在本周的視頻中,你學習了如何將深度學習應用於語音識別。在此作業中,你將構建語音數據集並實現用於關鍵詞檢測(有時也稱為喚醒詞或觸發詞檢測)的算法。關鍵詞識別是一項技術,可讓諸如Amazon Alexa,Google Home,Apple Siri和Baidu DuerOS之類的設備在聽到某個特定單詞時回應。
對於本練習,我們的觸發詞將是"Activate."。每次聽到你說“激活”時,它都會發出“蜂鳴聲”。作業完成後,你將可以錄制自己的講話片段,並在算法檢測到你說"Activate"時觸發提示音。
完成此任務後,也許你還可以將其擴展為在筆記本電腦上運行,以便每次你說“Activate”時,它就會啟動你喜歡的應用程序,或者打開房屋中的網絡連接燈,或觸發其他事件?
在本作業中,你將學習:
import numpy as np
from pydub import AudioSegment
import random
import sys
import io
import os
import glob
import IPython
from td_utils import *
%matplotlib inline
d:\vr\virtual_environment\lib\site-packages\pydub\utils.py:165: RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work
warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)
讓我們從為觸發詞檢測算法構建數據集開始。語音數據集在理想情況下應盡可能接近要在其上運行它的應用程序。在這種情況下,你想在工作環境(圖書館,家庭,辦公室,開放空間…)中檢測到"activate"一詞。因此,你需要在不同的背景聲音上混合使用positive詞(“activate”)和negative詞(除activate以外的隨機詞)來創建錄音。讓我們看看如何創建這樣的數據集。
你的一位朋友正在幫助你完成這個項目,他們去了該地區各地的圖書館,咖啡館,餐館,家庭和辦公室,以記錄背景噪音以及人們說positive/negative詞的音頻片段。該數據集包括以各種口音講話的人。
在raw_data目錄中,你可以找到原始音頻文件的子集,包括正詞,負詞和背景噪音。你將使用這些音頻文件來合成數據集以訓練模型。"activate"目錄包含人們說"activate"一詞的正面示例。"negatives"目錄包含人們說"activate"以外的隨機單詞的否定示例。每個音頻記錄只有一個字。"backgrounds"目錄包含10秒的不同環境下的背景噪音片段。
運行下面的單元格以試聽一些示例。
IPython.display.Audio("./raw_data/activates/1.wav")
CSDN不支持播放音頻
IPython.display.Audio("./raw_data/negatives/4.wav")
CSDN不支持播放音頻
IPython.display.Audio("./raw_data/backgrounds/1.wav")
CSDN不支持播放音頻
你將使用這三種類型的記錄(positives/negatives/backgrounds)來創建標記的數據集。
錄音到底是什麼?麥克風記錄隨時間變化很小的氣壓,而這些氣壓的微小變化也會使你的耳朵感覺到聲音。你可以認為錄音是一長串數字,用於測量麥克風檢測到的氣壓變化很小。我們將使用以44100Hz(或44100赫茲)采樣的音頻。這意味著麥克風每秒可以為我們提供44100個號碼。因此,一個10秒的音頻剪輯由441000個數字表示(= 10 × 44100 10 \times 44100 10×44100)。
從音頻的這種“原始”表示中很難弄清是否說了"activate"這個詞。為了幫助你的序列模型更輕松地學習檢測觸發詞,我們將計算音頻的spectrogram。頻譜圖告訴我們音頻片段在某個時刻存在多少不同的頻率。
(如果你曾經在信號處理或傅立葉變換方面上過高級課程,則可以通過在原始音頻信號上滑動一個窗口來計算頻譜圖,並使用傅立葉變換來計算每個窗口中最活躍的頻率。如果你不理解前面的句子,也不用擔心。)
讓我們來看一個例子。
IPython.display.Audio("audio_examples/example_train.wav")
CSDN不支持播放音頻
x = graph_spectrogram("audio_examples/example_train.wav")

上圖表示在多個時間步長(x軸)上每個頻率(y軸)的活躍程度。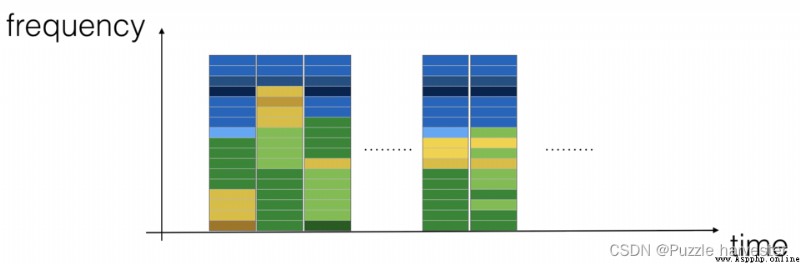
圖1:錄音的頻譜圖,其中的顏色表示在不同的時間點音頻中不同頻率出現(響亮)的程度。綠色方塊表示某個頻率在音頻剪輯(揚聲器)中更活躍或更活躍。藍色方塊表示較不活躍的頻率。
輸出頻譜圖的尺寸取決於頻譜圖軟件的超參數和輸入的長度。在此筆記本中,我們將使用10秒的音頻剪輯作為訓練示例的“標准長度”。頻譜圖的時間步數為5511。稍後你將看到頻譜圖將是網絡中的輸入 x x x,因此 T x = 5511 T_x=5511 Tx=5511。
