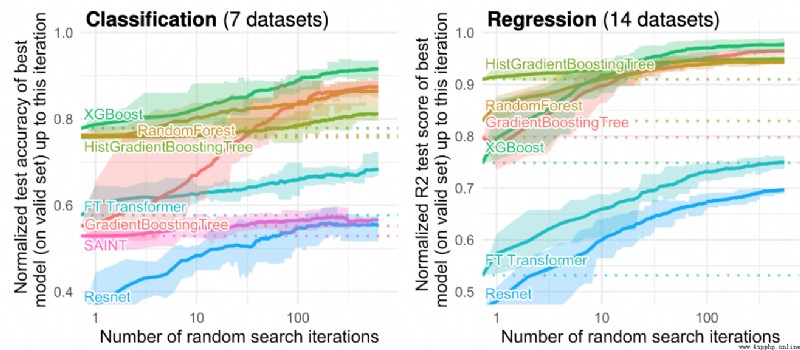
論文摘要:雖然深度學習在文本和圖像數據集上取得了巨大的進展,但它在結構化表格數據上的優勢並不明顯。我們為標准和新型的深度學習方法以及基於樹的模型,如XGBoost和Random Forests,在大量的數據集和超參數組合中提供了廣泛的基准。我們定義了一套標准的45個數據集,這些數據集來自不同的領域,具有明顯的結構化表格數據的特征,並且有一套基准測試方法,既考慮了模型的擬合,也考慮了找到好的超參數。結果表明,即使不考慮其優越的速度,基於樹的模型在中等規模的數據(∼10K樣本)上仍然是最先進的。為了理解這一差距,我們對基於樹的模型和神經網絡(NN)的不同歸納偏見進行了實證調查。這導致了一系列的挑戰,這些挑戰應該指導旨在建立結構化數據專用NN的研究人員。1.對無信息的特征具有魯棒性,2.保持數據的方向性,3.能夠輕松學習不規則的函數。為了促進結構化表格架構的研究,我們貢獻了一個標准的基准和基線的原始數據:每個學習器的20000個計算小時的超參數搜索的每個點。
論文時間:19 Jul 2022
所屬領域:計算機視覺
對應任務:Pose Estimation,姿態檢測,姿態預估
論文地址:https://arxiv.org/abs/2207.09445
代碼實現:https://github.com/iit-pavis/posernet
論文作者:Matteo Taiana, Matteo Toso, Stuart James, Alessio Del Bue
論文簡介:The estimation of the camera poses associated with a set of images commonly relies on feature matches between the images./與一組圖像相關的相機姿態的估計通常依賴於圖像之間的特征匹配。
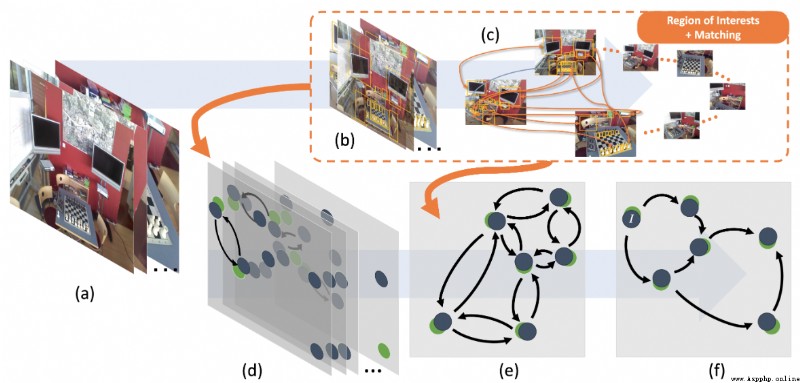
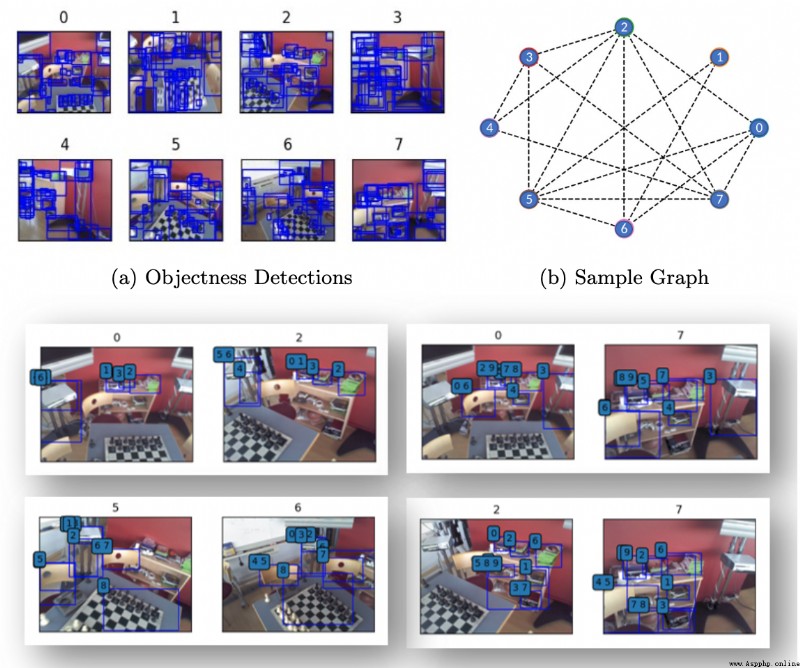
