Resource download address :https://download.csdn.net/download/sheziqiong/85697758
Resource download address :https://download.csdn.net/download/sheziqiong/85697758
It is divided into four aspects
Data processing
Feature Engineering
The model of choice
Integrated approach
Delete columns that are not related to the target value , for example “SaleID”,“name”. You can dig here “name” As a new feature .
Exception handling , Delete training set specific data , Delete... For example “seller”==1 Value .
Missing value processing , Classification feature filling mode , Continuous feature fill average .
Other special treatment , Delete the column with unchanged value .
Exception handling , According to the title “power” be located 0~600, So the “power”>600 The value of is truncated to 600, hold "notRepairedDamage" Replace the non numeric value of with np.nan, Let the model handle itself .
Time and region from “regDate”,“creatDate” You can get years 、 month 、 And a series of new features , Then we can get the new features of using age and using days .
“regionCode” There is no reservation .
Because I tried a series of methods , And found a possible leak “price”, Therefore, this feature is not retained in the end .
Classification features Classify the continuous features that can be classified ,kilometer It has been divided into buckets .
Then on "power" and "model" We divided the barrels .
Use classification features “brand”、“model”、“kilometer”、“bodyType”、“fuelType” And “price”、“days”、“power” Perform feature crossover .
The main result of crossover is the total number of the latter 、 variance 、 Maximum 、 minimum value 、 The average 、 The number of 、 Kurtosis, etc
There are a lot of new features available here , When it comes to selection , Use it directly lightgbm Help us to select features , Put them in groups , Finally, the following features are retained .( Be careful : Here is the use of 1/4 The selection of training sets can help us lock in the real Work Characteristics of )
'model_power_sum','model_power_std','model_power_median', 'model_power_max','brand_price_max', 'brand_price_median','brand_price_sum', 'brand_price_std','model_days_sum','model_days_std','model_days_median', 'model_days_max','model_amount','model_price_max','model_price_median','model_price_min','model_price_sum', 'model_price_std', 'model_price_mean' Continuous feature Anonymous features with high confidence ranking are used “v_0”、“v_3” And “price” Cross over , The test method is the same as above , The effect is not ideal .
Because they are all anonymous , Compare the distribution of training set and test set , Basically, there is no problem after the analysis , And they're in lightgbm The importance of the output is very high , So let's keep it all for the time being .
Supplementary feature engineering It mainly deals with features with very high output importance
Phase I of the characteristic project :
Yes 14 Anonymous features are obtained by multiplication 14*14 Features
Use sklearn Automatic feature selection helps us to filter , It has been running for about half a day . The general method is as follows :
The final screening results in :
'new3*3', 'new12*14', 'new2*14','new14*14' Characteristic project phase II :
Yes 14 Anonymous features are obtained by adding 14*14 Features
Do not choose to use automatic feature selection this time , Because it's too slow , Notebooks can't afford .
Then I tried to put it all in first lightgbm Whether the training is effective , The result of the surprise discovery is very obvious , Because there are many newly generated features , Therefore, some redundant features should be deleted .
