Catalog
request Basic use of
urllib Use
Image crawling
Get dynamic data
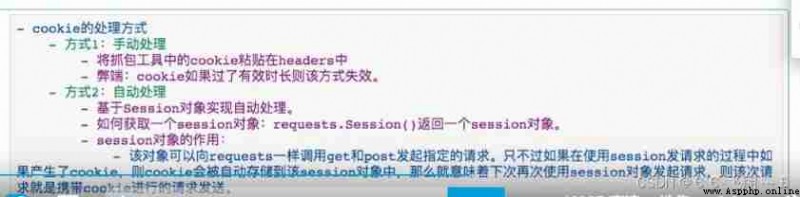
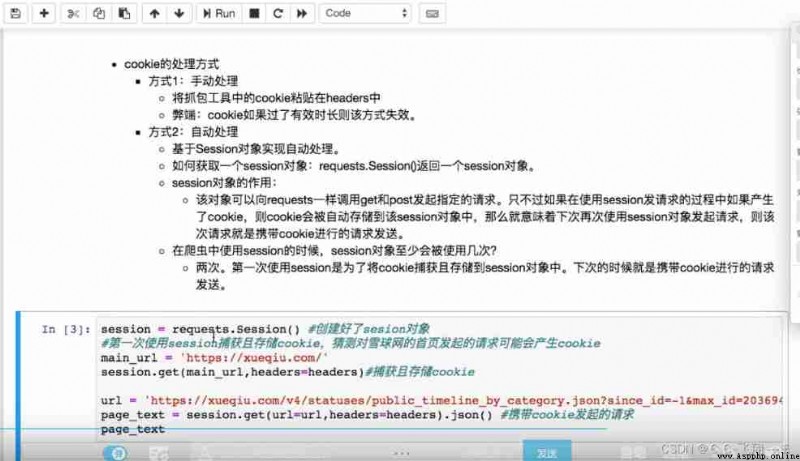
session and cokkie To deal with
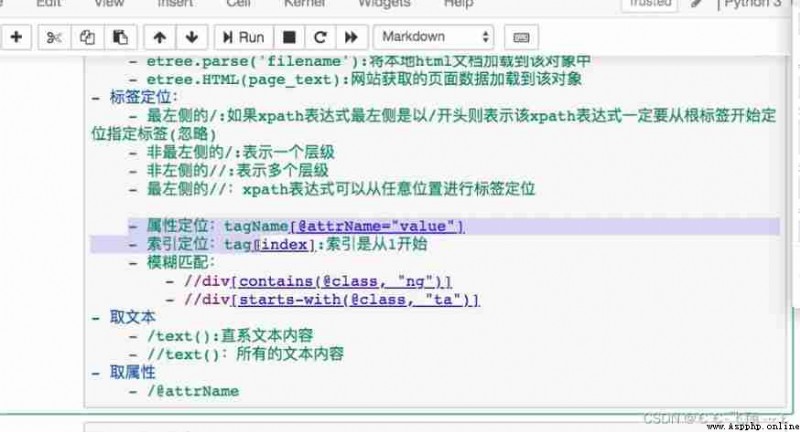
Use xpath analysis
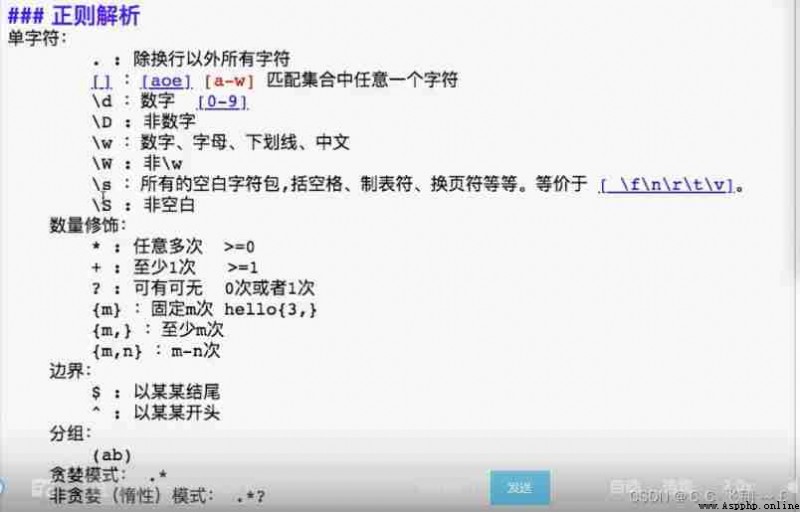
Using regular parsing
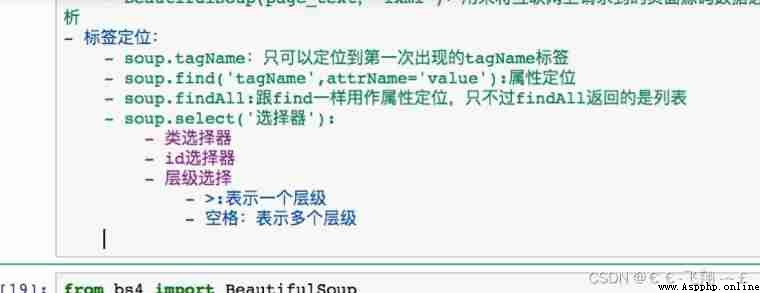
BeautifulSoup Use
seleium Automated crawler
Other automated operations
Realize no interface
Automated processing iframe label
be based on selenium Of 12306 The user login
Use of agents
Verification code resolution
Use of process
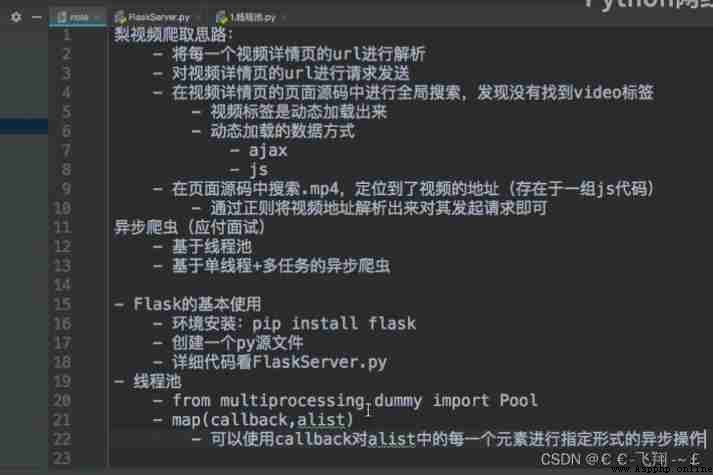
Synchronized crawler
The use of multithreaded asynchronous crawlers
Thread pool
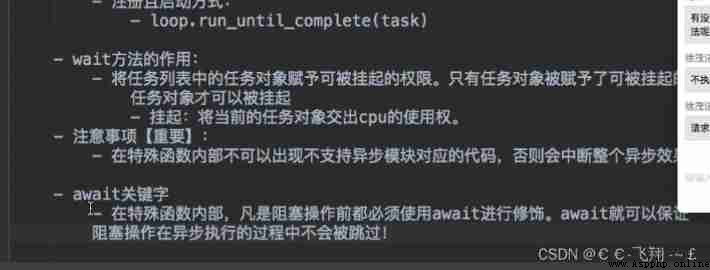
Asynchronous coroutine
aiohttp Implement task asynchronous collaboration
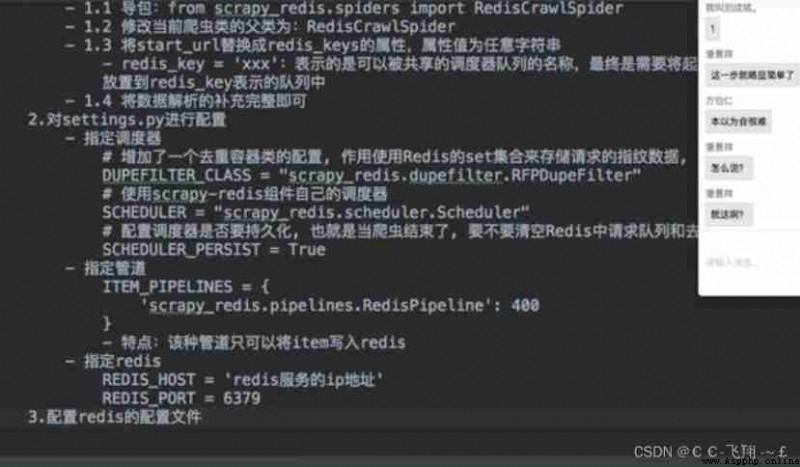
Distributed crawlers
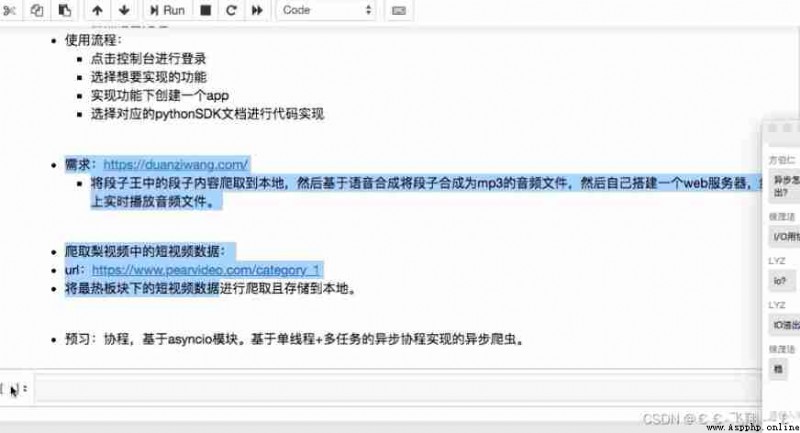
Simple hand training project
KFC cracking
Crawl the resume template
Baidu AI Implement reptiles
It was done a long time ago python The notes of the complete collection of non frame crawlers have not been sorted out , I have time to tidy up today , Easy to check later .
Case a
# -*- coding: utf-8 -*-
import requests
if __name__ == "__main__":
# step 1: Appoint url
url = 'https://www.sogou.com/'
# step 2: Initiate request
response = requests.get(url=url)
# step 3: Get response data .text What is returned is the response data in the form of string
page_text = response.text
print(page_text)
# step_4: Persistent storage
with open('./sogou.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(' End of crawling data !!!')
Case 2 :
# -*- coding: utf-8 -*-
import requests
import json
if __name__ == "__main__":
url = 'https://movie.douban.com/j/search_subjects'
param = {
'type': 'movie',
'tag': " comedy ",
'sort': 'recommend',
'page_limit': 20, # Number of pieces taken out at one time
'page_start': 20, # Pick up the first few movies in the library
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
response = requests.get(url=url, params=param, headers=headers)
list_data = response.json()
fp = open('./douban.json', 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
