effect :
1. be applied to web Testing tools
2. Its test is directly in the browser , Just like the real user operation
3. Support various driver browsers
4. Support browser operation without interface
How to install Lai ?
Operate Google browser driver download address :https://chromedriver.storage.googleapis.com/index.html
pip install selenium -i https://www.pypi.douban.com/simple
# selenium
# import urllib.request
# url = 'https://www.jd.com/'
# response = urllib.request.urlopen(url)
# content = response.read().decode('utf-8')
# print(content)
# (1) Import selenium
from selenium import webdriver
# (2) Create browser action object
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (3) Visit website
# url = 'https://www.baidu.com'
# browser.get(url)
url = 'https://www.jd.com/'
browser.get(url)
# page_source Get web source
content = browser.page_source
print(content)
# selenium Element localization
from selenium import webdriver
from selenium.webdriver.common.by import By
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# Element localization
# according to id Find the object
# button = browser.find_element(by=By.ID, value='su')
# print(button)
# Get the object name according to the tag attribute value
# button = browser.find_element_by_name('wd')
# print(button)
# according to xpath Statement get object
button = browser.find_element_by_xpath('//input[@id="su"]')
print(button)
# Get the object according to the tag name
button = browser.find_element_by_tag_name('input')
print(button)
# Use bs4 The syntax to achieve
button = browser.find_element_by_css_selector('#su')
button = browser.find_element_by_link_text(" live broadcast ")
print(button)
from selenium import webdriver
from selenium.webdriver.common.by import By
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
input = browser.find_element_by_id('su')
# Get tag attributes
print(input.get_attribute('class'))
# Get the tag name
print(input.tag_name)
# Get element text
a = browser.find_element_by_link_text(' Journalism ')
print(a.text)
# selenium_handless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path It's personal. chrome Browser file path
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.baidu.com'
browser.get(url)
browser.save_screenshot('./file/baidu.png')
Packaged handless( Extremely easy to use )
# Packaged handless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path It's personal. chrome Browser file path
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
return browser
browser = share_browser()
url = 'https://www.baidu.com'
browser.get(url)
Official documents :https://doc.codingdict.com/request/docs.python-requests.org/zh_CN/latest/index.html
install :pip install requests
requests Basic use
1. One type and six attributes
# requests Basic use
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)
# One type and six attributes
# 1.response type
print(type(response))
# 2.1 Set the encoding format of the response
response.encoding = 'utf-8'
# 2.2 Return the web page source code in the form of string
print(response.text)
# 2.3 return url Address
print(response.url)
# 2.4 Returns binary data
print(response.content)
# 2.5 Returns the status code of the response
print(response.status_code)
# 2.6 Return response header
print(response.headers)
2.get request
import requests
url = 'https://www.baidu.com/s?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
data = {
'wd':' Beijing '
}
# url Request resource path
# params Parameters
# kwargs Dictionaries
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)
# (1) Parameters use params Pass on
# (2) Parameters are not required urlencode code
# (3) No customization of the request object is required
# (4) Request... In the resource path ? You can add or not add
3.post request
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
data = {
'kw':'eye'
}
# url Request address
# data Request parameters
# kwargs Dictionaries
response = requests.post(url=url,data=data,headers=headers)
content = response.text
import json
obj = json.loads(content)
print(obj)
# summary
# (1)post The request does not need to be decoded
# (2)post The request parameter is data
# (3) No customization of the request object is required
4.request agent
The case of failure , The crawled page is blocked by Baidu security verification , No solution has been found at present ..
import requests
url = 'https://www.baidu.com/s?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
data = {
"wd":"ip"
}
proxy = {
'http':'112.6.117.135:8085'
}
response = requests.get(url=url,params=data,headers=headers,proxies=proxy)
content = response.text
with open('./file/daili.html','w',encoding='utf-8')as fp:
fp.write(content)
# Log in to the main page
# Parameters required for login
# __VIEWSTATE: MhTU6ngpY+d6+v03OI2VLwWkT9WEEg0WJXCgtQVoV3ub3U8WFLzuZ+6GAihlB8lY7d0Ndwv3vVQ1a191DlG8aU65pA604tMI4bfSRa51oYBFQynfi//xkA+oIOw=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: [email protected]
