Share some with Python Handle yaml And nested data structures , First from modify yaml Format file , Various solutions have evolved , From the final solution, a more universal positioning method for nested data structures is derived .
Keep the comments modified yaml file
Locate nested data structures
Locate nested data structures 2
Keep the comments modified yaml fileyaml Than the json One of the differences between files is that they can be annotated , These notes are sometimes very important , Just like the comments in the code , If you edit it manually, there is no problem , So how to modify with code without leaving comments yaml What about the documents ?
Suppose we want to modify yaml The documents are as follows :
# Main maintainer name: zhangsan# Operation and maintenance personnel of each cluster cluster1: node1: tomcat: user11cluster2: node1: tomcat: user21 Don't keep comments To demonstrate handling yaml Methods of , The method of not reserving comments is also included in this article .
def ignore_comment(): data = yaml.load(text, Loader=yaml.Loader) data["name"] = "wangwu" print(yaml.dump(data))Output is as follows :
cluster1:
node1:
tomcat: user11
cluster2:
node1:
tomcat: user21
name: wangwu
Obviously , This is not the result we want , Then eliminate this method .
This method is only applicable to modifications that do not need to retain comments .
Regular expressionssince load, dump Method discards comments , Then it's OK to use regular expressions , There must be a place for regular expressions when dealing with text .
Suppose you will still name: zhangsan Change to name: wangwu.
def regex1(): pattern = "name:\s+\w+" pat = re.compile(pattern=pattern) # First, match to the corresponding string sub_text = pat.findall(text)[0] # Find the position in the text according to this string start_index = text.index(sub_text) # Calculate the end position according to the start position end_index = start_index + len(sub_text) print(start_index, end_index, text[start_index:end_index]) # The contents will be replaced according to the index replace_text = "name: wangwu" new_text = text[:start_index] + replace_text + text[end_index:] print("="*10) print(new_text)Output is as follows :
8 22 name: zhangsan
==========
# Main maintainer
name: wangwu
# Operation and maintenance personnel of each cluster
cluster1:
node1:
tomcat: user11
cluster2:
node1:
tomcat: user21
It looks good , It seems to meet the demand , But one problem here is , Suppose the modification is cluster2.node1.tomcat The value of ?
Because there are two in the text tomcat Value , So you can't hit it with one click just by using regular expressions , Need more judgment conditions , For example, first find cluster2 Starting position , Then filter out index values smaller than this starting position , But if there is cluster3,cluster4 Well ? Generally speaking, it is still It needs to be done manually , Then write regular expressions based on the observations , But it's not smart , It's not automatic .
This method is suitable for comparing text matching containers .
Grammar treeIn fact, the data structure of the whole text is roughly as follows :
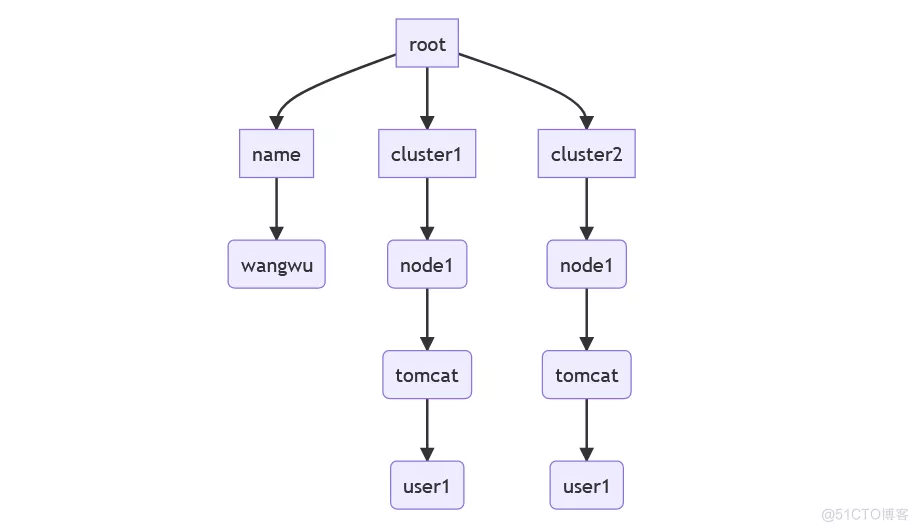
Whether it's programming language or data text , Such as json, yaml, toml You can get such a syntax tree , By searching this syntax tree , We can find the corresponding key value pair .
def tree1():
tree = yaml.compose(text)
print(tree)
Output is as follows :
MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='name'), ScalarNode(tag='tag:yaml.org,2002:str', value='zhangsan')), (ScalarNode(tag='tag:yaml.org,2002:str', value='cluster1'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='node1'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='tomcat'), ScalarNode(tag='tag:yaml.org,2002:str', value='user11'))]))])), (ScalarNode(tag='tag:yaml.org,2002:str', value='cluster2'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='node1'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='tomcat'), ScalarNode(tag='tag:yaml.org,2002:str', value='user21'))]))]))])
adopt yaml.compose Method we can get a node tree , And each node will include the text information of the node , Like the beginning , Terminated text index .