print('over!!!')
Case three
# -*- coding: utf-8 -*-
import requests
import json
if __name__ == "__main__":
# 1. Appoint url
post_url = 'https://fanyi.baidu.com/sug'
# 2. Conduct UA camouflage
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
# 3. Request parameter processing ( Same as get The request is unanimous )
word = input('enter a word:')
data = {
'kw': word
}
# 4. Request to send
response = requests.post(url=post_url, data=data, headers=headers)
# 5. Get response data :json() Method returns obj_( If the confirmation response data is json Type of , Can be used json())
dic_obj = response.json()
# Persistent storage
fileName = word + '.json'
fp = open(fileName, 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)
print('over!!!')
Case four
# -*- coding: utf-8 -*-
# Each crawl requires UA camouflage , Disguised as a browser
# User-Agent( Request carrier birthmark )
import requests
if __name__ == "__main__":
# UA camouflage : The corresponding User-Agent Encapsulated in a dictionary
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
url = 'https://www.sogou.com/web'
# Handle url Parameters carried : Encapsulated in a dictionary
kw = input('enter a word:')
param = {
'query': kw
}
# For the specified url The request initiated corresponds to url It carries parameters , And the parameters are processed in the request process
response = requests.get(url=url, params=param, headers=headers)
page_text = response.text
fileName = kw + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(fileName, ' Saved successfully !!!')
import requests
import re
import os
import urllib
dirName = "imgLab"
if not os.path.exists(dirName):
os.mkdir(dirName)
url = "https://www.baidu.com/s?wd=%E7%8B%97&tn=98012088_5_dg&ch=11"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37',
}
response = requests.get(url=url, headers=headers)
page_text = response.text
ex = '<div class="op-img-address-divide-high">.*?<img src="(.*?)" class=.*?</div>'
img_src_list = re.findall(ex, page_text, re.S)
for src in img_src_list:
imgPath = dirName + "/" + src.split('/')[-1]
src = src + '&fm=26'
urllib.request.urlretrieve(src, imgPath)
print(imgPath, ' Download successful !')
