Six、Utiliser BeautifulSoup Analyse HTML Code de la page
1,Introduction générale
En termes simples, Beautiful Soup C'est Python Un HTML Ou XML Bibliothèque de résolution pour,Il est facile d'extraire des données d'une page web.
- Beautiful Soup Offre un peu de simplicité、Python Pour gérer la navigation、Recherche、Modifier des fonctions telles que l'arbre d'analyse.C'est une boîte à outils,Fournir à l'utilisateur les données à saisir en analysant le document,Parce que c'est simple.,Il n'est donc pas nécessaire de beaucoup de code pour écrire une application complète.
- Beautiful Soup Convertir automatiquement les documents d'entrée en Unicode Codage,Convertir le document de sortie en UTF-8 Codage.Tu n'as pas besoin de penser au codage.,Sauf si le document ne spécifie pas de méthode d'encodage,À ce stade, il suffit d'expliquer le codage original.
- Beautiful Soup Est devenu et lxml、html6lib Tout aussi bien. Python Interpréteur,Offrir aux utilisateurs la flexibilité de différentes stratégies d'analyse ou une vitesse élevée.
2,Utilisation de base
(1)Trouver des objets par étiquette
soup.a Et soup.find('a') #Trouver le premieraÉtiquettes,La valeur de retour est untagObjet.
soup.find('a', {'class':'title abc'}) #Trouver le premiercssDeclassPourtitle abcDeaÉtiquettes,La valeur de retour est untagObjet.
soup.find_all('a') #Trouver toutaÉtiquettes,Retour à untag Collection d'objets list.
soup.find_all('a', class='name') #TrouverclassCette propriété estnameDeaÉtiquettes,Retour à untag Collection d'objets list.
soup.find_all('a', limit=3) # Trouver 3 aÉtiquettes,Retour à untag Collection d'objets list.
soup.find_all(text="") #Trouvertext Résultats pour une chaîne ,Retour à untag Collection d'objets list.
soup.find_all(["p", "span"]) # TrouverpNoeuds etspanNoeud
soup.find_all(class_=re.compile("^p")) # Expression régulière(TrouverclassLa valeur de la propriété estpNoeud au début)
#AutresfindMéthodes
find_parent #Trouver le noeud parent
find_parents # Recherche récursive du noeud parent
find_next_siblings # Trouver le noeud frère suivant
find_next_sibling # Trouvez le premier noeud frère qui répond aux critères suivants
find_all_next # Trouver tous les noeuds suivants
find_next # Trouvez le premier noeud qui répond aux critères suivants
find_all_previous # Trouver tous les noeuds précédents qui répondent aux critères
find_previous # Trouver le premier noeud qui répond aux critères avant (2)Adoption CSS Objet de recherche du sélecteur
# select Avec select_one
soup.select("a") #Trouver toutaÉtiquettes,Retour à untag Collection d'objets list
soup.select_one("a") #Trouver le premieraÉtiquettes,Retour à untagObjet
# AdoptiontagSélectionner
soup.select("title") # SélectionnertitleNoeud
soup.select("body a") # SélectionnerbodyTout sous le noeudaNoeud
soup.select("html head title") # SélectionnerhtmlSous le noeudheadSous le noeudtitleNoeud
# id Et sélecteur de classe
soup.select(".article") # Sélectionner le nom de la classearticleNode of
soup.select("a#id1") # SélectionneridPourid1DeaNoeud
soup.select("#id1") # SélectionneridPourid1Node of
soup.select("#id1,#id2") # SélectionneridPourid1、id2Node of
# Sélecteur de propriétés
soup.select('a[href]') # Les choix sonthrefPropriétéaNoeud
soup.select('a[href="http://hangge.com/get"]') # SélectionnerhrefLa propriété esthttp://hangge.com/getDeaNoeud
soup.select('a[href^="http://hangge.com/"]') # SélectionnerhrefParhttp://hangge.com/Au débutaNoeud
soup.select('a[href$="png"]') # SélectionnerhrefParpngFinaNoeud
soup.select('a[href*="china"]') # SélectionnerhrefLa propriété contientchinaDeaNoeud
soup.select("a[href~=china]") # SélectionnerhrefLa propriété contientchinaDeaNoeud
#Autres sélecteurs
soup.select("div > p") # Le noeud parent estdivNodepNoeud
soup.select("div + p") # Avant le noeud divNodepNoeud
soup.select("p~ul") # pAprès le noeudulNoeud(pEtul A un parent commun )
soup.select("p:nth-of-type(3)") # Dans le noeud parent 3- Oui.pNoeud (3)Obtenir le contenu de l'objet
soup.a['class'] Et soup.a.get['class'] #Obtenir le premieraÉtiquetteclassValeur de l'attribut.
