Climb close 3 Monthly precipitation data of Mianyang City , And stored in xlsx In the document . utilize xpath and re Crawler technology to obtain data , utilize pandas Store data in xlsx In the document .
️ Tips : Reptiles cannot be used as illegal activities , Set the sleep time when crawling , Do not over crawl , Causing server downtime , Be legally liable !!!
Example :pandas Is based on NumPy A tool of , The tool is created to solve data analysis tasks .
Open the data of China weather , Only found 40 The day option can display the precipitation more comprehensively , But only one month's , I need to find data for other months
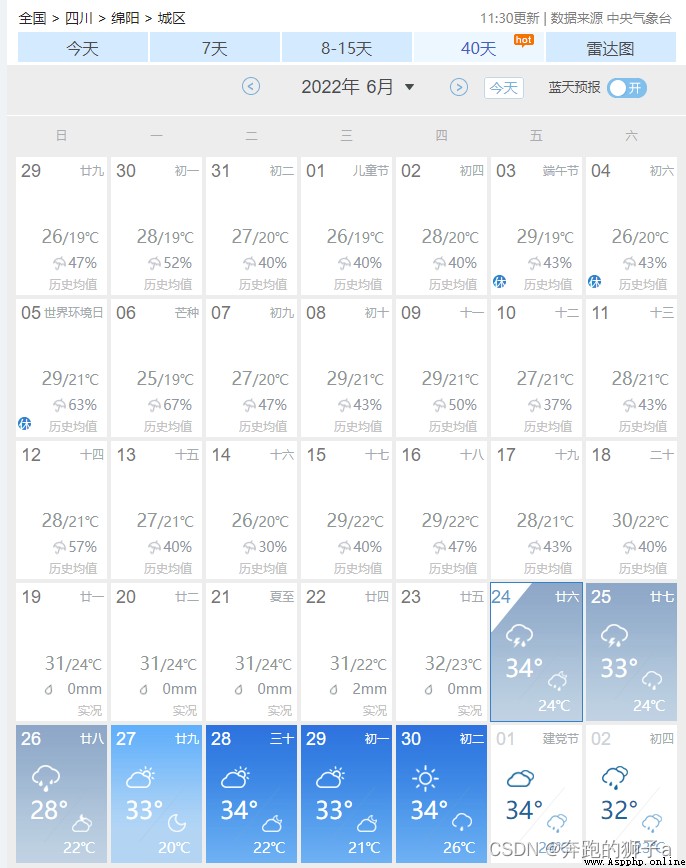
I found that the month can be selected here , I think that when I choose the month , Will trigger some function events and return data . Open developer tools , Ready to view network data .
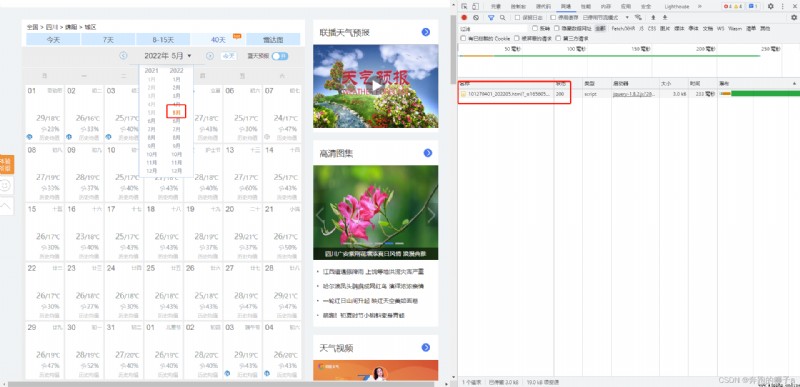
Click other months , There are several html Network data , Click on Preview Check and find the specific weather data , Include date 、 temperature 、 Precipitation 、 The Yellow calendar and so on .
import requests
import json
import pandas as pd
# result set
result_list = []
for i in range(2,6):
# To crawl url
url = "http://d1.weather.com.cn/calendar_new/2022/101270401_20220"+(str)(i)+".html"
# Anti creep headers
headers = {
"Referer": "http://www.weather.com.cn/",
"Connection": "keep-alive",
"Content-Encoding": "gzip",
"Content-Type": "text/html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
"Cookie": "f_city=%E5%8D%97%E5%AE%81%7C101300101%7C; Hm_lvt_080dabacb001ad3dc8b9b9049b36d43b=1654830903,1654838893,1654956338; Hm_lpvt_080dabacb001ad3dc8b9b9049b36d43b=1654957148",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9"
}
# Crawling
resp = requests.get(url=url, headers=headers)
resp.encoding = 'utf-8'
# Data string
data_str = resp.text[11:]
# turn json, Variable data set
data_list = json.loads(data_str)
# Circular data set , get data
for data in data_list:
data[' City '] = ' mianyang '
rain = data['hgl']
date = data['date']
result = {
}
result[' City '] = ' mianyang '
result[' Probability of precipitation '] = rain
result[' date '] = date
result_list.append(result)
print(result_list)
# pandas write in excel
data = pd.DataFrame(result_list)
writer = pd.ExcelWriter(' rainfall .xlsx') # write in Excel file
data.to_excel(writer, 'page_1', float_format='%.5f')
writer.save()
print(" end !")
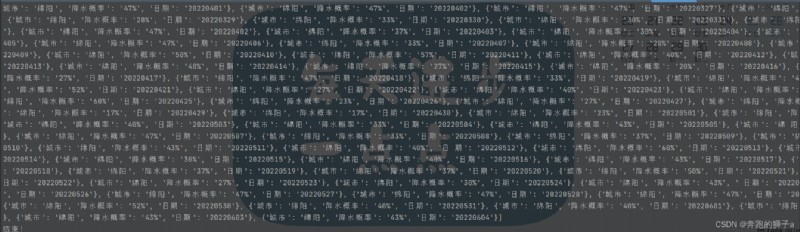
The program runs as follows
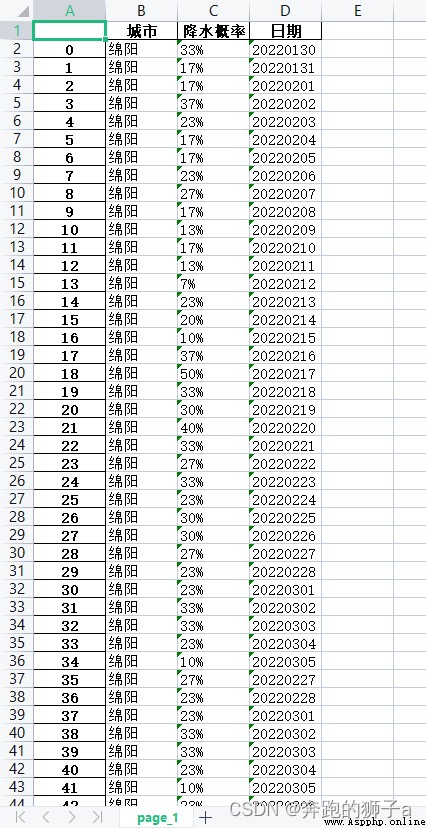
Stored xlsx The documents are as follows
The basic steps of a reptile :
1. Check whether there is anti climbing , Set the normal reverse crawl ,User-Agent and referer Are the most common anti climbing methods
2. utilize xpath and re Technology positioning , Get the desired data after positioning
3.pandas Write data to xlsx file
4. Pay attention to the settings time Sleep