Case a
from lxml import etree
import requests
import os
import urllib
fileName = " picture "
if not os.path.exists(fileName):
os.mkdir(fileName)
url = "https://pic.netbian.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="main"]/div[3]/ul/li')
arr = []
for li in li_list:
href = 'https://pic.netbian.com' + li.xpath(' ./a/span/img/@src')[0]
arr.append(href)
for ar in arr:
filePath = fileName + '/' + ar.split('/')[-1]
urllib.request.urlretrieve(ar, filePath)
print(" End of climb !!!")
Case 2
# -*- coding: utf-8 -*-
import requests
if __name__ == "__main__":
# How to crawl image data
url = 'https://th.bing.com/th/id/R6706ad2e7a68edabddbc1b5644707c4f?rik=u8uR%2bWe5bxIosA&riu=http%3a%2f%2fpic.lvmama.com%2fuploads%2fpc%2fplace2%2f2016-09-14%2f9aab9bb7-2593-4ca6-8c5a-31355443aebc.jpg&ehk=HpOwqU6w6%2fssF4CJQMbTOshMh4lIXJONXU%2btYNsAKSI%3d&risl=1&pid=ImgRaw'
# content The returned image data is in binary form
# text( character string ) content( Binary system ) json() ( object )
img_data = requests.get(url=url).content
with open('./qiutu.jpg', 'wb') as fp:
fp.write(img_data)
# -*- coding: utf-8 -*-
import requests
import json
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
# Batch access to information from different enterprises id value
url = ''
# Parameter encapsulation
id_list = [] # Storage enterprise id
all_data_list = [] # Store all enterprise detail data
for page in range(1, 6):
page = str(page)
data = {
}
json_ids = requests.post(url=url, headers=headers, data=data).json()
for dic in json_ids['list']:
id_list.append(dic['ID'])
# Get all the details of the enterprise
post_url = ''
for id in id_list:
data = {
'id': id
}
detail_json = requests.post(url=url, headers=headers, data=data).json()
all_data_list.append(detail_json)
# Persistent storage all_data_list
fp = open('./allData.json', 'w', encoding='utf-8')
json.dump(all_data_list, fp=fp, ensure_ascii=False)
print('over!!!')

Case a
# -*- coding: utf-8 -*-
from lxml import etree
if __name__ == '__main__':
# Instantiate a etree object , And the parsed source code is loaded into the object
tree = etree.parse('r.html')
# r=tree.xpath('/html/body/div')
# r=tree.xpath('/html//div')
# r=tree.xpath('//div')
# r=tree.xpath('//div[@class="song"]')
# r=tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0]
# r=tree.xpath('//li[7]//text()')
# r=tree.xpath('//div[@class="tang"]//text()')
r = tree.xpath('//div[@class="song"]/img/@src')
print(r)
Case 2
# -*- coding: utf-8 -*-
# demand : Crawling 58 Housing information of second-hand houses
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/53'
}
# Crawl to the page source code data
url = 'https://www.58.com/ershoufang/'
page_text = requests.get(url=url, headers=headers).text
# Data analysis
tree = etree.HTML(page_text)
# What is stored is the label object
td_list = tree.xpath('//td[@class="t"]')
fp = open('58.txt', 'w', encoding='utf-8')
for td in td_list:
title = td.xpath('./a/text()')[0]
print(title)
fp.write(title + '\n')
fp.close()
Case three
# -*- coding: utf-8 -*-
# demand : Analyze and download image data
import requests
from lxml import etree
import os
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/53'
}
# Crawl to the page source code data
url = 'https://pic.netbian.com/4kyouxi/'
response = requests.get(url=url, headers=headers)
# Manually set the response data encoding format
# response.encoding='utf-8'
page_text = response.text
# Data analysis
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
# Create a folder
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0] + '.jpg'
# General solution to Chinese garbled code
img_name = img_name.encode('iso-8859-1').decode('gbk')
# print(img_name,img_src)
# Request pictures for persistent storage
img_data = requests.get(url=img_src, headers=headers).content
img_path = 'picLibs/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, ' Download successful !!!')