The method used is to delete variables with high correlation , Record the features to be deleted roughly as follows :( Remove the correlation >0.95 Of )
The final feature that should be deleted is :
['new14+6', 'new13+6', 'new0+12', 'new9+11', 'v_3', 'new11+10', 'new10+14','new12+4', 'new3+4', 'new11+11', 'new13+3', 'new8+1', 'new1+7', 'new11+14','new8+13', 'v_8', 'v_0', 'new3+5', 'new2+9', 'new9+2', 'new0+11', 'new13+7', 'new8+11','new5+12', 'new10+10', 'new13+8', 'new11+13', 'new7+9', 'v_1', 'new7+4', 'new13+4', 'v_7', 'new5+6', 'new7+3', 'new9+10', 'new11+12', 'new0+5', 'new4+13', 'new8+0', 'new0+7', 'new12+8', 'new10+8', 'new13+14', 'new5+7', 'new2+7', 'v_4', 'v_10','new4+8', 'new8+14', 'new5+9', 'new9+13', 'new2+12', 'new5+8', 'new3+12', 'new0+10','new9+0', 'new1+11', 'new8+4', 'new11+8', 'new1+1', 'new10+5', 'new8+2', 'new6+1','new2+1', 'new1+12', 'new2+5', 'new0+14', 'new4+7', 'new14+9', 'new0+2', 'new4+1','new7+11', 'new13+10', 'new6+3', 'new1+10', 'v_9', 'new3+6', 'new12+1', 'new9+3','new4+5', 'new12+9', 'new3+8', 'new0+8', 'new1+8', 'new1+6', 'new10+9', 'new5+4', 'new13+1', 'new3+7', 'new6+4', 'new6+7', 'new13+0', 'new1+14', 'new3+11', 'new6+8', 'new0+9', 'new2+14', 'new6+2', 'new12+12', 'new7+12', 'new12+6', 'new12+14', 'new4+10', 'new2+4', 'new6+0', 'new3+9', 'new2+8', 'new6+11', 'new3+10', 'new7+0','v_11', 'new1+3', 'new8+3', 'new12+13', 'new1+9', 'new10+13', 'new5+10', 'new2+2','new6+9', 'new7+10', 'new0+0', 'new11+7', 'new2+13', 'new11+1', 'new5+11', 'new4+6', 'new12+2', 'new4+4', 'new6+14', 'new0+1', 'new4+14', 'v_5', 'new4+11', 'v_6', 'new0+4','new1+5', 'new3+14', 'new2+10', 'new9+4', 'new2+6', 'new14+14', 'new11+6', 'new9+1', 'new3+13', 'new13+13', 'new10+6', 'new2+3', 'new2+11', 'new1+4', 'v_2', 'new5+13','new4+2', 'new0+6', 'new7+13', 'new8+9', 'new9+12', 'new0+13', 'new10+12', 'new5+14', 'new6+10', 'new10+7', 'v_13', 'new5+2', 'new6+13', 'new9+14', 'new13+9','new14+7', 'new8+12', 'new3+3', 'new6+12', 'v_12', 'new14+4', 'new11+9', 'new12+7','new4+9', 'new4+12', 'new1+13', 'new0+3', 'new8+10', 'new13+11', 'new7+8','new7+14', 'v_14', 'new10+11', 'new14+8', 'new1+2']] Feature Engineering III 、 Four issues :
The effect of these two phases is not obvious , To avoid feature redundancy , So I chose not to add the features of these two phases , The specific operation can be carried out in feature In the processed code .
In the padding for other missing values , After testing the effect , It is found that the filling mode is better than the average , So the modes are filled in .
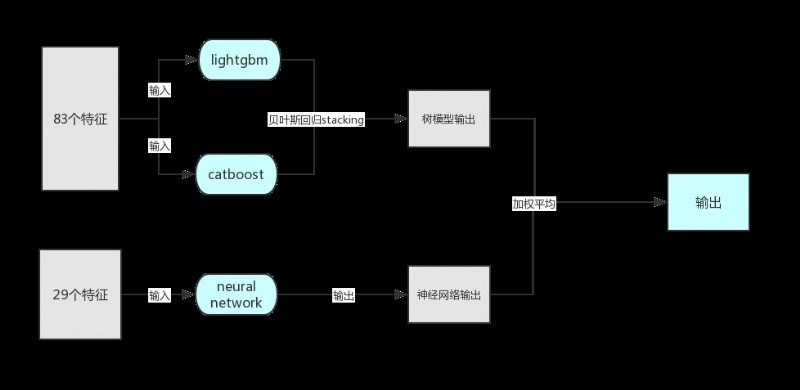
This competition , I chose lightgbm+catboost+neural network.
I wanted to use it XGBoost Of , But because it requires a second derivative , So the objective function does not MAE, And tried to approach MAE The effect of some user-defined functions is not ideal , So I didn't choose to use it .