soup.a.name #Obtenir le premieraLe nom de l'étiquette.
soup.a.string #Obtenir le premiera Chaîne non - attribut dans l'étiquette , Si c'est une chaîne non - attribut à l'intérieur , Doit passer par soup.a.get_text()Accès
soup.a.strings #Accèsa Liste de toutes les chaînes qui ne sont pas des attributs dans l'étiquette .
soup.a.stripped_strings #Accèsa Liste de toutes les chaînes qui ne sont pas des attributs dans l'étiquette , Supprimer les blancs et les lignes vides .
soup.a.text Et soup.a.get_text() #Obtenir le premiera Chaîne non - attribut dans l'étiquette .Par exemple∶ abc_()Ce que vous obtenezabc.
soup.a.attrs #Obtenir le premieraToutes les propriétés de l'étiquette.
3,Utiliser l'échantillon
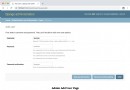
(1) Voici l'exemple que nous allons prendre csdn Titre Hotspot entry on Homepage :
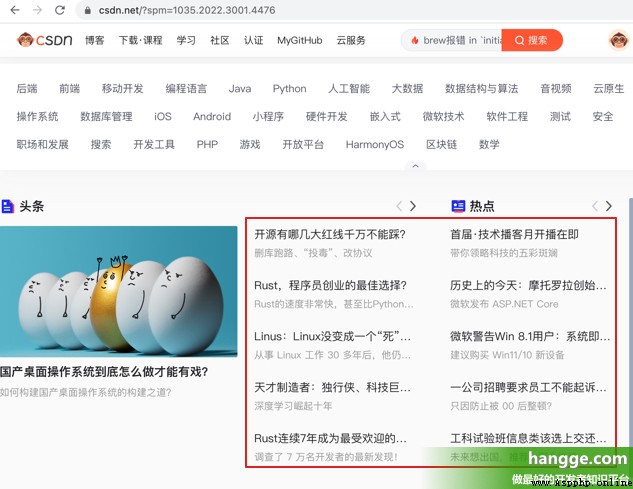
(2) Voir le code source de la page pour trouver , Chaque objectif est class Pour headswiper-item De div Deuxième partie 1 - Oui. a Dans l'étiquette:
(3)Voici le code spécifique:
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.csdn.net")
soup = BeautifulSoup(response.text, "lxml")
items = soup.select(".headswiper-item")
for item in items:
print(item.a.text)
Annexe:Web crawler
1,Travaux préparatoires
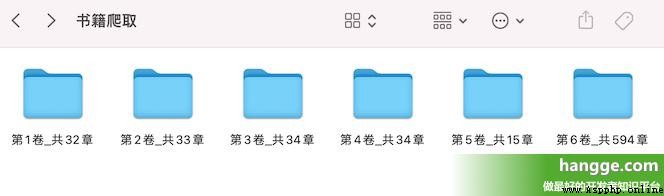
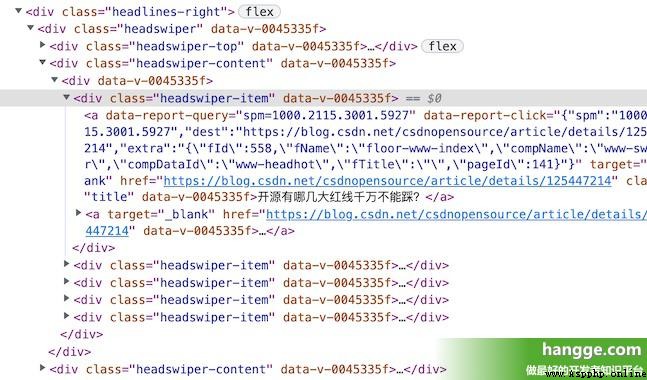
(1) Ici, nous avons saisi et téléchargé le roman de départ en ligne comme démo . Trouvez d'abord un roman à télécharger , Notez le roman. bookId.