Case four
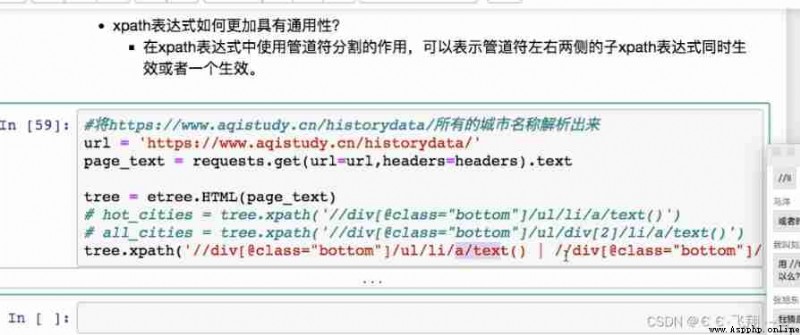
# -*- coding: utf-8 -*-
# demand : Resolve all city names
import requests
from lxml import etree
if __name__ == "__main__":
'''headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/53'
}
# Crawl to the page source code data
url='https://www.aqistudy.cn/historydata/'
response=requests.get(url=url,headers=headers)
# Manually set the response data encoding format
#response.encoding='utf-8'
page_text=response.text
# Data analysis
tree=etree.HTML(page_text)
host_li_list=tree.xpath('//div[@class="bottom"]/ul/li')
all_city_names=[]
# Resolve to the name of a popular city
for li in host_li_list:
hot_city_name=li.xpath('./a/text()')[0]
all_city_names.append(hot_city_name)
# Resolve the names of all cities
city_names_list=tree.xpath('div[@class="bottom"]/ul/div[2]/li')
for li in city_names_list:
city_name=li.xpath('./a/text()')[0]
all_city_names.append(city_name)
print(all_city_names,len(all_city_names))'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/53'
}
# Crawl to the page source code data
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url=url, headers=headers)
# Manually set the response data encoding format
# response.encoding='utf-8'
page_text = response.text
# Data analysis
tree = etree.HTML(page_text)
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/div[2]/li/a')
all_city_names = []
for a in a_list:
city_name = a.xpath('./text()')[0]
all_city_names.append(city_name)
print(all_city_names, len(all_city_names))
Case a
# -*- coding: utf-8 -*-
import requests
import re
import os
# demand : Crawl all the embarrassing pictures under the embarrassing picture section in the embarrassing encyclopedia
if __name__ == '__main__':
# Create a folder , Save all the pictures
if not os.path.exists('./qiutuLibs'):
os.mkdir('./qiutuLibs')
url = 'https://www.qiushibaike.com/imgrank/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
# Use the universal crawler to url Corresponding to a whole page
page_text = requests.get(url=url, headers=headers).text
# Use the focused crawler to crawl all the embarrassing images in the page
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
img_src_list = re.findall(ex, page_text, re.S)
# print(img_src_list)
for src in img_src_list:
# Splice a complete picture url
src = 'https:' + src
# The binary data of the picture is requested
img_data = requests.get(url=src, headers=headers).content
# Generate picture name
img_name = src.split('/')[-1]
# The path where the picture is finally stored
imgPath = './qiutuLibs/' + img_name
with open(imgPath, 'wb') as fp:
fp.write(img_data)
print(img_name, ' Download successful !!!')
Case 2
# -*- coding: utf-8 -*-
import requests
import re
import os
# demand : Crawl all the embarrassing pictures under the embarrassing picture section in the embarrassing encyclopedia
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
# Create a folder , Save all the pictures
if not os.path.exists('./qiutuLibs'):
os.mkdir('./qiutuLibs')
# Set up a general url Templates
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
for pageNum in range(1, 3):
# Corresponding to the page url
new_url = format(url % pageNum)
page_text = requests.get(url=new_url, headers=headers).text
# Use the focused crawler to crawl all the embarrassing images in the page
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
img_src_list = re.findall(ex, page_text, re.S)
# print(img_src_list)
for src in img_src_list:
# Splice a complete picture url
src = 'https:' + src
# The binary data of the picture is requested
img_data = requests.get(url=src, headers=headers).content
# Generate picture name
img_name = src.split('/')[-1]
# The path where the picture is finally stored
imgPath = './qiutuLibs/' + img_name
with open(imgPath, 'wb') as fp:
fp.write(img_data)
print(img_name, ' Download successful !!!')
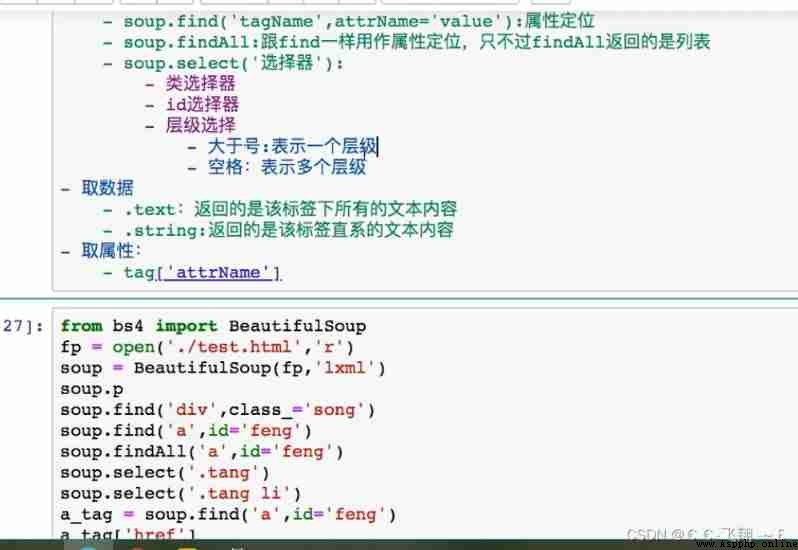
Case a
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
if __name__=='__main__':
# Crawl the page data of the home page
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76'
}
url='https://www.shicimingju.com/book/sanguoyanyi.html'
page_text=requests.get(url=url,headers=headers)
page_text.encoding='utf-8'
page_text=page_text.text
# Analyze the title and details of the chapter in the front page url
#1. Instantiation BeautifulSoup object , You need to load the page source code data into the object
soup=BeautifulSoup(page_text,'lxml')
# Analyze chapter titles and details url
li_list=soup.select('.book-mulu>ul>li')
fp=open('./sanguo.txt','w',encoding='utf-8')
for li in li_list:
title=li.a.string
detail_url='https://www.shicimingju.com'+li.a['href']
# Make a request to the details page , Analyze the contents of the chapter
detail_page_text=requests.get(url=detail_url,headers=headers)
detail_page_text.encoding='utf-8'
detail_page_text=detail_page_text.text
# Analyze the relevant chapters in the details page
detail_soup=BeautifulSoup(detail_page_text,'lxml')
div_tag=detail_soup.find('div',class_='chapter_content')
# Resolved to the content of the chapter
content=div_tag.text
fp.write(title+':'+content+'\n')
print(title,' Climb to success !!!')Case 2
from bs4 import BeautifulSoup
import requests
import os
fileName = 'novel'
if not os.path.exists(fileName):
os.mkdir(fileName)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37',
'Connection': 'close'
}
url = "https://www.shicimingju.com/book/sanguoyanyi.html"
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
title = soup.select('.book-mulu > ul > li > a')
cnt = 0
for t in title:
href = 'https://www.shicimingju.com' + t['href']
response = requests.get(url=href, headers=headers)
response.encoding = 'utf-8'
page_text = response.text
soup = BeautifulSoup(page_text, 'lxml')
div = soup.find('div', class_='card bookmark-list')
filePath = fileName + '/' + t.string + '.txt'
pageTxt = div.text
with open(filePath, 'w', encoding='utf-8') as fp:
fp.write(pageTxt)
print(' Climb to success !!!')