論文摘要:與一組圖像相關的相機姿態的估計通常依賴於圖像之間的特征匹配。相比之下,我們是第一個通過使用對象性區域來指導姿勢估計問題而不是明確的語義對象檢測來解決這一挑戰的。我們提出了Pose Refiner Network (PoserNet),這是一個輕量級的圖神經網絡,用於完善近似的成對相對相機姿勢。PoserNet利用對象性區域之間的關聯–簡明地表示為邊界框–跨越多個視圖,以全局性地細化稀疏連接的視圖圖。我們在7-Scenes數據集上評估了不同大小的圖,並展示了這一過程如何有利於基於優化的運動平均算法,與基於邊界框獲得的初始估計相比,旋轉的中位誤差提高了62度。代碼和數據可在https://github.com/IIT-PAVIS/PoserNet獲取。
論文時間:21 Jul 2022
所屬領域:計算機視覺
對應任務:3D Object Detection,Autonomous Driving,object-detection,Object Detection,目標檢測,無人駕駛
論文地址:https://arxiv.org/abs/2207.10316
代碼實現:https://github.com/zehuichen123/autoalignv2
論文作者:Zehui Chen, Zhenyu Li, Shiquan Zhang, Liangji Fang, Qinhong Jiang, Feng Zhao
論文簡介:Recently, AutoAlign presents a learnable paradigm in combining these two modalities for 3D object detection./最近,AutoAlign提出了一種可學習的范式,將這兩種模式結合起來進行三維物體檢測。