# pwd: action
# code:
# denglu: Sign in
# The observed __VIEWSTATE __VIEWSTATEGENERATOR code It's a variable.
# difficulty :(1) __VIEWSTATE __VIEWSTATEGENERATOR
# (2) Verification Code
import requests
# This is the of the login page url Address
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
response = requests.get(url=url,headers=headers)
content = response.text
# Parsing page source code
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# obtain __VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
print(viewstate)
# obtain __VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(viewstategenerator)
# Gets the captcha image
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
print(code_url)
# Get the picture of the verification code and download it locally , Observe the content of the picture Enter the verification code in the console
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='./file/code.jpg')
# requests There is a way ,session() Method adopt session The return value of makes the request an object
session = requests.session()
# Verification Code url The content of
response_code = session.get(code_url)
# Note that binary numbers should be used at this time Download pictures
content_code = response_code.content
# wb Is to write binary data to a file
with open('./file/code.jpg','wb')as fp:
fp.write(content_code)
code_name = input(' Please enter the verification code ')
# Click login
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
"__VIEWSTATE": viewstate,
"__VIEWSTATEGENERATOR": viewstategenerator,
"from": "http://so.gushiwen.cn/user/collect.aspx",
"email": "[email protected]",
"pwd": "090711zgf",
"code": code_name,
"denglu": " Sign in "
}
response_post = session.post(url=url,headers=headers,data=data_post)
content_post = response_post.text
with open('./file/gushiwen.html','w',encoding='utf-8') as fp:
fp.write(content_post)
# difficulty (1) Hidden domain problems (2) Verification Code
https://www.chaojiying.com/
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
""" im: Picture byte codetype: Topic type Reference resources http://www.chaojiying.com/price.html """
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {
'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
""" im: Picture byte codetype: Topic type Reference resources http://www.chaojiying.com/price.html """
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
""" im_id: Picture of the wrong title ID """
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
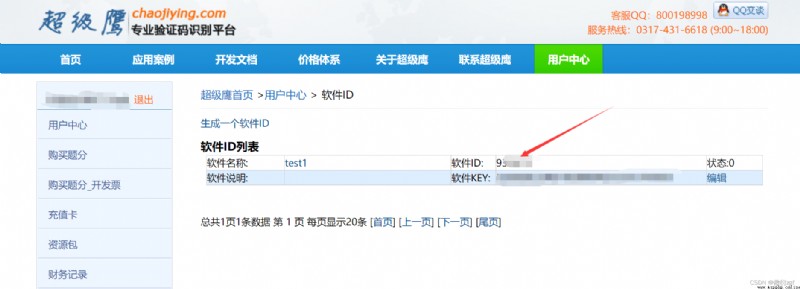
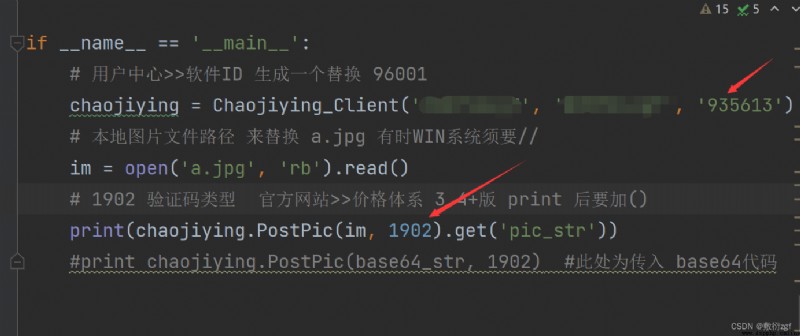
# User center >> Software ID Generate a replacement 96001
chaojiying = Chaojiying_Client('', '', '')
# Local image file path To replace a.jpg Sometimes WIN The system needs //
im = open('a.jpg', 'rb').read()
# 1902 Verification code type Official website >> The price system 3.4+ edition print After ()
print(chaojiying.PostPic(im, 1902).get('pic_str'))
#print chaojiying.PostPic(base64_str, 1902) # Here is the incoming base64 Code
 AI全球氣象預報模型;開源數據標注平台;『統計學習導論及R語言應用』Python版源碼;『數學』自學路線圖與資源;前沿論文 | ShowMeAI資訊日報
AI全球氣象預報模型;開源數據標注平台;『統計學習導論及R語言應用』Python版源碼;『數學』自學路線圖與資源;前沿論文 | ShowMeAI資訊日報
ShowMeAI日報系列全新升級!覆蓋AI人工智能 工具&a
 < leetcode ladder > day035 merging two ordered arrays (slicing method) | primary algorithm | Python
< leetcode ladder > day035 merging two ordered arrays (slicing method) | primary algorithm | Python
Make a little progress every d