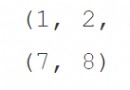hello, I haven't seen you for a long time , I don't know if I want to UP ah . Recently, due to personal reasons, I have no time to share new case tutorials with you , So sorry, everyone , Now the problem has been solved , It will be updated every day , I hope you like it .

So what is the case to share with you today , That is a case of a crawler that can download text by inputting the name of a novel in just 20 lines of code , Relatively speaking, it is very simple , Can let everyone get started well , And then it follows up Let's work together to realize such a function
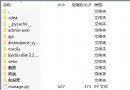
Xiaobian used to love reading novels , I haven't read a novel in the past few years , I don't know which websites can be crawled , So I just found one .、 We first come to the novel of the website top Check the web page source code
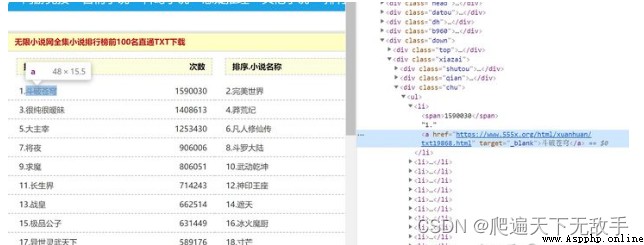
You can still see clearly top All the novels in the list are <li> In the tag, this brings great convenience to our crawlers , Just get each li The content in the label can be completed .
Plus, let's find out where to download the file , We continue to click to break through the sky to the following page , Why choose to break this novel , That's because this is up The first finished novel in my life , It is also the most impressive novel . I don't know if you feel the same , I remember it was hard to wait for updates at that time .

We continue to click in and see the download link of the file , In order to make the crawler code simpler, let's take a look at this link and the previous li What is the difference between the novel links in the tag 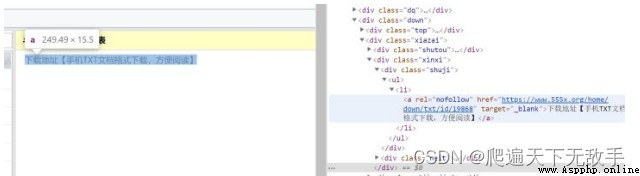
You can see that they have the same serial number , In this way, we only need to get the number of each novel to get the download links of all novels , Let's improve our code .
The library we need for this project is requests library ,BeautifulSoup library
After sorting out the above ideas, we first establish our crawler framework :

I drew a flow chart to let you better understand our structure
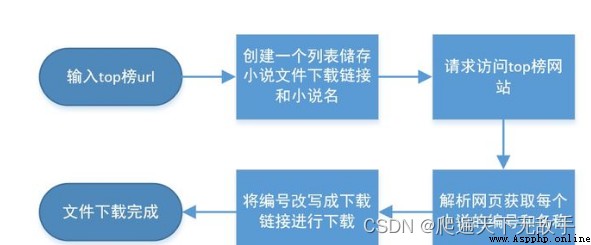
OK, let's see what the code for each part is :
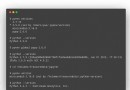
The web page request code is almost universal. Every time a crawler can copy and paste it intact ( This code cannot solve the problem of anti - crawling )
def getHTMLtext(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
try:
r = requests.get(url=url, headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print(' The visit to fail ')The following is to get the information of each novel on the page and construct a download link
def parseHTMLtext(html,down_list):
soup=BeautifulSoup(html,'html.parser')
li_list=soup.find('div',class_='chu').find_all('li')
for li in li_list:
li_url=li.find('a').attrs['href']
li_url='https://www.555x.org/home/down/txt/id/'+li_url[-10:-5:1]
name=li.a.string
down_list.append([li_url,name])
passThe following is the file saving function
def savetxt(down_list):
root='D:\\ A novel \\'
for down in down_list:
path=root+down[1]+'.txt'
txt=requests.get(down[0]).content
print(down[0])
with open(path,'wb') as f:
f.write(txt)
f.close()
passNext is the main function
def main():
url='https://www.555x.org/top.html'
html=getHTMLtext(url)
down_list = []
parseHTMLtext(html,down_list)
savetxt(down_list)
print(' Download successful ')
passOK, this is our code framework. Let's see how the code crawler works :

All the children who have read these novels should have soy sauce

We can see that the effect is good !!
Well, this is the whole content of this issue. I hope you can try it by typing the code yourself , I am also python A little white in the reptile , The code may not be perfect, but I still hope to get your support , In the future, I will also launch more articles to study together !!
In the next issue, we will share how to crawl web images , You can pay attention to it !!!
Finally, I'll give you a complete code. If you want to read a novel immediately, you can copy and paste it directly :
import requests
from bs4 import BeautifulSoup
# Web request
def getHTMLtext(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
try:
r = requests.get(url=url, headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print(' The visit to fail ')
# Web content analysis
def parseHTMLtext(html,down_list):
soup=BeautifulSoup(html,'html.parser')
li_list=soup.find('div',class_='chu').find_all('li')
for li in li_list:
li_url=li.find('a').attrs['href']
li_url='https://www.555x.org/home/down/txt/id/'+li_url[-10:-5:1]
name=li.a.string
down_list.append([li_url,name])
pass
# file save
def savetxt(down_list):
root='D:\\ A novel \\'
for down in down_list:
path=root+down[1]+'.txt'
txt=requests.get(down[0]).content
print(down[0])
with open(path,'wb') as f:
f.write(txt)
f.close()
pass
# The main function
def main():
url='https://www.555x.org/top.html'
html=getHTMLtext(url)
down_list = []
parseHTMLtext(html,down_list)
savetxt(down_list)
print(' Download successful ')
pass
main()The source code is posted , It can also be further optimized , But considering that everyone's level is different , So let's stop here today , By the way, you can pay attention to the official account below . If you have any questions you don't understand, please leave a message . I'll see you next