(2)Et voilà. F12 Ouvrir la console du Navigateur,Cliquez sur Network,Cliquez à nouveau. XHR, Rafraîchir la page pour obtenir la page csrfToken( bookId Il y en a aussi.):
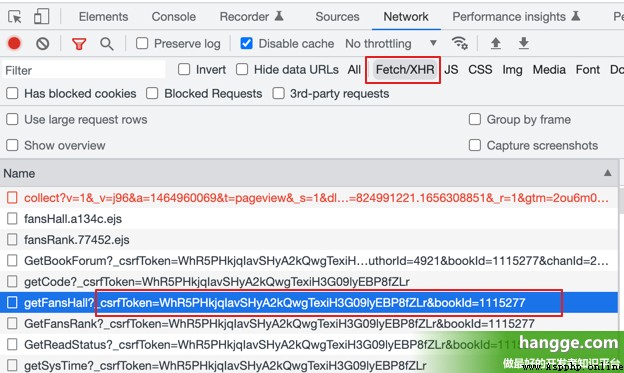
(3) Nous accédons à l'interface suivante qui a été transmise à csrfToken Et bookId Vous pouvez obtenir le catalogue complet du roman .Parmi eux vs Pour toutes les collections de volumes , Sous chaque volume cs Collection de tous les chapitres du volume .
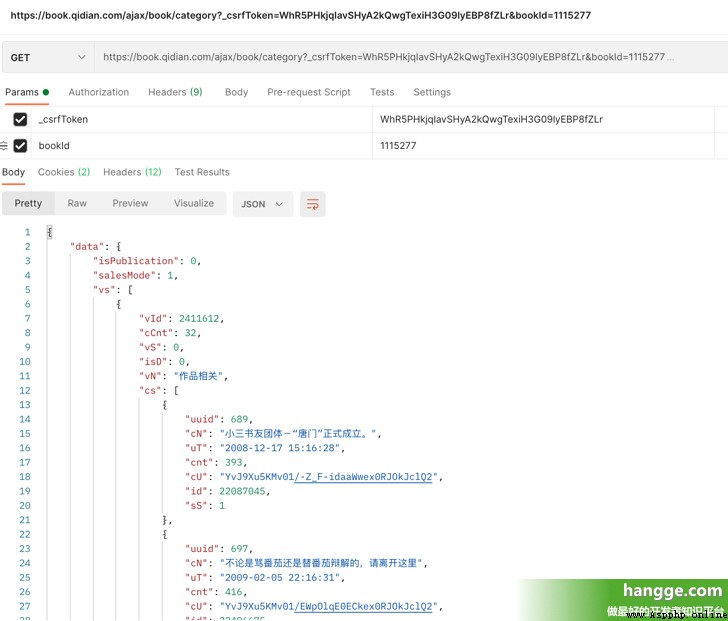
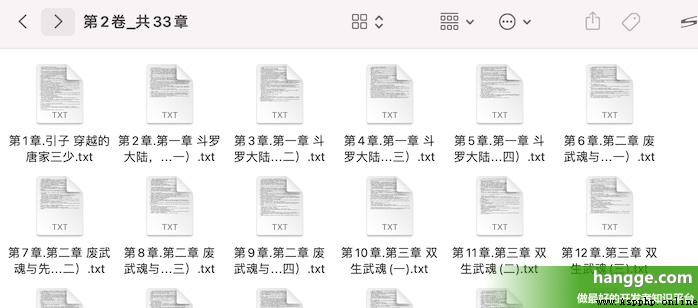
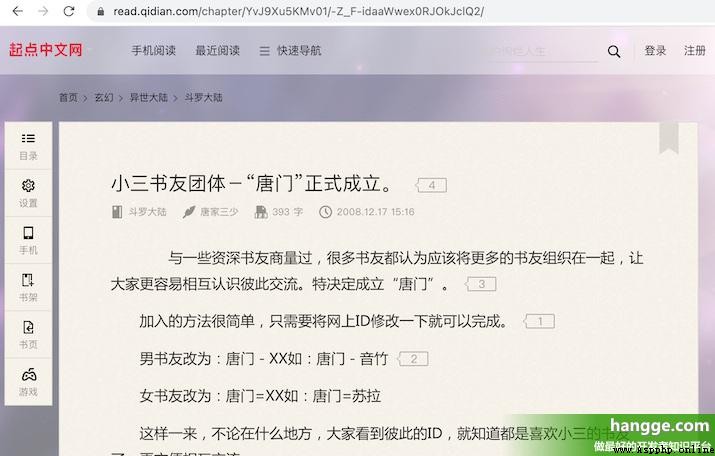
(4) De chaque chapitre cU C'est l'adresse de la page du chapitre , .Nous pouvons accéder à cette page en joignant un préfixe fixe , Ensuite, il suffit d'analyser le contenu de la page , Et sauvegardez - le localement .
2,Exemple de code
(1) Voici le code complet du crawler , Lors de l'utilisation, il suffit de modifier le cas bookId、 csrfToken Et télécharger l'adresse d'enregistrement du fichier :
import requests
import re
from bs4 import BeautifulSoup
from requests.exceptions import *
import random
import json
import time
import os
import sys
# Retour aléatoirelistUn desUser AgentSetPoint, Prévention des interdictions
def get_user_agent():
list = ['Mozilla/5.0(Windows NT 10.0;Win64; x64)AppleWebKit/537.36(KHTML,like Gecko) Chrome/87.0.4280.66 Safari/537.36',