_, data = wavfile.read("audio_examples/example_train.wav")
print("Time steps in audio recording before spectrogram", data[:,0].shape)
print("Time steps in input after spectrogram", x.shape)
Time steps in audio recording before spectrogram (441000,)
Time steps in input after spectrogram (101, 5511)
現在,你可以定義:
Tx = 5511 # 從頻譜圖輸入到模型的時間步數
n_freq = 101 # 在頻譜圖的每個時間步輸入模型的頻率數
請注意,即使將10秒作為我們的默認訓練示例長度,也可以將10秒的時間離散化為不同數量的值。你已經看到441000(原始音頻)和5511(頻譜圖)。在前一種情況下,每個步驟代表 10 / 441000 ≈ 0.000023 10/441000 \approx 0.000023 10/441000≈0.000023秒。在第二種情況下,每個步驟代表 10 / 5511 ≈ 0.0018 10/5511 \approx 0.0018 10/5511≈0.0018秒。
對於10秒的音頻,你將在此作業中看到的關鍵值為:
請注意,這些表示中的每個表示都恰好對應10秒的時間。只是他們在不同程度上離散化了他們。所有這些都是超參數,可以更改(441000除外,這是麥克風函數)。我們選擇的值在語音系統使用的標准范圍內。
上面的 T y = 1375 T_y=1375 Ty=1375數字意味著對於模型的輸出,我們將10s離散為1375個時間間隔(每個時間間隔的長度為 10 / 1375 ≈ 0.0072 10/1375 \approx 0.0072 10/1375≈0.0072秒),並嘗試針對每個時間間隔預測是否有人最近說完“activate”。
上面的10000對應於將10秒剪輯離散化為10/10000 = 0.001秒迭代。0.001秒也稱為1毫秒或1ms。因此,當我們說要按照1ms的間隔離散時,這意味著我們正在使用10,000個步長。
Ty = 1375 # 我們模型輸出中的時間步數
由於語音數據很難獲取和標記,因此你將使用激活,否定和背景的音頻片段來合成訓練數據。錄制很多帶有隨機"activates"內容的10秒音頻剪輯非常慢。取而代之的是,錄制許多肯定詞和否定詞以及分別記錄背景噪音(或從免費的在線資源下載背景噪音)會變得更加容易。
要合成一個訓練示例,你將:
因為你已經將"activates"一詞合成到了背景剪輯中,所以你確切知道"activates"在10秒剪輯中何時出現。稍後你將看到,這也使得生成標簽 y * t * y^{\langle t \rangle} y*t* 更加容易。
你將使用pydub包來處理音頻。Pydub將原始音頻文件轉換為Pydub數據結構的列表(在此處了解詳細信息並不重要)。Pydub使用1毫秒作為離散時間間隔(1毫秒等於1毫秒= 1/1000秒),這也是為什麼始終以10,000步表示10秒剪輯的原因。
# 使用pydub加載音頻片段
activates, negatives, backgrounds = load_raw_audio()
print("background len: " + str(len(backgrounds[0]))) # 應該是10,000,因為它是一個10秒的剪輯
print("activate[0] len: " + str(len(activates[0]))) # 也許大約1000,因為 "activate" 音頻剪輯通常大約1秒(但變化很大)
print("activate[1] len: " + str(len(activates[1]))) # 不同的 "activate" 剪輯可以具有不同的長度
background len: 10000
activate[0] len: 721
activate[1] len: 731
在背景上疊加正/負詞:
給定一個10秒的背景剪輯和一個簡短的音頻剪輯(positive or negative word),你需要能夠將單詞的簡短音頻剪輯“添加”或“插入”到背景上。為確保插入背景的音頻片段不重疊,你將跟蹤以前插入的音頻片段的時間。你將在背景中插入多個正/負詞剪輯,而又不想在與先前添加的另一個剪輯重疊的位置插入"activate"或隨機詞。
為了清楚起見,當你在10秒的咖啡館噪音片段中插入1秒的 “activate” 時,你最終會得到一個10秒的片段,聽起來像有人在咖啡館中說 “activate”,背景咖啡館噪音中疊加了 “activate” 。注意你沒有以11秒的剪輯結尾。稍後你將看到pydub如何幫助你執行此操作。
在疊加的同時創建標簽:
還記得標簽 y * t * y^{\langle t \rangle} y*t*代表某人是否剛剛說完"activate.“。給定一個背景剪輯,我們可以為所有 t t t初始化 y * t * = 0 y^{\langle t \rangle}=0 y*t*=0,因為該剪輯不包含任何"activates.”。
當插入或覆蓋"activate"剪輯時,還將更新 y * t * y^{\langle t \rangle} y*t*的標簽,以便輸出的50個步驟現在具有目標標簽1。你將訓練GRU來檢測何時某人完成說"activate"。例如,假設合成的"activate"剪輯在10秒音頻中的5秒標記處結束-恰好在剪輯的一半處。回想一下 T y = 1375 T_y=1375 Ty=1375,因此時間步長$687 = $ int(1375*0.5)對應於進入音頻5秒的時刻。因此,你將設置 y * 688 * = 1 y^{\langle 688 \rangle} = 1 y*688*=1。此外,如果GRU在此刻之後的短時間內(在內部)在任何地方檢測到"activate",你將非常滿意,因此我們實際上將標簽 y * t * y^{\langle t \rangle} y*t*的50個連續值設置為1。我們有 y * 688 * = y * 689 * = ⋯ = y * 737 * = 1 y^{\langle 688 \rangle} = y^{\langle 689 \rangle} = \cdots = y^{\langle 737 \rangle} = 1 y*688*=y*689*=⋯=y*737*=1。
這是合成訓練數據的另一個原因:如上所述,生成這些標簽 y * t * y^{\langle t \rangle} y*t*相對簡單。相反,如果你在麥克風上錄制了10秒的音頻,那麼一個人收聽它並在 “activate” 完成時准確手動進行標記會非常耗時。
下圖顯示了標簽 y * t * y^{\langle t \rangle} y*t*,對於我們插入了"activate", “innocent”,activate", "baby"的剪輯,請注意,正標簽“1”是關聯的只用positive的詞。
圖2
要實現合成訓練集過程,你將使用以下幫助函數。所有這些函數將使用1ms的離散時間間隔,因此將10秒的音頻離散化為10,000步。
get_random_time_segment(segment_ms)在我們的背景音頻中獲得隨機的時間段is_overlapping(segment_time,existing_segments)檢查時間段是否與現有時間段重疊insert_audio_clip(background,audio_clip,existing_times)使用get_random_time_segment和is_overlapping在我們的背景音頻中隨機插入一個音頻片段。insert_ones(y,segment_end_ms)在我們的標簽向量y的"activate"詞之後插入1。函數get_random_time_segment(segment_ms)返回一個隨機的時間段,我們可以在其中插入持續時間為segment_ms的音頻片段。 通讀代碼以確保你了解它在做什麼。
def get_random_time_segment(segment_ms):
""" 獲取 10,000 ms音頻剪輯中時間長為 segment_ms 的隨機時間段。 參數: segment_ms -- 音頻片段的持續時間,以毫秒為單位("ms" 代表 "毫秒") 返回: segment_time -- 以ms為單位的元組(segment_start,segment_end) """
segment_start = np.random.randint(low=0, high=10000-segment_ms) # 確保段不會超過10秒背景
segment_end = segment_start + segment_ms - 1
return (segment_start, segment_end)
接下來,假設你在(1000,1800)和(3400,4500)段插入了音頻剪輯。即第一個片段開始於1000步,結束於1800步。現在,如果我們考慮在(3000,3600)插入新的音頻剪輯,這是否與先前插入的片段之一重疊?在這種情況下,(3000,3600)和(3400,4500)重疊,因此我們應該決定不要在此處插入片段。
出於此函數的目的,將(100,200)和(200,250)定義為重疊,因為它們在時間步200處重疊。但是,(100,199)和(200,250)是不重疊的。
練習:實現is_overlapping(segment_time,existing_segments)來檢查新的時間段是否與之前的任何時間段重疊。你需要執行2個步驟:
previous_segments的開始和結束時間。將這些時間與細分的開始時間和結束時間進行比較。如果存在重疊,請將(1)中定義的標志設置為True。你可以使用:for ....:
if ... <= ... and ... >= ...:
...