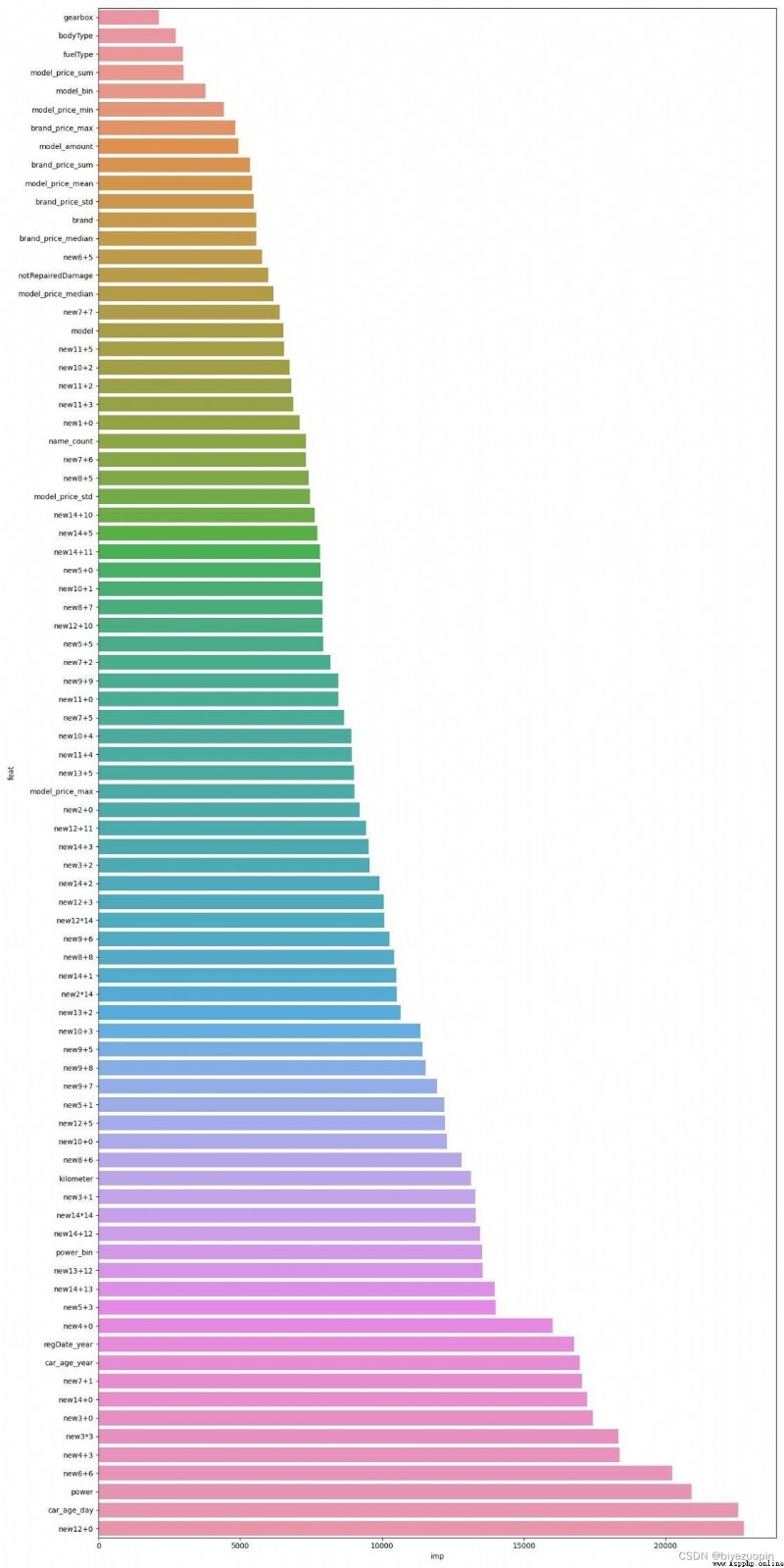
After the above data preprocessing and Feature Engineering :
The inputs to the tree model are 83 Features ; The inputs of the neural network are 29 Features .
