He Xiaoman&Original image by Liu Feng.jpg

People word cloud effect.jpg
電影《芳華》Re-screened in the Spring Festival,Plus previous hits,最終取得了 14 億票房的好成績.Yan Geling's original work has therefore been carefully read by more people.Dismembering novels with some techniques of text analysis has always been a big gimmick in the field of natural language processing,This time, of course, can't let it go,The achievements in this article are:
1、Extract the two main characters Liu Feng and He Xiaoman(萍)keywords and draw a good-looking character word cloud;
2、Explore the thematic distribution of the novel in chapters and draw a picture to display it.
主要功能包:
jieba
lda
wordcloud
seaborn
安裝命令: pip install ***
Required external files:
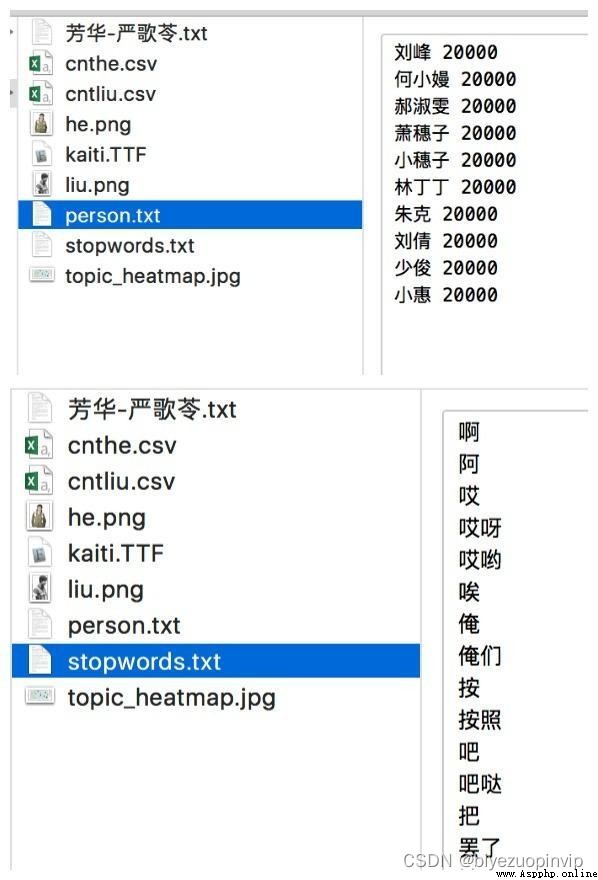
Example of person name and stopwords file.jpg
文本預處理
分詞,And filter meaningless words
A must-have for text mining,After all, the smallest unit of understanding Chinese is vocabulary.Simple is not used here jieba.cut 進行分詞,Because we need to know the part of speech of the word,Convenient to filter unimportant words based on part of speech later.
采用 jieba.posseg.cut Word segmentation can output parts of speech.We can't pat on the forehead to decide whether we want verbs or nouns, etc,There are many parts of speech,I classify all the participle results according to the part of speech,Look at which words each part of speech corresponds to,Finally decided to keep the part of speech as[“a”, “v”, “x”, “n”, “an”, “vn”, “nz”, “nt”, “nr”]的詞,例如圖中,m Represents a quantifier,This is a word that doesn't help semantics,應該捨棄.