提示:如果該段在上一個段結束之前開始,並且該段在上一個段開始之後結束,則存在重疊。
# GRADED FUNCTION: is_overlapping
def is_overlapping(segment_time, previous_segments):
""" 檢查段的時間是否與現有段的時間重疊。 參數: segment_time -- 新段的元組(segment_start,segment_end) previous_segments -- 現有段的元組列表(segment_start,segment_end) 返回: 如果時間段與任何現有段重疊,則為True,否則為False """
segment_start, segment_end = segment_time
# 第一步:將重疊標識 overlap 初始化為“False”標志 (≈ 1 line)
overlap = False
# 第二步:循環遍歷 previous_segments 的開始和結束時間。
# 比較開始/結束時間,如果存在重疊,則將標志 overlap 設置為True (≈ 3 lines)
for previous_start, previous_end in previous_segments:
if segment_start <= previous_end and segment_end >= previous_start:
overlap = True
return overlap
overlap1 = is_overlapping((950, 1430), [(2000, 2550), (260, 949)])
overlap2 = is_overlapping((2305, 2950), [(824, 1532), (1900, 2305), (3424, 3656)])
print("Overlap 1 = ", overlap1)
print("Overlap 2 = ", overlap2)
Overlap 1 = False
Overlap 2 = True
現在,讓我們使用以前的輔助函數在10秒鐘的隨機時間將新的音頻片段插入到背景中,但是要確保任何新插入的片段都不會與之前的片段重疊。
練習:實現insert_audio_clip()以將音頻片段疊加到背景10秒片段上。你將需要執行4個步驟:
# GRADED FUNCTION: insert_audio_clip
def insert_audio_clip(background, audio_clip, previous_segments):
""" 在隨機時間步驟中在背景噪聲上插入新的音頻片段,確保音頻片段與現有片段不重疊。 參數: background -- 10秒背景錄音。 audio_clip -- 要插入/疊加的音頻剪輯。 previous_segments -- 已放置的音頻片段的時間 返回: new_background -- 更新的背景音頻 """
# 以ms為單位獲取音頻片段的持續時間
segment_ms = len(audio_clip)
# 第一步:使用其中一個輔助函數來選擇要插入的隨機時間段
# 新的音頻剪輯。 (≈ 1 line)
segment_time = get_random_time_segment(segment_ms)
# 第二步:檢查新的segment_time是否與previous_segments之一重疊。
# 如果重疊如果是這樣,請繼續隨機選擇新的 segment_time 直到它不重疊。(≈ 2 lines)
while is_overlapping(segment_time, previous_segments):
segment_time = get_random_time_segment(segment_ms)
# 第三步: 將新的 segment_time 添加到 previous_segments 列表中 (≈ 1 line)
previous_segments.append(segment_time)
# 第四步: 疊加音頻片段和背景
new_background = background.overlay(audio_clip, position = segment_time[0])
return new_background, segment_time
np.random.seed(5)
audio_clip, segment_time = insert_audio_clip(backgrounds[0], activates[0], [(3790, 4400)])
audio_clip.export("insert_test.wav", format="wav")
print("Segment Time: ", segment_time)
IPython.display.Audio("insert_test.wav")
Segment Time: (2915, 3635)
CSDN不支持播放音頻
# 預期的音頻
IPython.display.Audio("audio_examples/insert_reference.wav")
CSDN不支持播放音頻
最後,假設你剛剛插入了"activate." ,則執行代碼以更新標簽 y * t * y^{\langle t \rangle} y*t*。在下面的代碼中,由於 T y = 1375 T_y=1375 Ty=1375,所以y是一個 (1,1375)維向量。
如果"activate"在時間步驟 t t t結束,則設置 y * t + 1 * = 1 y^{\langle t+1 \rangle} = 1 y*t+1*=1以及最多49個其他連續值。但是,請確保你沒有用完數組的末尾並嘗試更新y[0][1375],由於 T y = 1375 T_y=1375 Ty=1375,所以有效索引是y[0][0]至y[0][1374]。因此,如果"activate" 在1370步結束,則只會得到y[0][1371] = y[0][1372] = y[0][1373] = y[0][1374] = 1
練習:實現insert_ones()。你可以使用for循環。(如果你是python的slice運算的專家,請隨時使用切片對此向量化。)如果段以segment_end_ms結尾(使用10000步離散化),請將其轉換為輸出 y y y的索引(使用 1375 1375 1375步離散化),我們將使用以下公式:
segment_end_y = int(segment_end_ms * Ty / 10000.0)
# GRADED FUNCTION: insert_ones
def insert_ones(y, segment_end_ms):
""" 更新標簽向量y。段結尾的後面50個輸出的標簽應設為 1。 嚴格來說,我們的意思是 segment_end_y 的標簽應該是 0,而隨後的50個標簽應該是1。 參數: y -- numpy數組的維度 (1, Ty), 訓練樣例的標簽 segment_end_ms -- 以ms為單位的段的結束時間 返回: y -- 更新標簽 """