Through observation we can find name: zhangsan Two nodes of , key name It's a ScalarNode node , value zhangsan Also a ScalarNode, So we can print it to see if it is consistent with the result of the regular expression .
def tree2(): tree = yaml.compose(text) key_name_node = tree.value[0][0] value_name_node = tree.value[0][1] print(key_name_node.start_mark.pointer, value_name_node.end_mark.pointer, key_name_node.value, value_name_node.value)Output is as follows :
8 22 name zhangsan
The result is consistent with the regular expression , So this method is feasible and accurate .
Get the index position of the modified text , You can replace , I'm not going to do that here .
This method is suitable for preserving the modification of annotations , And locating nested structures is simpler than regular expressions , And no human intervention is required .
So how to locate nested structures ?
Locate nested data structuresFrom the previous section, we learned that data structures can be abstracted into a syntax tree , Then some tree search algorithms can be used to locate the target text .
Here is an example of a search algorithm that does not contain list nodes .
def find_slice(tree: yaml.MappingNode, keys: List[str]) -> Tuple[Tuple[int, int], Tuple[int, int]]: """ find yaml The index of the corresponding key value pair in the file , Return to one ((key Starting index , key End index +1), (value Starting index , value End index +1)) tuples For the time being, it only supports the search of key value pairs . such as : >>> find_slice("name: zhangsan", ["name"]) ((0, 4), (6, 14)) """ if isinstance(tree, str): tree = yaml.compose(tree, Loader=yaml.Loader) assert isinstance(tree, yaml.MappingNode), " Unsupported yaml Format " target_key = keys[0] for node in tree.value: if target_key == node[0].value: key_node, value_node = node if len(keys) == 1: key_pointers = (key_node.start_mark.pointer, key_node.end_mark.pointer) value_pointers = (value_node.start_mark.pointer, value_node.end_mark.pointer) return (key_pointers, value_pointers) return find_slice(node[1], keys[1:]) return ValueError(" No corresponding value found ")The core of the algorithm is recursion .
The implementation here does not handle list nodes (SequenceNode).
Suppose we're looking for cluster1.node1.tomcat And change its value to changed, The code is as follows :
def tree3(): slices = find_slice(text, ["cluster1", "node1", "tomcat"]) value_start_index, value_end_index = slices[1] replace_text = "changed" new_text = text[:value_start_index] + replace_text + text[value_end_index:] print(new_text)Output is as follows
# Main maintainer
name: zhangsan# Operation and maintenance personnel of each cluster
cluster1:
node1:
tomcat: changedcluster2:
node1:
tomcat: user21
The above algorithm can only locate key-value Type of data structure , Now optimize here , Let it Support sequence .
def find_slice2(tree: yaml.MappingNode, keys: List[str]) -> Tuple[Tuple[int, int], Tuple[int, int]]: """ find yaml The index of the corresponding key value pair in the file , Return to one ((key Starting index , key End index +1), (value Starting index , value End index +1)) tuples For the time being, it only supports the search of key value pairs . such as : >>> find_slice2("name: zhangsan", ["name"]) ((0, 4), (6, 14)) """ if isinstance(tree, str): tree = yaml.compose(tree, Loader=yaml.Loader) target_key = keys[0] assert isinstance(tree, yaml.MappingNode) or isinstance(tree, yaml.SequenceNode), " Unsupported yaml Format " ret_key_node = None ret_value_node = None value_pointers= (-1, -1) if isinstance(tree, yaml.SequenceNode): assert isinstance(target_key, int), " Bad data format " # The index can be negative , such as [1,2,3][-1] if len(tree.value) < abs(target_key): raise IndexError(" The index value is greater than the list length ") node = tree.value[target_key] if len(keys) > 1: return find_slice2(tree.value[target_key], keys[1:]) if isinstance(node, yaml.MappingNode): ret_key_node, ret_value_node = node.value[0] else: ret_key_node = node if isinstance(tree, yaml.MappingNode): for node in tree.value: if target_key == node[0].value: key_node, value_node = node if len(keys) > 1: return find_slice2(node[1], keys[1:]) ret_key_node = key_node ret_value_node = value_node if ret_key_node: key_pointers = (ret_key_node.start_mark.pointer, ret_key_node.end_mark.pointer) if ret_value_node: value_pointers = (ret_value_node.start_mark.pointer, ret_value_node.end_mark.pointer) if ret_key_node: return (key_pointers, value_pointers) return ValueError(" No corresponding value found ")hypothesis yaml The documents are as follows :
# User list users: - user1: wangwu - user2: zhangsan# Cluster middleware version cluster: - name: tomcat version: 9.0.63 - name: nginx version: 1.21.6def tree4(): slices = find_slice2(text2, ["cluster", 1, "version"]) value_start_index, value_end_index = slices[1] replace_text = "1.22.0" new_text = text2[:value_start_index] + replace_text + text2[value_end_index:] print(new_text)Output is as follows :
# User list
users:
- user1: wangwu
- user2: zhangsan# Cluster middleware version
cluster:
- name: tomcat
version: 9.0.63
- name: nginx
version: 1.22.0
Results in line with expectations .
