Due to the recent research on reptile related knowledge , Sometimes it is acquired frequently ( Crawling ) Web site data will appear ip The restricted situation makes it impossible to obtain the desired data in time , So I thought I should do ip proxy pool La , Don't say anything and start doing .
import re
import json
import requests
import urllib
from lxml import etree
url = 'https://raw.githubusercontent.com/fate0/proxylist/master/proxy.list'
class GetIpProxyPool(object):
ping_url = 'https://blog.csdn.net/DanielJackZ/article/details/106870071'
def __init__(self, url):
self.url = url
self.get_proxy_data()
def get_proxy_data(self):
result = requests.get(self.url).text
self.store_data(result)
def store_data(self, data):
f = open('./res.txt', 'w+')
f.write(data)
f.close()
def get_read_lines(self):
f = open('./res.txt', 'rb')
lines = f.readlines()
return lines
def validate_proxy(self):
f = open('./useful.txt', 'w+')
lines = self.get_read_lines()
for line in lines:
line = json.loads(line.strip())
proxy_ip = {
line.get('type'): line.get('host')}
proxy_support = urllib.request.ProxyHandler(proxy_ip)
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')]
urllib.request.install_opener(opener)
try:
response = urllib.request.urlopen(self.ping_url, timeout=5)
except:
pass
if response.read().decode('utf-8'):
f.write(json.dumps(line) + '\n')
if __name__ == "__main__":
proxy_pool = GetIpProxyPool(url)
proxy_pool.validate_proxy()
This part of the code is in validate_proxy To realize ip The proxy code section is :
.request.ProxyHandler(proxy_ip)
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')]
urllib.request.install_opener(opener)
In the verification of ip A more stupid method is used in the effective and available methods : Let the obtained ip Go to a website , Judge whether the access result is normal , If the request content can be obtained normally, it is valid by default. Otherwise, it is invalid , We will optimize this part of the code later
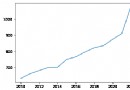
When we build individuals through the above steps IP After the agent pool , Can we simply solve the problem when we are acquiring data IP Be limited to this one question , Of course not. There are so many things that this thing can do , Here I give a simple application scenario , When we write a blog, we find that the reading volume is very low. If we want to brush more visits, we can also use an agent ip To access the corresponding links , To achieve the purpose of increasing traffic (note: This is just a simple example of an application scenario. We should still look at the blog traffic according to the normal traffic )
import os
import json
import requests
from lxml import etree
from urllib import request
def get_blog_list(blog_list_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15'
}
html = requests.get(blog_list_url, headers=headers).text
selector = etree.HTML(html)
data = selector.xpath('//*[@id="articleMeList-blog"]/div[2]/div//a/@href')
return data
def brush_visits(data):
f = open(os.path.join(os.path.dirname(__file__), 'useful.txt'))
for line in f.readlines():
line = json.loads(line)
proxy_ip = {
line.get('type'): line.get('host')}
print('>>>', proxy_ip)
proxy_support = request.ProxyHandler(proxy_ip)
opener = request.build_opener(proxy_support)
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')]
for link in data:
print('brush>>>', link)
request.urlopen(link)
# This address can be changed into the blog list under your account
blog_list_url = 'https://blog.csdn.net/xxxxx'
data = get_blog_list(blog_list_url)
brush_visits(data)
Project source address