# 背景持續時間(以頻譜圖時間步長表示)
segment_end_y = int(segment_end_ms * Ty / 10000.0)
# 將1添加到背景標簽(y)中的正確索引
for i in range(segment_end_y + 1, segment_end_y + 51):
if i < Ty:
y[0, i] = 1
return y
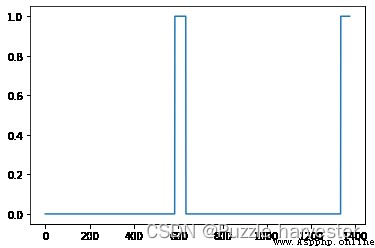
arr1 = insert_ones(np.zeros((1, Ty)), 9700)
plt.plot(insert_ones(arr1, 4251)[0,:])
print("sanity checks:", arr1[0][1333], arr1[0][634], arr1[0][635])
sanity checks: 0.0 1.0 0.0
最後,你可以使用insert_audio_clip和insert_ones來創建一個新的訓練示例。
練習:實現create_training_example()。你需要執行以下步驟:
# GRADED FUNCTION: create_training_example
def create_training_example(background, activates, negatives):
""" 創建具有給定背景,正例和負例的訓練示例。 參數: background -- 10秒背景錄音 activates -- "activate" 一詞的音頻片段列表 negatives -- 不是 "activate" 一詞的音頻片段列表 返回: x -- 訓練樣例的頻譜圖 y -- 頻譜圖的每個時間步的標簽 """
# 設置隨機種子
np.random.seed(18)
# 讓背景更安靜
background = background - 20
# 第一步:初始化 y (標簽向量)為0 (≈ 1 line)
y = np.zeros((1, Ty))
# 第二步:將段時間初始化為空列表 (≈ 1 line)
previous_segments = []
# 從整個 "activate" 錄音列表中選擇0-4隨機 "activate" 音頻片段
number_of_activates = np.random.randint(0, 5)
random_indices = np.random.randint(len(activates), size=number_of_activates)
random_activates = [activates[i] for i in random_indices]
# 第三步: 循環隨機選擇 "activate" 剪輯插入背景
for random_activate in random_activates:
# 插入音頻剪輯到背景
background, segment_time = insert_audio_clip(background, random_activate, previous_segments)
# 從 segment_time 中取 segment_start 和 segment_end
segment_start, segment_end = segment_time
# 在 "y" 中插入標簽
y = insert_ones(y, segment_end_ms=segment_end)
# 從整個負例錄音列表中隨機選擇0-2個負例錄音
number_of_negatives = np.random.randint(0, 3)
random_indices = np.random.randint(len(negatives), size=number_of_negatives)
random_negatives = [negatives[i] for i in random_indices]
# 第四步: 循環隨機選擇負例片段並插入背景中
for random_negative in random_negatives:
# 插入音頻剪輯到背景
background, _ = insert_audio_clip(background, random_negative, previous_segments)
# 標准化音頻剪輯的音量
background = match_target_amplitude(background, -20.0)
# 導出新的訓練樣例
file_handle = background.export("train" + ".wav", format="wav")
print("文件 (train.wav) 已保存在您的目錄中。")
# 獲取並繪制新錄音的頻譜圖(正例和負例疊加的背景)
x = graph_spectrogram("train.wav")
return x, y
x, y = create_training_example(backgrounds[0], activates, negatives)
文件 (train.wav) 已保存在您的目錄中。
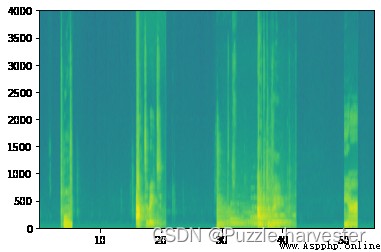
現在,您可以聆聽您創建的訓練示例,並將其與上面生成的頻譜圖進行比較。
IPython.display.Audio("train.wav")
CSDN不支持播放音頻
IPython.display.Audio("audio_examples/train_reference.wav")
CSDN不支持播放音頻
最後,你可以為生成的訓練示例繪制關聯的標簽。
plt.plot(y[0])
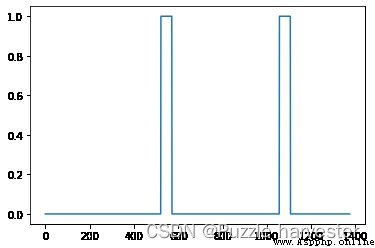
現在,你已經實現了生成單個訓練示例所需的代碼。我們使用此過程生成了大量的訓練集。為了節省時間,我們已經生成了一組訓練示例。
# 加載預處理的訓練樣例
X = np.load("./XY_train/X.npy")
Y = np.load("./XY_train/Y.npy")
為了測試我們的模型,我們記錄了包含25個示例的開發集。在合成訓練數據的同時,我們希望使用與實際輸入相同的分布來創建開發集。因此,我們錄制了25個10秒鐘的人們說"activate"和其他隨機單詞的音頻剪輯,並手動標記了它們。這遵循課程3中描述的原則,即我們應該將開發集創建為與測試集盡可能相似。這就是為什麼我們的開發人員使用真實音頻而非合成音頻的原因。
# 加載預處理開發集示例
X_dev = np.load("./XY_dev/X_dev.npy")
Y_dev = np.load("./XY_dev/Y_dev.npy")
現在,你已經建立了數據集,讓我們編寫和訓練關鍵字識別模型!
