1.1 Check the update range of model parameters
optimizer.zero_grad()
model_output, pooler_output = model(input_data)
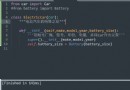
Before = list(model.parameters())[0].clone() # Get the first... Of the model before update 0 Layer weight
loss = criterion(model_output, label)
loss.backward()
# nn.utils.clip_grad_norm_(model.parameters(), max_norm=20, norm_type=2) # Gradient truncation
optimizer.step()
# Check the learning of the model
After = list(model.parameters())[0].clone() # Get the page of the updated model 0 Layer weight
predicted_label = torch.argmax(model_output, -1)
acc = accuracy_score(label.float().cpu(), predicted_label.view(-1).float().cpu())
print(loss,acc) # Print mini-batch Loss value and accuracy of
print(' The first of the model 0 Layer update amplitude :',torch.sum(After-Before))
If : The update range of the model is very small , Its absolute value <0.01, It is likely that the gradient disappeared ; If the absolute value >1000, It's probably a gradient explosion ;
The specific threshold needs to be adjusted by itself , It just provides an idea
1.2 solve
(1) Gradient explosion
Common causes of gradient explosion : Used Deep networks 、 Parameter initialization is too large , Solution :
1) Replace optimizer
2) Lower learning rate
3) Gradient truncation
4) Using regularization
(2) The gradient disappears
The disappearance of the gradient is likely to be : Deep networks 、 Used sigmoid Activation function , Solution :
1) Use Batch Norm Batch of standardized
BN Normalize the output of each layer in the network to a normal distribution , And use zoom and translation parameters to adjust the data distribution after standardization , The original output concentrated in the gradient saturation region can be pulled to the linear change region , Increase the gradient value , Ease the problem of gradient disappearance , And accelerate the learning speed of the network .
2) choose Relu() Activation function
3) Using residual networks ResNet
Use ResNet It can easily build hundreds of floors 、 Thousands of layers of networks , Instead of worrying about the disappearance of gradients .