論文摘要:點雲和RGB圖像是自主駕駛中的兩個通用感知源。前者可以提供物體的准確定位,後者的語義信息更密集、更豐富。最近,AutoAlign提出了一種可學習的范式,將這兩種模式結合起來進行三維物體檢測。然而,它受到了全局性注意力所帶來的高計算成本的影響。為了解決這個問題,我們在這項工作中提出了跨域變形CAFA模塊。它關注跨模態關系建模的稀疏可學習采樣點,這增強了對校准誤差的容忍度,並大大加快了不同模態的特征聚合。為了克服多模態環境下復雜的GT-AUG,我們設計了一個簡單而有效的跨模態增強策略,即考慮到圖像patches的深度信息,對其進行凸組合。此外,通過執行一個新的圖像級別的dropout訓練方案,我們的模型能夠以動態的方式進行推斷。為此,我們提出了AutoAlignV2,一個建立在AutoAlign之上的更快、更強的多模態三維檢測框架。在nuScenes基准上進行的大量實驗證明了AutoAlignV2的有效性和效率。值得注意的是,我們的最佳模型在nuScenes測試排行榜上達到了72.4 NDS,在所有已發表的多模態3D物體檢測器中取得了新的最先進的結果。代碼將在https://github.com/zehuichen123/AutoAlignV2發布。
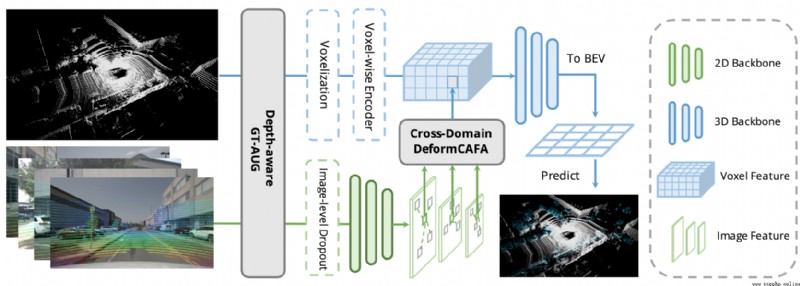
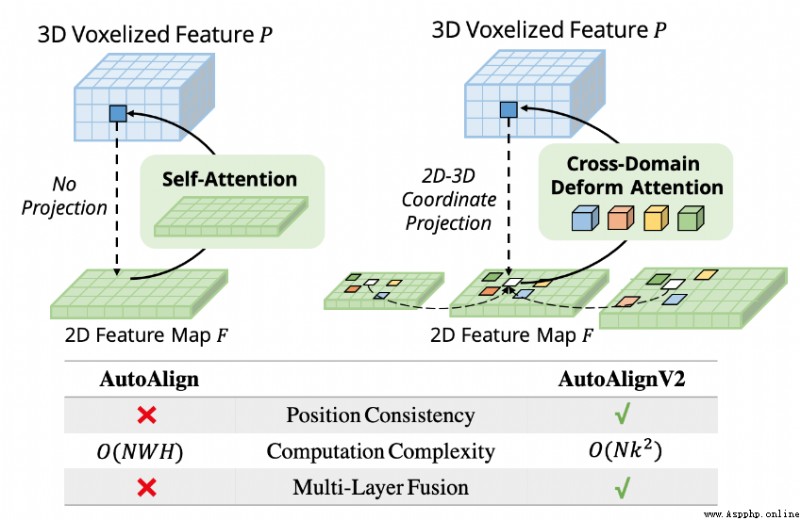
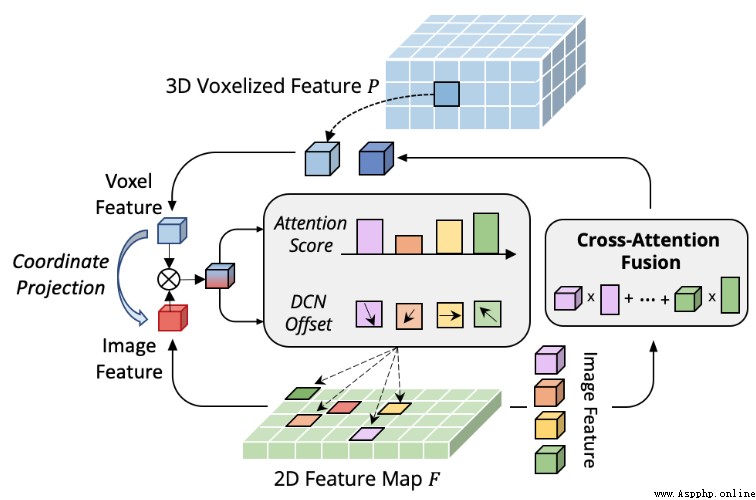
論文時間:22 Jul 2022
所屬領域:計算機視覺
對應任務:Panoptic Scene Graph Generation,Scene Graph Generation,Scene Understanding,全景場景圖生成,場景圖生成,場景理解
論文地址:https://arxiv.org/abs/2207.11247
代碼實現:https://github.com/Jingkang50/OpenPSG
論文作者:Jingkang Yang, Yi Zhe Ang, Zujin Guo, Kaiyang Zhou, Wayne Zhang, Ziwei Liu