該模型將使用一維卷積層,GRU層和密集層。讓我們加載在Keras中使用這些層的軟件包。加載可能需要一分鐘。
from keras.callbacks import ModelCheckpoint
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking, TimeDistributed, LSTM, Conv1D
from keras.layers import GRU, Bidirectional, BatchNormalization, Reshape
from keras.optimizers import Adam
Using TensorFlow backend.
這是我們將使用的模型架構。花一些時間查看模型,看看它是否合理。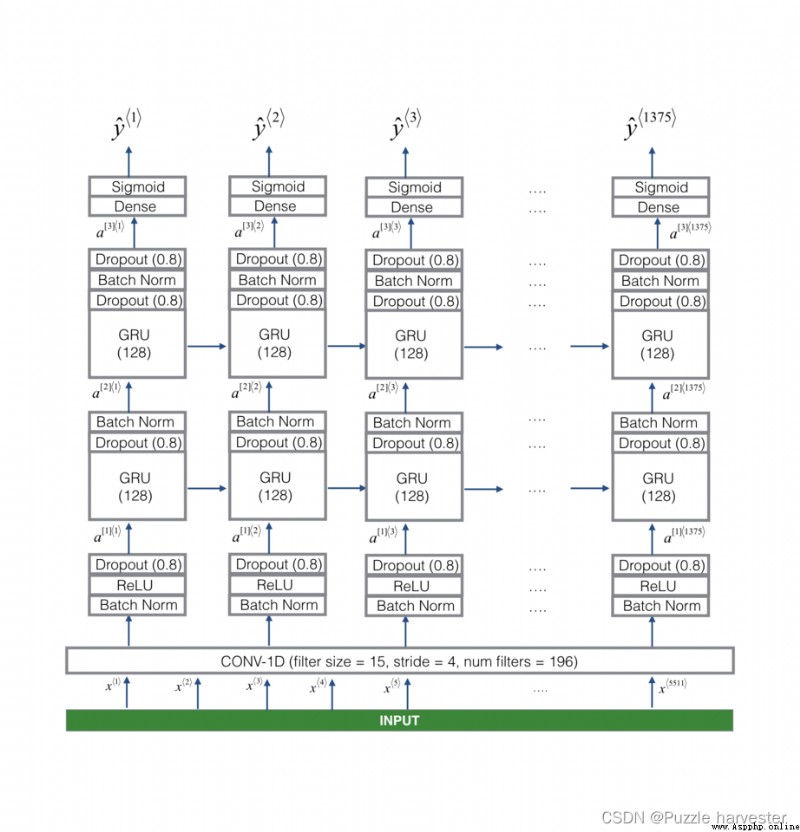
圖3
該模型的一個關鍵步驟是一維卷積步驟(圖3的底部附近)。它輸入5511步頻譜圖,並輸出1375步,然後由多層進一步處理以獲得最終的 T y = 1375 T_y=1375 Ty=1375步輸出。該層的作用類似於你在課程4中看到的2D卷積,其作用是提取低級特征,然後生成較小尺寸的輸出。
通過計算,一維轉換層還有助於加快模型的速度,因為現在GRU只需要處理1375個時間步,而不是5511個時間步。這兩個GRU層從左到右讀取輸入序列,然後最終使用dense+sigmoid層對 y * t * y^{\langle t \rangle} y*t*進行預測。因為 y y y是二進制值(0或1),所以我們在最後一層使用Sigmoid輸出來估計輸出為1的機率,對應用戶剛剛說過"activate"。
請注意,我們使用的是單向RNN,而不是雙向RNN。這對於關鍵字檢測確實非常重要,因為我們希望能夠在說出觸發字後立即檢測到觸發字。如果我們使用雙向RNN,則必須等待記錄整個10秒的音頻,然後才能知道在音頻剪輯的第一秒中是否說了"activate"。
可以通過四個步驟來實現模型:
步驟1:CONV層。使用Conv1D()和196個濾波器來實現,
濾波器大小為15(kernel_size = 15),步幅為4。[See documentation.]
步驟2:第一個GRU層。要生成GRU層,請使用:
X = GRU(units = 128, return_sequences = True)(X)
設置return_sequences = True可以確保所有GRU的隱藏狀態都被feed到下一層。請記住,在Dropout和BatchNorm層之後進行此操作。
步驟3:第二個GRU層。這類似於先前的GRU層(請記住使用return_sequences = True),但是有一個額外的dropout層。
步驟4:按以下步驟創建一個時間分布的密集層:
X = TimeDistributed(Dense(1, activation = "sigmoid"))(X)
這將創建一個緊隨其後的Sigmoid密集層,因此用於密集層的參數對於每個時間步都是相同的。[See documentation.]