'Mozilla/5.0(Windows NT 6.3;Win64;x64)AppleWebKit/537.36 (KHTML,like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.2; Win64;x64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.1;Win64;x64AppleWebKit/537.36 (KHTML,like GeckoChrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.3;WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0(Windows NT 6.2; WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0(Windows NT6.1; WOW64)AppleWebKit/537.36(KHTML, like Gecko)Chrome/41.0.2225.0 Safari/537.36']
return list[random.randint(0, len(list)-1)]
# Retoururl Chapitre du livre sur le site Web (Page)id, Chaque chapitre de volume (Page) Chapitre correspondant (Chap)Nombre, Et l'adresse de la page du chapitre
def getPageAndChapUrl(bookId, csrfToken):
url ='https://book.qidian.com/ajax/book/category?_csrfToken=' + csrfToken + '&bookId=' + bookId
headers ={
'User-Agent': get_user_agent(),
'Referer':'https://book.qidian.com/info/' + bookId
}
try:
response = requests.get(url=url, params=headers)
if response.status_code == 200:
json_str = response.text
list = json.loads(json_str)['data']['vs']
volume ={
'VolumeId_List':[],
'VolumeNum_List':[],
'ChapterUrl_List':[]
}
for i in range(len(list)):
json_str = json.dumps(list[i]).replace(" ","")
volume_id =re.search('.*?"vId":(.*?),',json_str,re.S).group(1)
volume_num=re.search('.*?"cCnt":(.*?),',json_str,re.S).group(1)
volume['VolumeId_List'].append(volume_id)
volume['VolumeNum_List'].append(volume_num)
volume['ChapterUrl_List'].append([])
for j in range(len(list[i]['cs'])):
volume['ChapterUrl_List'][i].append(list[i]['cs'][j]['cU'])
print(volume)
return volume
else:
print('No response')
return None
except Exception as e:
print(" Erreur dans la page de demande !", e)