論文簡介:Existing research addresses scene graph generation (SGG) – a critical technology for scene understanding in images – from a detection perspective, i. e., objects are detected using bounding boxes followed by prediction of their pairwise relationships./現有的研究從檢測的角度解決了場景圖生成(SGG)–圖像中場景理解的一項關鍵技術,即使用邊界框檢測物體,然後預測它們的配對關系。
論文摘要:現有的研究從檢測的角度來解決場景圖生成(SGG)–圖像中場景理解的一項關鍵技術,即使用邊界框檢測物體,然後預測它們的成對關系。我們認為,這樣的范式導致了一些問題,阻礙了該領域的發展。例如,當前數據集中基於邊界框的標簽通常包含像毛發這樣的冗余類,並遺漏了對理解背景至關重要的背景信息。在這項工作中,我們引入了全景場景圖生成(PSG),這是一個新的問題任務,要求模型在全景分割的基礎上生成一個更全面的場景圖表示,而不是剛性的邊界框。我們創建了一個高質量的PSG數據集,其中包含來自COCO和Visual Genome的49k個注釋良好的重疊圖像,供社區跟蹤其進展。為了進行基准測試,我們建立了四個兩階段基線,這些基線是根據SGG的經典方法修改的,還有兩個單階段基線,稱為PSGTR和PSGFormer,它們是基於高效的基於Transformer的檢測器,即DETR。PSGTR使用一組查詢來直接學習三聯體,而PSGFormer則以兩個Transformer解碼器的查詢形式分別對對象和關系進行建模,然後采用類似提示的關系-對象匹配機制。最後,我們談及對開放性挑戰和未來方向的一些想法。
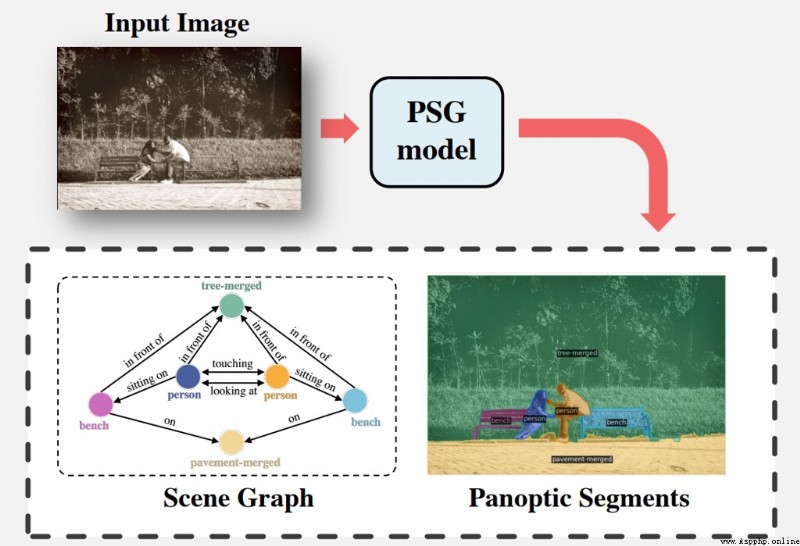
我們是 ShowMeAI,致力於傳播AI優質內容,分享行業解決方案,用知識加速每一次技術成長!點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送。點擊 專題合輯&電子月刊 快速浏覽各專題全集。點擊 這裡 回復關鍵字 日報 免費獲取AI電子月刊與資料包。