cnt += 1
if cnt == 10:
break

solve iframe problem 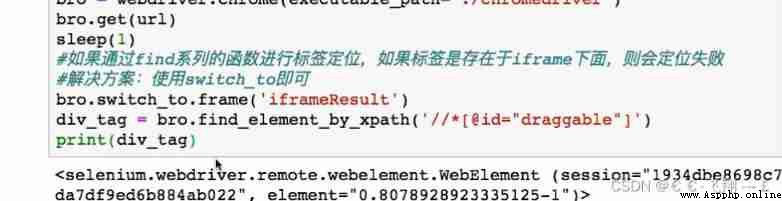
Case a
# -*- coding: utf-8 -*-
# demand : Simulated Login
from selenium import webdriver
from time import sleep
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.get('https://qzone.qq.com/')
bro.switch_to.frame('login_frame')
a_tag = bro.find_element_by_id("switcher_plogin")
a_tag.click()
userName_tag = bro.find_element_by_id('u')
password_tag = bro.find_element_by_id('p')
sleep(1)
userName_tag.send_keys('1292161328')
sleep(1)
password_tag.send_keys('1234567890')
sleep(1)
btn = bro.find_element_by_id('login_button')
btn.click()
sleep(3)
bro.quit()
Case 2
# -*- coding: utf-8 -*-
from selenium import webdriver
from lxml import etree
from time import sleep
# Instantiate a browser object ( Incoming driver )
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.add_argument('-kiosk')
# Let the browser initiate a specified url Corresponding request
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
# Get the page source code data of the current page of the browser
page_text = bro.page_source
# Resolve enterprise name
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@id="gzlist"]/li')
for li in li_list:
name = li.xpath('./dl/@title')[0]
print(name)
sleep(5)
bro.quit()
Case three
from selenium import webdriver
from time import sleep
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.get('http://www.taobao.com/')
# Achieve label positioning
search_input = bro.find_element_by_id('q')
# Tag interaction
search_input.send_keys('Iphone')
# Perform a group of js Program
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
# Click the search button
btn = bro.find_element_by_css_selector('.btn-search')
btn.click()
bro.get('https://www.baidu.com')
sleep(2)
# Back off
bro.back()
sleep(2)
# Forward
bro.forward()
sleep(5)
bro.quit()
Case four
# -*- coding: utf-8 -*-
from selenium import webdriver
from time import sleep
# Realize no visual interface
from selenium.webdriver.chrome.options import Options
# Implementation of circumvention detection
from selenium.webdriver import ChromeOptions
# Realize the operation without visual interface
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# Implementation of circumvention detection
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# How to achieve selenium Risk aversion
bro = webdriver.Chrome(executable_path='./chromedriver', chrome_options=chrome_options, options=option)
# No visual interface ( Headless browser ) phantomJs
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()
Case 5
from selenium import webdriver
from time import sleep
# Behind it is your browser driver location , Remember to add it in front r'','r' Is to prevent character escape
driver = webdriver.Chrome(r'./chromedriver')
# use get Open Baidu page
driver.get("http://www.baidu.com")
# Find page “ Set up ” Options , And click
# driver.find_elements_by_link_text(' Set up ')[0].click()
# sleep(2)
# # # Open the settings and find “ Search settings ” Options , Set to display... Per page 50 strip
# driver.find_elements_by_link_text(' Search settings ')[0].click()
# sleep(2)
# # Check show per page 50 strip
# m = driver.find_element_by_id('nr')
# sleep(2)
# m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
# m.find_element_by_xpath('.//option[3]').click()
# sleep(2)
# # Click Save settings
# driver.find_elements_by_class_name("prefpanelgo")[0].click()
# sleep(2)
# # Handle the pop-up warning page determine accept() and Cancel dismiss()
# driver.switch_to_alert().accept()
# sleep(2)
# Find Baidu's input box , And enter the beauty
driver.find_element_by_id('kw').send_keys(' beauty ')
sleep(2)
# Click the search button
driver.find_element_by_id('su').click()
sleep(2)
# Find... On the open page “Selenium - Open source Chinese community ”, And open this page
driver.find_elements_by_link_text(' beauty _ Massive selection of HD pictures _ Baidu pictures ')[0].click()
sleep(3)
# Close the browser
driver.quit()Case 6
# -*- coding: utf-8 -*-
from selenium import webdriver
from time import sleep
# Import the class corresponding to the action chain
from selenium.webdriver import ActionChains
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