return None
# Trouver la page à ramper à travers l'adresse de page de chaque chapitre , Et retourner à la page htmlInformation.
def getPage(savePath, volume, bookId):
for i in range(len(volume['VolumeId_List'])):
path = savePath + '/No'+ str(i + 1) + 'Vol._Total'+ volume['VolumeNum_List'][i] +'Chapitre'
mkdir(path)
print('--- No' + str(i+1) +' Le volume a commencé à ramper ---')
for j in range(int(volume['VolumeNum_List'][i])):
url ='https://read.qidian.com/chapter/' + volume['ChapterUrl_List'][i][j]
print('Je grimpe pour' + str(i+1) + 'Vol.' + str(j+1) + ' Chemin du chapitre :'+url)
headers ={
'User-Agent': get_user_agent(),
'Referer':'https://book.qidian.com/info/' + bookId
}
try:
response = requests.get(url=url, params=headers)
if(response.status_code==200):
getChapAndSavetxt(response.text, url, path, j)
else:
print ('No response')
return None
except ReadTimeout:
print("ReadTimeout!")
return None
except RequestException:
print(" Erreur dans la page de demande !")
return None
time.sleep(5)
print('--- No' + str(i+1) +' Fin de la bobine ---')
# Analyse de la page de contenu du roman , Chaque chapitre (Chap)Écrire du contenutxtDocumentation, Et stocké dans le chapitre de volume approprié (Page)Sous la table des matières.
# Parmi eux,html Pour la page de contenu du roman ;urlChemin d'accès;path Stocker le chemin pour le chapitre volume ;chapNum Pour chaque volume Page Chapitre correspondant ChapNombre
def getChapAndSavetxt(html, url, path, chapNum):
if html == None:
print('Le chemin d'accès est'+url+' La page pour est vide ')
return
soup = BeautifulSoup(html,'lxml')
ChapName = soup.find('h3',attrs={'class':'j_chapterName'}).span.string
ChapName = re.sub('[\/:*?"<>]','',ChapName)
filename = path+'//'+'No'+ str(chapNum+1) +'Chapitre.' + ChapName + '.txt'
readContent = soup.find('div', attrs={'class':'read-content j_readContent'}).find_all('p')
paragraph = []
for item in readContent:
paragraph.append(re.search('.*?<p>(.*?)</p>',str(item),re.S).group(1))
save2file(filename, '\n'.join(paragraph))
# Écrire du contenu dans un fichier.
# Parmi eux,filename Chemin de fichier stocké pour ,content Pour écrire
def save2file(filename, content):
with open(r''+filename, 'w', encoding='utf-8') as f:
f.write(content)
# Créer un dossier de catalogue de chapitre de volume .
# Parmi eux,path Chemin à créer pour
def mkdir(path):
folder = os.path.exists(path)
if(not folder):
os.makedirs(path)
else:
print('Chemin“' + path + '”Existe déjà')
# Fonction principale
def main(savePath, bookId, csrfToken):
volume = getPageAndChapUrl(bookId, csrfToken)
if (volume != None):
getPage(savePath, volume, bookId)
else:
print(' Impossible d'accéder au roman !')
print(" Le roman est terminé. !")
# Appeler la fonction principale
savePath = '/Volumes/BOOTCAMP/ Accès aux livres ' #Chemin d'enregistrement du fichier
bookId = '1115277' #Un romanid
csrfToken = 'WhR5PHkjqIavSHyA2kQwgTexiH3G09lyEBP8fZLr' #csrfToken
main(savePath, bookId, csrfToken)
(2) Les informations de la console après l'exécution du programme sont les suivantes , Vous pouvez voir que vous obtiendrez d'abord les informations du catalogue du roman et les analyserez , Puis commencez à télécharger les pages des chapitres à tour de rôle .


(3) Voir le Répertoire de téléchargement , Vous pouvez voir que le contenu de chaque chapitre est txt Le format du document est sauvegardé sous chaque dossier de volume .