練習:實現model(),其架構如圖3所示。
# GRADED FUNCTION: model
def model(input_shape):
""" 用 Keras 創建模型的圖 Function creating the model's graph in Keras. 參數: input_shape -- 模型輸入數據的維度(使用Keras約定) 返回: model -- Keras 模型實例 """
X_input = Input(shape = input_shape)
# 第一步:卷積層 (≈4 lines)
X = Conv1D(196, 15, strides=4)(X_input) # CONV1D
X = BatchNormalization()(X) # Batch normalization 批量標准化
X = Activation('relu')(X) # ReLu activation ReLu 激活
X = Dropout(0.8)(X) # dropout (use 0.8)
# 第二步:第一個 GRU 層 (≈4 lines)
X = GRU(units = 128, return_sequences=True)(X) # GRU (使用128個單元並返回序列)
X = Dropout(0.8)(X) # dropout (use 0.8)
X = BatchNormalization()(X) # Batch normalization 批量標准化
# 第三步: 第二個 GRU 層 (≈4 lines)
X = GRU(units = 128, return_sequences=True)(X) # GRU (使用128個單元並返回序列)
X = Dropout(0.8)(X) # dropout (use 0.8)
X = BatchNormalization()(X) # Batch normalization 批量標准化
X = Dropout(0.8)(X) # dropout (use 0.8)
# 第四步: 時間分布全連接層 (≈1 line)
X = TimeDistributed(Dense(1, activation = "sigmoid"))(X) # time distributed (sigmoid)
model = Model(inputs = X_input, outputs = X)
return model
model = model(input_shape = (Tx, n_freq))
讓我們輸出模型總結以查看維度。
model.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 5511, 101) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 1375, 196) 297136
_________________________________________________________________
batch_normalization_1 (Batch (None, 1375, 196) 784
_________________________________________________________________
activation_1 (Activation) (None, 1375, 196) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 1375, 196) 0
_________________________________________________________________
gru_1 (GRU) (None, 1375, 128) 124800
_________________________________________________________________
dropout_2 (Dropout) (None, 1375, 128) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 1375, 128) 512
_________________________________________________________________
gru_2 (GRU) (None, 1375, 128) 98688
_________________________________________________________________
dropout_3 (Dropout) (None, 1375, 128) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 1375, 128) 512
_________________________________________________________________
dropout_4 (Dropout) (None, 1375, 128) 0
_________________________________________________________________
time_distributed_1 (TimeDist (None, 1375, 1) 129
=================================================================
Total params: 522,561
Trainable params: 521,657
Non-trainable params: 904
_________________________________________________________________
網絡的輸出為(None,1375,1),輸入為(None,5511,101)。Conv1D將步數從頻譜圖上的5511減少到1375。
關鍵詞檢測需要很長時間來訓練。為了節省時間,我們已經使用你上面構建的架構在GPU上訓練了大約3個小時的模型,並提供了大約4000個示例的大型訓練集。讓我們加載模型吧。
model = load_model('./models/tr_model.h5')
你可以使用Adam優化器和二進制交叉熵損失進一步訓練模型,如下所示。這將很快運行,因為我們只訓練一個epoch,並提供26個例子的小訓練集。
opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=["accuracy"])
model.fit(X, Y, batch_size = 5, epochs=1)
Epoch 1/1
26/26 [==============================] - 10s 381ms/step - loss: 0.0893 - accuracy: 0.9717
最後,讓我們看看你的模型在開發集上的表現。
loss, acc = model.evaluate(X_dev, Y_dev)
print("Dev set accuracy = ", acc)
25/25 [==============================] - 1s 37ms/step
Dev set accuracy = 0.9507200121879578