Locate nested data structures 2The above describes how to locate nested data structure trees , This section describes how to locate deep tree structures ( Mainly refers to python Dictionaries ).
call chaining getIn obtaining api The data structure you want is deep , Using the index will report an error , then Need to catch exception , It's a hassle , And the code is verbose , such as :
data1 = {"message": "success", "data": {"limit": 0, "offset": 10, "total": 100, "data": ["value1", "value1"]}}data2 = {"message": "success", "data": None}data3 = {"message": "success", "data": {"limit": 0, "offset": 10, "total": 100, "data": None}}The above data structure is likely to come from the same api structure , But the data structure is different .
If you use the index directly , You need to catch exceptions , It looks annoying , Then you can use the dictionary get Method .
ret = data1.get("data", {}).get("data", [])if ret: pass # Do something if data2.get("data"): ret = data2["data"].get("data", [])ret = data3.get("data", {}).get("data", [])By giving an expected data null object , Give Way get You can write it down consistently .
Write a recursive getStart at the previous find_slice In the method , We found that recursion can handle this kind of nested data structure better , We can write a recursive handler , Used to deal with deep data structures .
Suppose the data structure is as follows :
data = {"message": "success", "data": {"data": {"name": "zhangsan", "scores": {"math": {"mid-term": 88, "end-of-term": 90}}}}}Our goal is to obtain the data of Zhang's math scores in the third semester : 88
The recursive calls implemented are as follows :
def super_get(data: Union[dict, list], keys: List[Union[str, int]]): assert isinstance(data, dict) or isinstance(data, list), " Only dictionary and list types are supported " key = keys[0] if isinstance(data, list) and isinstance(key, int): try: new_data = data[key] except IndexError as exc: raise IndexError(" The index value is greater than the list length ") from exc elif isinstance(data, dict) and isinstance(key, str): new_data = data.get(key) else: raise ValueError(f" data type ({type(data)}) And index value type (f{type(key)} Mismatch ") if len(keys) == 1: return new_data if not isinstance(new_data, dict) and not isinstance(new_data, list): raise ValueError(" The corresponding value cannot be found ") return super_get(new_data, keys[1:])Then execute the code :
def get2(): data = {"message": "success", "data": {"data": {"zhangsan": {"scores": {"math": {"mid-term": 88, "end-of-term": 90}}}}}} print(super_get(data, ["data", "data", "zhangsan", "scores", "math", "mid-term"])) # Output 88 data = {"message": "success", "data": {"data": {"zhangsan": {"scores": {"math": [88, 90]}}}}} print(super_get(data, ["data", "data", "zhangsan", "scores", "math", 0])) # Output 88 data = {"message": "success", "data": {"data": {"zhangsan": {"scores": {"math": [88, 90]}}}}} print(super_get(data, ["data", "data", "zhangsan", "scores", "math", -1])) # Output 90 Third party Library In fact, there is a powerful Grammar Library , such as jq, But after all, there is one more dependency , And it needs a certain learning cost , however , If you decide you need more grammar , Then you can install a third-party library .
summaryIf you encounter deep nesting , Recursion is always a good solution , If you really can't think of a better algorithm , Then find a third-party library , Transfer the library , No shame .
Source code address :https://github.com/youerning/blog/tree/master/py_yaml_nested_data
That's all Python Handle yaml And nested data structure techniques , More about Python Handle yaml For information about nested data structures, please pay attention to other related articles on the software development network !