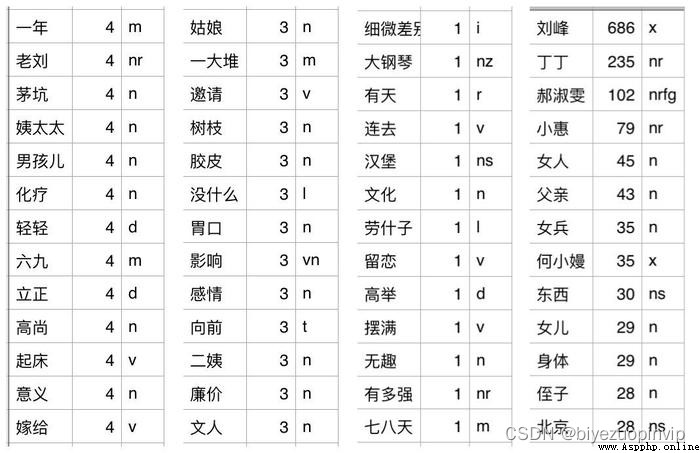
Examples of parts of speech.jpg
import jieba.posseg
jieba.load_userdict("data/person.txt")
STOP_WORDS = set([w.strip() for w in open("data/stopwords.txt").readlines()])
def cut_words_with_pos(text):
seg = jieba.posseg.cut(text)
res = []
for i in seg:
if i.flag in ["a", "v", "x", "n", "an", "vn", "nz", "nt", "nr"] and is_fine_word(i.word):
res.append(i.word)
return list(res)
# Filter word length,過濾停用詞,只保留中文
def is_fine_word(word, min_length=2):
rule = re.compile(r"^[\u4e00-\u9fa5]+$")
if len(word) >= min_length and word not in STOP_WORDS and re.search(rule, word):
return True
else:
return False
劃分章節
我們按照“第*章”Words like this separate the different chapters of the novel,as a standalone document,for subsequent thematic analysis.定義了一個名為 MyChapters 的生成器,Stores sorted vocabulary for each chapter,It is to avoid some program running problems caused by too many chapters.其實《芳華》僅有 15 章,It is also possible to use a simple list.
class MyChapters(object):
def __init__(self, chapter_list):
self.chapter_list = chapter_list
def __iter__(self):
for chapter in self.chapter_list:
yield cut_words_with_pos(chapter)
def split_by_chapter(filepath):
text = open(filepath).read()
chapter_list = re.split(r'第.{1,3}章\n', text)[1:]
return chapter_list
To extract character keywords,首先要解決的問題是,without resorting to external character descriptions(For example, the character introductions on Baidu Encyclopedia and Douban movies)的情況下,How to determine what is relevant to this character.The simpler strategy employed here is,for each line in the novel file,If the character's name exists,Then add the line to the relevant corpus of this person.Then count the word frequency based on this,The result is roughly ok,For a more accurate display of the character word cloud,I output the word frequency to a file,Some words were manually removed,And simply adjusted the word frequency of some words,The figure below is the adjusted word and word frequency,Zuo why Xiaoman,On the right is Liu Feng.
import pandas as pd
def person_word(name):
lines = open("data/芳華-嚴歌苓.txt", "r").readlines()
word_list = []
for line in lines:
if name in line:
words = cut_words_with_pos(line)
word_list += words
# Count word frequencies and sort them in descending order of word frequency,取top500
cnt = pd.Series(word_list).value_counts().head(500)
# The results can be output to a file,Make some manual adjustments
# cnt.to_csv("data/cntliu.csv")
# 返回字典格式
return cnt.to_dict()
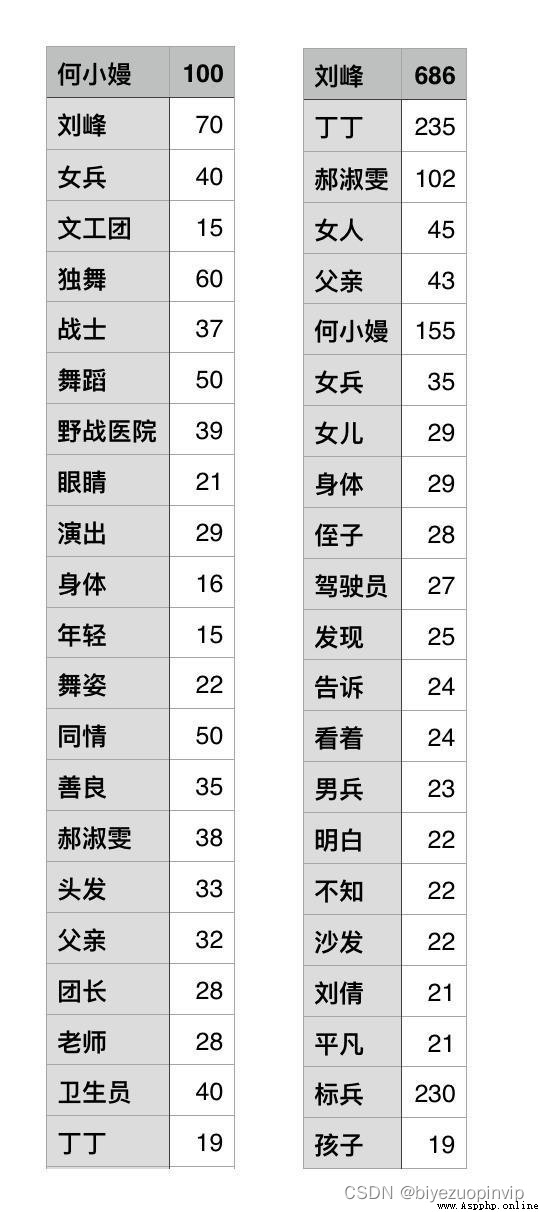
Example of people keyword extraction results.jpg
python 有 wordcloud Package can be used for word cloud drawing,在使用過程中需要注意:
The external image used to define the shape must be png 格式,The default solid white portion is the non-image area;
Chinese word cloud must load a font file;
The color of the words can be defined by yourself,You can also use the base color of the image itself.Picture of He Xiaoman in this case The background is very bright and clear,You can use your own base color(ImageColorGenerator);And Liu Feng's picture is monochrome,And light in color,I used custom colors(my_color_func);
The data format needed to draw a word cloud is dict,key 為詞,value 為詞頻,詞頻越大,The larger the font size in the picture.
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from scipy.misc import imread
from random import choice
# 定義顏色,方法很多,The method used here is to draw randomly among the four colors
def my_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
return choice(["rgb(94,38,18)", "rgb(41,36,33)", "rgb(128,128,105)", "rgb(112,128,105)"])
def draw_cloud(mask_path, word_freq, save_path):
mask = imread(mask_path) #讀取圖片
wc = WordCloud(font_path='data/kaiti.TTF', # 設置字體
background_color="white", # 背景顏色
max_words=500, # 詞雲顯示的最大詞數
mask=mask, # 設置背景圖片
max_font_size=80, # 字體最大值
random_state=42,
)
# generate_from_frequencies方法,Generate word cloud input from word frequencies
wc.generate_from_frequencies(word_freq)
plt.figure()
# 劉峰, In custom colors
plt.imshow(wc.recolor(color_func=my_color_func), interpolation='bilinear')
# He Xiaoman, Use the background color of the picture
# image_colors = ImageColorGenerator(mask)
# plt.imshow(wc.recolor(color_func=image_colors), interpolation='bilinear')
plt.axis("off")
wc.to_file(save_path)
plt.show()
# Get keywords and word frequencies
input_freq = person_word("劉峰")
# Word frequency files that have been manually adjusted,供參考
# freq = pd.read_csv("data/cntliu.csv", header=None, index_col=0)
# input_freq = freq[1].to_dict()
draw_cloud("data/liu.png", input_freq, "output/liufeng.png")
Cut out the characters,The background is set to pure white,存儲為 png 格式.
To make the shape more distinct,I have whitened Xiaoman's braids and the waist,You can compare it with the original image at the beginning of the article.

He Xiaoman&Liu Feng used as a picture to generate the word cloud.jpg
People word cloud effect.jpg
 Wake up the wrist Python full stack engineer learning notes (Basic Research)
Wake up the wrist Python full stack engineer learning notes (Basic Research)
01、 Introduction to basic gram
 Python object oriented -- basic concepts of classes and objects, relationships between classes and objects, and class design
Python object oriented -- basic concepts of classes and objects, relationships between classes and objects, and class design
One 、 Concepts of classes and