neural network:
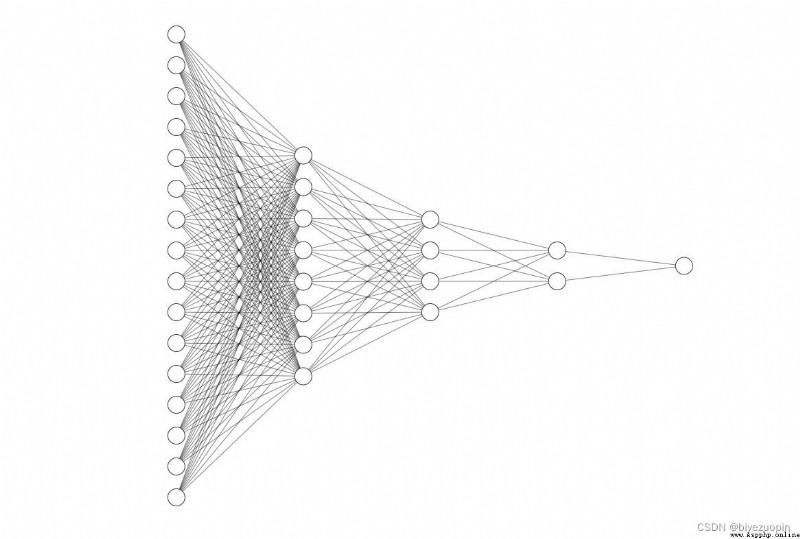
I am aiming at this competition , I designed a five layer neural network , The general frame is shown in the figure above , However, due to too many nodes, only part of the nodes are displayed .
The following is the setting for the number of nodes in the full connection layer , Specific implementation can refer to the code .

Next, the neural network is analyzed in detail :
First of all : The training model uses small batchsize,512, Although there may be a small deviation in the descending direction , But the benefit of convergence speed is great ,2000 It can converge within a generation .
second : Neural networks don't have to worry a lot about feature engineering , We can achieve the same precision as the tree model .
Third : Adjust the regularization coefficient , Using regularization , Prevent over fitting .
Fourth : Adjust the learning rate , Analyze the error in the training process , Choose the time when the learning rate drops to adjust .
The fifth : Use cross validation , Use 10 fold cross validation , Reduce over fitting .
The sixth : The optimizer that selects gradient descent is Adam, It is an optimizer with good comprehensive ability at present , High computational efficiency , Less memory requirements and so on .
Because the training data of the two tree models are the same and the structure is similar , First, the two tree models are analyzed stacking, Then it is compared with the output of the neural network mix.
Because tree model and neural network are completely different architectures , They get similar score outputs , The predicted values vary greatly , Often in MAE The difference is 200 about , So let them MIX You can get a better result , Weighted average selection coefficient selection 0.5, Although the score of neural network will be a little higher than that of tree model , But our highest score is the combination of multiple groups of online optimal outputs , So we can make up for each other's advantages .
The given code is the result of one output , If the online results are perfectly reproduced , Have to output several more times to select Top-3 Averaging .
Due to the 10% discount cross verification and very small learning rate selected in the later part of the scoring , Slow operation , You can use 50% discount and higher learning rate to test the effect ~
|--dataTraining set 、 Test set , It can be downloaded from the official website of the competition
|--user_dataSome files generated in the middle of the code , It is convenient to observe during the competition
|--prediction_resultOutput submission text
|--feature|--model |--code perform :( Enter this directory , Execute the following command to generate a forecast data ) python main.py PS: Actually main It's me who put feature and model All of the code is copied and thrown in .
Resource download address :https://download.csdn.net/download/sheziqiong/85697758
Resource download address :https://download.csdn.net/download/sheziqiong/85697758
author :biyezuopin
Game programming , A game development favorite ~
If the picture is not displayed for a long time , Please use Chrome Kernel browser .