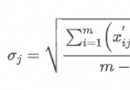Hello, everyone , It's my little panda again
When we collect data , Too fast or frequently visited , Or you can pop up the verification code as soon as you visit , And then the clam bead ~
Today, I will give you a simple method to deal with the verification code
Python and pycharm If there are still some friends who haven't installed it , You can scan the code at the bottom of the article to get the installation package .
There needs to be a ddddocr modular , This is something that someone else has written open source , Simple and easy to use , But the accuracy is a little poor , But it is still very easy to use .
If you want precision , You can call some written by others API .
Let's just win+r Enter... After the search box pops up cmd , Click OK to pop up the command prompt window , Input pip install ddddocr You can install .
If not, please refer to my top article for detailed explanation .
Not much code , It's simple .
After the module is installed, let's import it
import ddddocr
Then instantiate , Use one cor Receive this data .
ocr = ddddocr.DdddOcr()
I have prepared four verification codes here 



Blog watermark seems to be blocked , But I won't turn it off , Hey ~
Back to the point , Implement the verification code respectively .
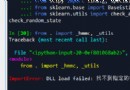
First of all, we use with open To read this file , The read mode uses rb , If it is a picture, read its binary data
with open('img_3.png', 'rb') as f:
Use f.read() Read the data out , Then customize a variable to receive .
img_bytes = f.read()
And then we passed classification Pass it in , Just print out the results .
result = ocr.classification(img_bytes)
print(result)
Pure digital 

Letter + Digital 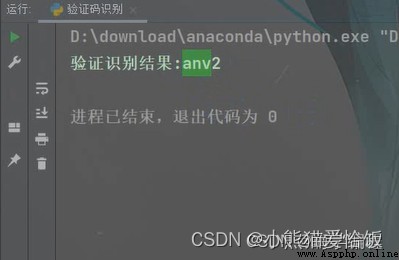

You can see that they are completely identified , Even if there are some fancy horizontal lines on it .
import ddddocr
ocr = ddddocr.DdddOcr()
with open('img_3.png', 'rb') as f:
img_bytes = f.read()
result = ocr.classification(img_bytes)
print(result)
(https://jq.qq.com/?_wv=1027&k=3uTc6UFb)
You can try it yourself , It can also be directly applied to the practice of data collection ~
It's not easy to create , Let's help you to order a collection ~