看起來不錯!但是,精度並不是這項任務的重要指標,因為標簽嚴重偏斜到0,因此僅輸出0的神經網絡的精度將略高於90%。我們可以定義更有用的指標,例如F1得分或“精確度/召回率”。但是,我們不要在這裡使用它,而只是憑經驗看看模型是如何工作的。
現在,你已經建立了用於觸發詞檢測的工作模型,讓我們使用它來進行預測吧。此代碼段通過網絡運行音頻(保存在wav文件中)。
可以使用你的模型對新的音頻片段進行預測。
你首先需要計算輸入音頻剪輯的預測。
練習:實現predict_activates()。你需要執行以下操作:
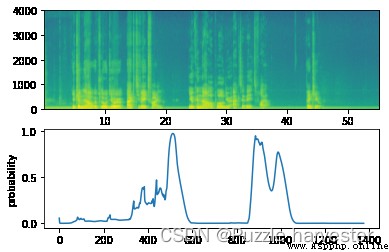
np.swap和np.expand_dims將輸入調整為(1,Tx,n_freqs)大小def detect_triggerword(filename):
plt.subplot(2, 1, 1)
x = graph_spectrogram(filename)
# 頻譜圖輸出(freqs,Tx),我們想要(Tx,freqs)輸入到模型中
x = x.swapaxes(0,1)
x = np.expand_dims(x, axis=0)
predictions = model.predict(x)
plt.subplot(2, 1, 2)
plt.plot(predictions[0,:,0])
plt.ylabel('probability')
plt.show()
return predictions
一旦估計了在每個輸出步驟中檢測到"activate"一詞的可能性,就可以在該可能性高於某個阈值時觸發出"chiming(蜂鳴)"聲。此外,在說出"activate"之後,對於許多連續值, y * t * y^{\langle t \rangle} y*t*可能接近1,但我們只希望發出一次提示音。因此,每75個輸出步驟最多將插入一次鈴聲。這將有助於防止我們為"activate"的單個實例插入兩個提示音。(該作用類似於計算機視覺中的非極大值抑制)
練習:實現chime_on_activate()。你需要執行以下操作:
使用以下代碼將1375步離散化轉換為10000步離散化,並使用pydub插入“chime”:
audio_clip = audio_clip.overlay(chime, position = ((i / Ty) * audio.duration_seconds)*1000)
chime_file = "audio_examples/chime.wav"
def chime_on_activate(filename, predictions, threshold):
audio_clip = AudioSegment.from_wav(filename)
chime = AudioSegment.from_wav(chime_file)
Ty = predictions.shape[1]
# 第一步:將連續輸出步初始化為0
consecutive_timesteps = 0
# 第二步: 循環y中的輸出步
for i in range(Ty):
# 第三步: 增加連續輸出步
consecutive_timesteps += 1
# 第四步: 如果預測高於阈值並且已經過了超過75個連續輸出步
if predictions[0,i,0] > threshold and consecutive_timesteps > 75:
# 第五步:使用pydub疊加音頻和背景
audio_clip = audio_clip.overlay(chime, position = ((i / Ty) * audio_clip.duration_seconds)*1000)
# 第六步: 將連續輸出步重置為0
consecutive_timesteps = 0
audio_clip.export("chime_output.wav", format='wav')
讓我們探討一下我們的模型在開發集中的兩個未知的音頻剪輯上表現如何。首先讓我們聽聽兩個開發集剪輯。
IPython.display.Audio("./raw_data/dev/1.wav")
CSDN不支持播放音頻
IPython.display.Audio("./raw_data/dev/2.wav")
CSDN不支持播放音頻
現在,讓我們在這些音頻剪輯上運行模型,看看在"activate"之後它是否添加了提示音!
filename = "./raw_data/dev/1.wav"
prediction = detect_triggerword(filename)
chime_on_activate(filename, prediction, 0.5)
IPython.display.Audio("./chime_output.wav")
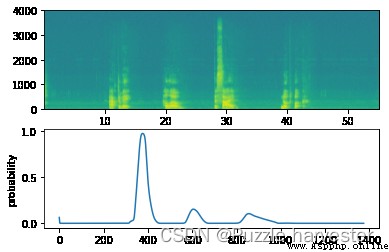
CSDN不支持播放音頻
filename = "./raw_data/dev/2.wav"
prediction = detect_triggerword(filename)
chime_on_activate(filename, prediction, 0.5)
IPython.display.Audio("./chime_output.wav")
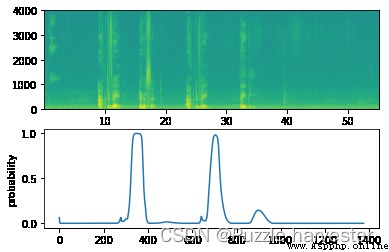
CSDN不支持播放音頻
這是你應該記住的:
在此筆記本的此可選練習中,你可以在自己的音頻剪輯上嘗試使用你的模型!
錄制一個10秒鐘的音頻片段,說"activate"和其他隨機單詞,然後將其作為myaudio.wav上傳到Coursera hub。確保將音頻作為WAV文件上傳。如果你的音頻以其他格式(例如mp3)錄制,則可以在線找到免費軟件以將其轉換為wav。如果你的錄音時間不是10秒,則下面的代碼將根據需要修剪或填充該聲音,以使其達到10秒。
# 將音頻預處理為正確的格式
def preprocess_audio(filename):
# 將音頻片段修剪或填充到 10000ms
padding = AudioSegment.silent(duration=10000)
segment = AudioSegment.from_wav(filename)[:10000]
segment = padding.overlay(segment)
# 將幀速率設置為 44100
segment = segment.set_frame_rate(44100)
# 導出為wav
segment.export(filename, format='wav')
將音頻文件上傳到Coursera後,將文件路徑放在下面的變量中。
your_filename = "audio_examples/my_audio.wav"
preprocess_audio(your_filename)
IPython.display.Audio(your_filename) # 聽你上傳的音頻
CSDN不支持播放音頻
最後,使用該模型預測在10秒的音頻剪輯中何時說了"activate"並觸發提示音。如果沒有適當添加哔聲,請嘗試調整chime_threshold。
chime_threshold = 0.5
prediction = detect_triggerword(your_filename)
chime_on_activate(your_filename, prediction, chime_threshold)
IPython.display.Audio("./chime_output.wav")
CSDN不支持播放音頻