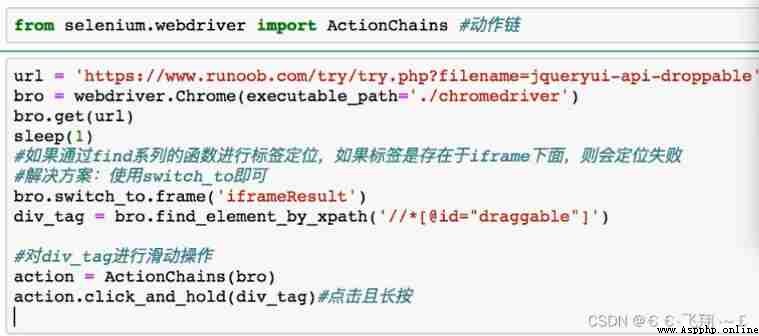
# If the positioning label is present in the iframe In the label, the following operations must be performed to locate the label
bro.switch_to.frame('iframeResult') # Switch the scope of browser label positioning
div = bro.find_element_by_id('draggable')
# Action chain
action = ActionChains(bro)
# Click and hold the tab
action.click_and_hold(div)
for i in range(5):
# perform() Perform the action chain operation immediately
# move_by_offset(x,y):x horizontal direction ,y In the vertical direction
action.move_by_offset(17, 0).perform()
sleep(0.3)
# Release the address chain
action.release()
print(div)
Case seven
# -*- coding: utf-8 -*-
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: Picture byte
codetype: Topic type Reference resources http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id: Picture of the wrong title ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
# Use elenium Open login page
from selenium import webdriver
import time
from PIL import Image
from selenium.webdriver import ActionChains
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.maximize_window() # Full screen
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(1)
# Click account to log in
bro.find_elements_by_link_text(' To login ')[0].click()
time.sleep(1)
# save_screenshot Take a screenshot of the current page and save
bro.save_screenshot('aa.png')
# Determine the coordinates of the upper left corner and the lower right corner of the captcha image ( Crop region determination )
code_img_ele = bro.find_element_by_css_selector('#J-loginImg')
location = code_img_ele.location # The coordinates of the upper left corner of the captcha image
print('location:', location)
size = code_img_ele.size # The length and width of the captcha label
print('size:', size)
# The coordinates of the upper left corner and the lower right corner
rangle = (
int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
# At this point, the captcha image area is determined
i = Image.open('./aa.png')
code_img_name = './code.png'
# crop Cut the picture according to the specified area
frame = i.crop(rangle)
frame.save(code_img_name)
# Give the verification code picture to super eagle for identification
chaojiying = Chaojiying_Client('1292161328', 'wuxiangnong', '915445') # User center >> Software ID Generate a replacement 96001
im = open('code.png', 'rb').read() # Local image file path To replace a.jpg Sometimes WIN The system needs //
print(chaojiying.PostPic(im, 9004)['pic_str'])
result = chaojiying.PostPic(im, 9004)['pic_str']
all_list = [] # To store the coordinates of the point to be hit [x1,y1][x2,y2]
if '|' in result:
list_1 = result.split('|')
count_1 = len(list_1)
for i in range(count_1):
xy_list = []
x = int(list_1[i].split(',')[0])
y = int(list_1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else:
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
print(all_list)
# Traverse the list , Use the action chain for each list element x,y Click at the specified location
for l in all_list:
x = l[0]
y = l[1]
ActionChains(bro).move_to_element_with_offset(code_img_ele, x, y).click().perform()
time.sleep(0.5)
bro.find_element_by_id('J-userName').send_keys('19828430139')
time.sleep(2)
bro.find_element_by_id('J-password').send_keys('wuxiangnong9595')
time.sleep(2)
bro.find_element_by_id('J-login').click()
time.sleep(3)
bro.quit()
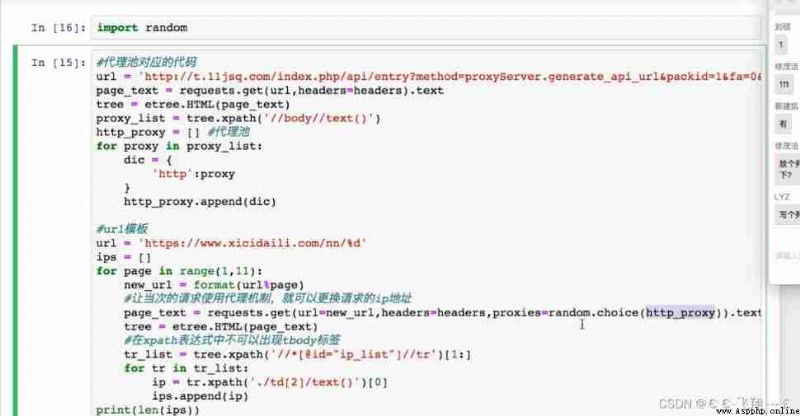
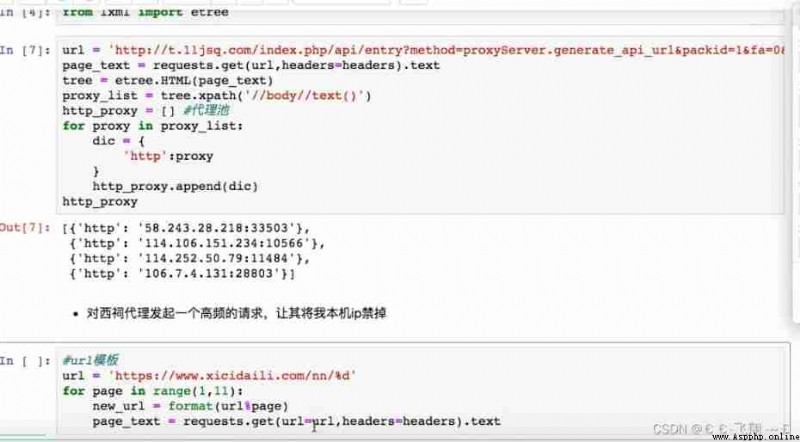
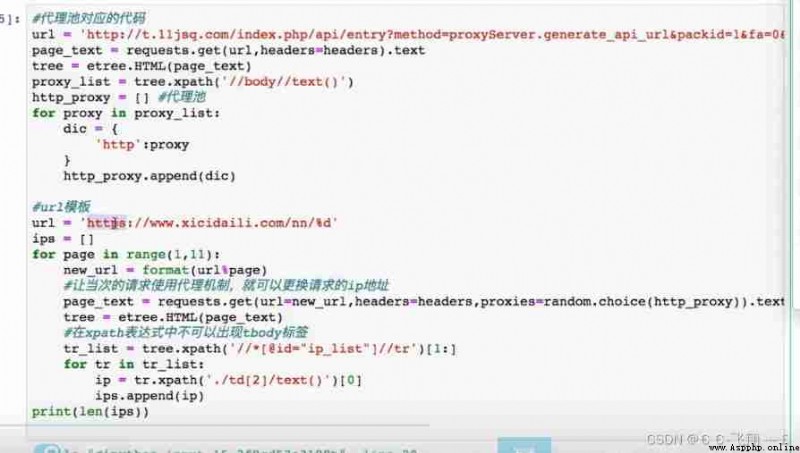

Case a
# -*- coding: utf-8 -*-
import requests
url = 'https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76'
}
page_text = requests.get(url=url, headers=headers, proxies={"https": "222.110.147.50:3128"})
with open('ip.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
# -*- coding: utf-8 -*-
import requests
from lxml import etree
''' Import a coding class '''
# Encapsulate the function of downloading the verification code image to the local
def getCodeText(imgPath, codeType):
# Common user name
username = 'bobo328410948'
# Ordinary user password
password = 'bobo328410948'
# Software ID, Developers are divided into necessary parameters . Log in to the developer background 【 My software 】 get !
