/home/disk1/lstm/venv/lib/python3.8/site-packages/sklearn/base.py:329: UserWarning: Trying to unpickle estimator MinMaxScaler from version 0.24.2 when using version 0.23.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
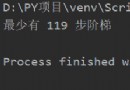
Process finished with exit code 245
在使用版本0.23.2時,嘗試從版本0.24.2取消勾選estimator MinMaxScaler 。
這會導致代碼中斷或者結果無效。使用風險自負。
程序完成,退出代碼245.
這個報錯是sklearn版本的問題。即模型訓練時的sklearn版本 0.24.2 和模型調用時的sklearn版本0.23.2不匹配。
版本不對的時候也會報下面的錯誤:
AttributeError: ‘MinMaxScaler’ object has no attribute ‘clip’
匹配訓練、調用模型的sklearn版本。
要麼把訓練模型的sklearn版本將為0.23.2;要麼把調用模型的sklearn版本升級為 0.24.2 。
我的解決方法是把調用模型的python工程sklearn環境升級版本,如下:
pip install scikit-learn==0.24.0
然後就不報use warning了,但是還有Process finished with exit code 245。
/home/disk1/core/model.py:38: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify ‘dtype=object’ when creating the ndarray
Process finished with exit code 245
可見的不推薦使用的警告:不推薦使用不規則(ragged)嵌套(nested)序列(即具有不同長度或形狀的列表或列表元組、元組或數據數組)創建數據數組。如果要執行此操作,則必須在創建數據陣列時指定“dtype=object”。
在使用不同長度或形狀的序列創建數組,執行numpy.array(sequence)時,要對數據轉為object格式,即改為:
numpy_s = numpy.array(sequence, dtype=object)
更改後,不再有warning。
但是245的代碼退出還沒解決。
最後245退出的問題解決方法:
在py文件中加入下面兩句:
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
STATUS 245: the specified policy is not of the correct client type
還是沒解決,只維持了兩天。
不知道是不是和內存有關系,是不是代碼有需要優化得地方,運行一段時間內存滿了所以退出?
打算用守護進程來變相解決這個問題了。
我覺得是內存洩漏的問題。因為我觀察程序每次被調用,占用的內存就會增長,然後到達4-5GB就會以245退出。
:), ellipsis (...), numpy.newaxis (None) and integer or boolean arrays are valid indices這是一個低級錯誤,原因是因為我使用了sklearn的from sklearn.preprocessing import MinMaxScaler,把數據歸一化後,他輸出的是array,不再是dataframe,所以後面我使用dataframe的一些屬性方法就會報這個錯誤了。
solution:
通過df = pd.DataFrame(df)轉一下。