appid = 6003
# Software key , Developers are divided into necessary parameters . Log in to the developer background 【 My software 】 get !
appkey = '1f4b564483ae5c907a1d34f8e2f2776c'
# Picture file : The path of the verification code image to be recognized
filename = imgPath
# Verification code type ,# example :1004 Express 4 Alphanumeric , Different types charge different fees . Please fill in exactly , Otherwise, the recognition rate will be affected . Query all types here http://www.yundama.com/price.html
codetype = codeType
# Timeout time , second
timeout = 20
result = None
# Check
if (username == 'username'):
print(' Please set relevant parameters before testing ')
else:
# initialization
yundama = YDMHttp(username, password, appid, appkey)
# Log in to the cloud and code
uid = yundama.login();
print('uid: %s' % uid)
# Check the balance
balance = yundama.balance();
print('balance: %s' % balance)
# Start identifying , Picture path , Verification code type ID, Timeout time ( second ), Recognition result
cid, result = yundama.decode(filename, codetype, timeout);
print('cid: %s, result: %s' % (cid, result))
return result
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76'
}
url = 'https://so.gushiwen.org/user/login.aspx'
page_text = requests.get(url=url, headers=headers).text
# Parse verification code picture img Attribute value in
tree = etree.HTML(page_text)
code_img_src = 'https://so.gushiwen.org' + tree.xpath('//*[@id="imgCode"]/@src')
img_data = requests.get(url=code_img_src, headers=headers).content
# The verification code image is saved locally
with open('./code.jpg', 'wb') as fp:
fp.write(img_data)
# Code
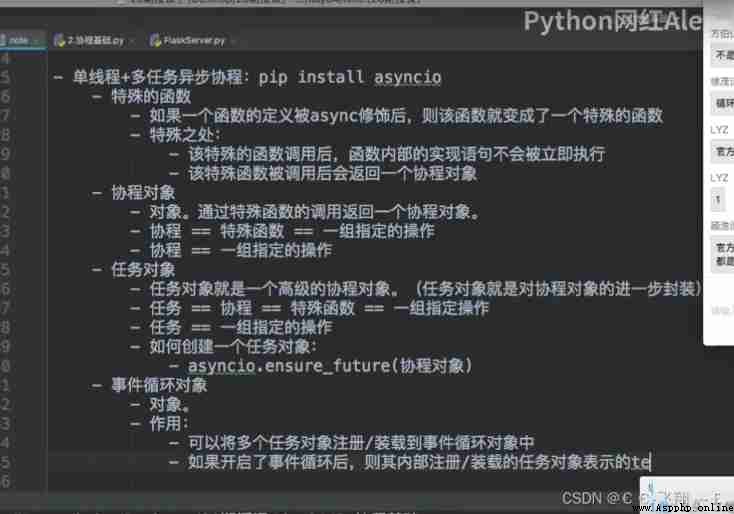
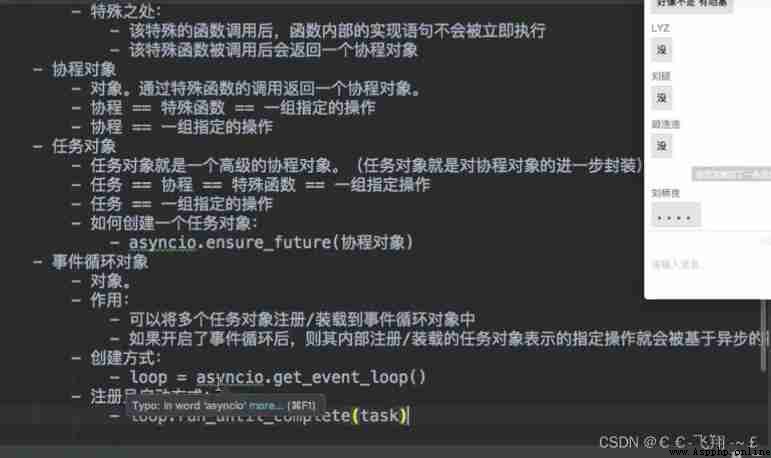
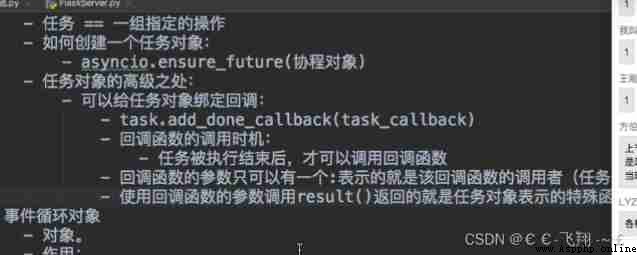
Case a
# -*- coding: utf-8 -*-
import asyncio
async def request(url):
print(' Asking for url yes ', url)
print(' The request is successful ', url)
return url
# async Modified function , A coroutine object returned after the call
c = request('www.baidu.com')
# Create an event loop object
# loop=asyncio.get_event_loop()
# # Register the collaboration object to loop in , Then start loop
# loop.run_until_complete(c)
# task Use
loop = asyncio.get_event_loop()
# be based on loop Create a task object
task = loop.create_task(c)
print(task)
# future Use
# loop=asyncio.get_event_loop()
# task=asyncio.ensure_future(c)
# print(task)
# loop.run_until_complete(task)
# print(task)
def callback_func(task):
# result The returned value is the return value of the function corresponding to the encapsulated object in the task object
print(task.result)
# Bind a callback
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(c)
# Bind the callback function to the task object
task.add_done_callback(callback_func)
loop.run_until_complete(task)
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76'
}
urls = {
'http://xmdx.sc.chinaz.net/Files/DownLoad/jianli/201904/jianli10231.rar',
'http://zjlt.sc.chinaz.net/Files/DownLoad/jianli/201904/jianli10229.rar',
'http://xmdx.sc.chinaz.net/Files/DownLoad/jianli/201904/jianli10231.rar'
}
def get_content(url):
print(' Crawling up :', url)
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
return response.content
def parse_content(content):
print(' The length of the response data is :', len(content))
for url in urls:
content = get_content(url)
parse_content(content)
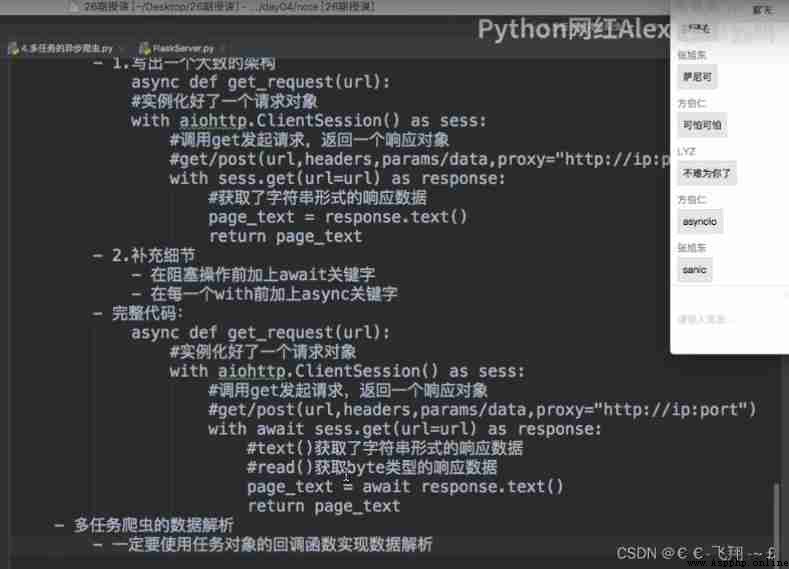
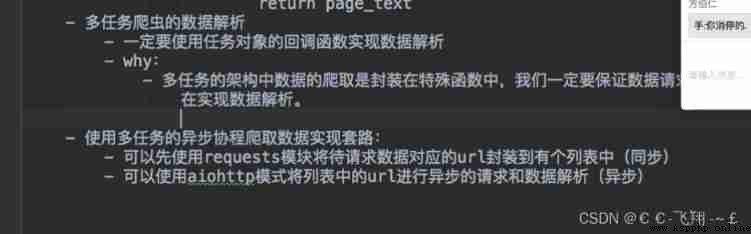
Case a
# -*- coding: utf-8 -*-
import asyncio
import time
async def request(url):
print(' Downloading ', url)
# If there are synchronous module related codes in the asynchronous process , Then you can't achieve asynchrony
# time.sleep(2)
# When in asyncio When blocking operation is encountered in, it must be suspended manually
await asyncio.sleep(2)
print(' The download ', url)
start = time.time()
urls = {
'www.baidu.com',
'www.sogou.com',
'www.goubanjia.com'
}
# Task object : Store multiple task objects
stasks = []
for url in urls:
c = request(url)
task = asyncio.ensure_future(c)
stasks.append(task)
loop = asyncio.get_event_loop()
# You need to encapsulate the task list into wait in
loop.run_until_complete(asyncio.wait(stasks))
print(time.time() - start)
Case 2
# -*- coding: utf-8 -*-
import requests
import asyncio
import time
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
async def get_page(url):
print(' Downloading ', url)
# requests.get The request is initiated based on synchronization , Must be specified based on the asynchronous network request module url
# aiohttp: Module based on asynchronous network request
response = requests.get(url=url)
print(response.text)
tasks = []
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(' Time consuming ', end - start)
Case three
# -*- coding: utf-8 -*-
import time
# Execution using single thread serial mode
def get_page(str):
print(" Downloading :", str)
time.sleep(2)
print(' Download successful :', str)
name_list = ['xiaozi', 'aa', 'bb', 'cc']
start_time = time.time()
for i in range(len(name_list)):
get_page(name_list[i])
end_time = time.time()
print('%d second' % (end_time - start_time))
Case four
# -*- coding: utf-8 -*-
import time
# Import the class of the module corresponding to the thread pool
from multiprocessing.dummy import Pool
# Execute in thread pool mode
start_time = time.time()
def get_page(str):
print(" Downloading :", str)
time.sleep(2)
print(' Download successful :', str)
name_list = ['xiaozi', 'aa', 'bb', 'cc']
# Instantiate a thread pool
pool = Pool(4)
# Pass each element of the list to get_page To deal with
pool.map(get_page, name_list)
end_time = time.time()
print(end_time - start_time)
Case 5
# -*- coding: utf-8 -*-
import time
import asyncio
import aiohttp
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
async def get_page(url):
async with aiohttp.ClientSession() as session:
# get()、post():
# headers,params/data,proxy='http://ip:port'
async with session.get(url) as response:
# text() You can return response data in string form
# read() Return response data in binary form
# json() Back to you json object
# Be careful : Be sure to use... Before getting the response data operation await Manually suspend
page_text = await response.text()
print(page_text)
tasks = []
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(' Time consuming ', end - start)

# -*- coding: utf-8 -*-
import requests
if __name__ == "__main__":
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
param = {
'cname': '',
'pid': '',
'keyword': ' Beijing ',
'pageIndex': '1',
'pageSize': '10',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75'
}
response = requests.get(url=url, params=param, headers=headers)
list_data = response.text
fp = open('./KFC.text', 'w', encoding='utf-8')
fp.write(list_data)
fp.close()
print('over!!!')
import requests
import os
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/53'
}
url = 'https://sc.chinaz.com/jianli/free.html'
page_text = requests.get(url=url, headers=headers).text
# Create folder
if not os.path.exists('./new'):
os.mkdir('./new')
# Instance object
tree = etree.HTML(page_text)
a_lists = tree.xpath('//div[@id="container"]/div/a')
for a in a_lists:
href = a.xpath('./@href')[0]
src = 'https:' + href
page_text_detail = requests.get(url=src, headers=headers).text
treeDetail = etree.HTML(page_text_detail)
a_lists_products = treeDetail.xpath('//div[@class="clearfix mt20 downlist"]/ul/li')[0]
href2 = a_lists_products.xpath('./a/@href')[0]
products_name = href2[-7:]
response = requests.get(url=href2, headers=headers)
data_products = response.content
data_path = 'new/' + products_name
with open(data_path, 'wb') as fp:
fp.write(data_products)
fp.close()
print(products_name, " Download successful !!!")