6、 ... and 、 Use BeautifulSoup analysis HTML Page code
1, Basic introduction
Simply speaking , Beautiful Soup Namely Python One of the HTML or XML The parsing library of , It is very convenient to extract data from web pages .
- Beautiful Soup Provide some simple 、Python Function to handle navigation 、 Search for 、 Modify analysis tree and other functions . It's a toolbox , Provide users with data to be grabbed by parsing documents , Because of the simple , So it doesn't take much code to write a complete application .
- Beautiful Soup Automatically convert the input document to Unicode code , The output document is converted to UTF-8 code . You don't need to think about coding , Unless the document does not specify a coding method , At this point, you just need to explain the original coding method .
- Beautiful Soup Has become and lxml、html6lib As good as Python Interpreter , Provide users with different parsing strategies or strong speed flexibly .
2, Basic usage
(1) Find objects through tags
soup.a and soup.find('a') # find first a label , The return value is a tag object .
soup.find('a', {'class':'title abc'}) # find first css Of class by title abc Of a label , The return value is a tag object .
soup.find_all('a') # Find all a label , Return to one tag Object collection list.
soup.find_all('a', class='name') # lookup class This property is name Of a label , Return to one tag Object collection list.
soup.find_all('a', limit=3) # Find three a label , Return to one tag Object collection list.
soup.find_all(text="") # lookup text Is the result of a string , Return to one tag Object collection list.
soup.find_all(["p", "span"]) # lookup p Nodes and span node
soup.find_all(class_=re.compile("^p")) # Regular expressions ( lookup class The attribute value is p The starting node )
# other find Method
find_parent # Find the parent node
find_parents # Recursively find the parent node
find_next_siblings # Find the following sibling nodes
find_next_sibling # Find the first sibling node that meets the condition later
find_all_next # Find all nodes after
find_next # Find the next node that meets the condition
find_all_previous # Find all the previous nodes that meet the conditions
find_previous # Find the first node that meets the condition (2) adopt CSS Selector finds objects
# select And select_one
soup.select("a") # Find all a label , Return to one tag Object collection list
soup.select_one("a") # find first a label , Return to one tag object
# adopt tag choice
soup.select("title") # choice title node
soup.select("body a") # choice body All under node a node
soup.select("html head title") # choice html Node under head Node under title node
# id And class selector
soup.select(".article") # Choose a class name of article The node of
soup.select("a#id1") # choice id by id1 Of a node
soup.select("#id1") # choice id by id1 The node of
soup.select("#id1,#id2") # choice id by id1、id2 The node of
# Attribute selector
soup.select('a[href]') # Choose to have href Attribute a node
soup.select('a[href="http://hangge.com/get"]') # choice href The attribute is http://hangge.com/get Of a node
soup.select('a[href^="http://hangge.com/"]') # choice href With http://hangge.com/ At the beginning a node
soup.select('a[href$="png"]') # choice href With png At the end of the a node
soup.select('a[href*="china"]') # choice href Attribute contains china Of a node
soup.select("a[href~=china]") # choice href Attribute contains china Of a node
# Other selectors
soup.select("div > p") # Parent node is div Node p node
soup.select("div + p") # Before the node there is div Node p node
soup.select("p~ul") # p After the node ul node (p and ul Have a common parent )
soup.select("p:nth-of-type(3)") # The... In the parent node 3 individual p node (3) Get object content
soup.a['class'] and soup.a.get['class'] # Get the first one a Labeled class Property value .
soup.a.name # Get the first one a Name of label .
soup.a.string # Get the first one a A string that is not an attribute in the tag , If it is a non attribute string inside , Must be through soup.a.get_text() obtain
soup.a.strings # obtain a List of all strings in the tag that are not attributes .
soup.a.stripped_strings # obtain a List of all strings in the tag that are not attributes , Remove blanks and blank lines .
soup.a.text and soup.a.get_text() # Get the first one a A string that is not an attribute in the tag . for example ∶ abc_() What you get is abc.
soup.a.attrs # Get the first one a All attributes of the tag .
3, Use samples
(1) In the following example, we want to capture csdn Headlines and hot items on the home page :
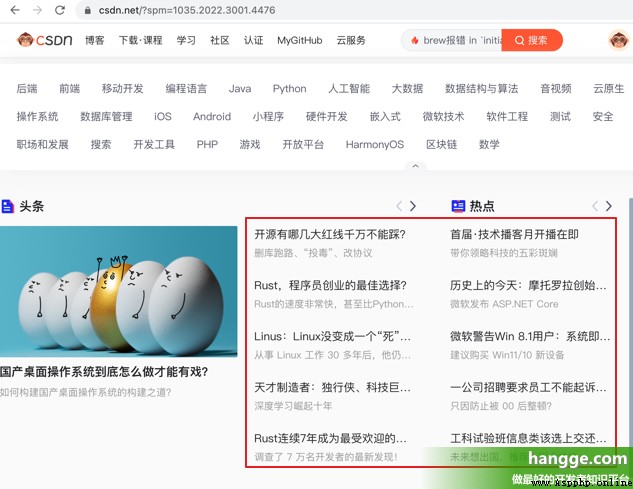
(2) Looking at the page source code, you can find , Each goal question is class by headswiper-item Of div The next 1 individual a In the label :
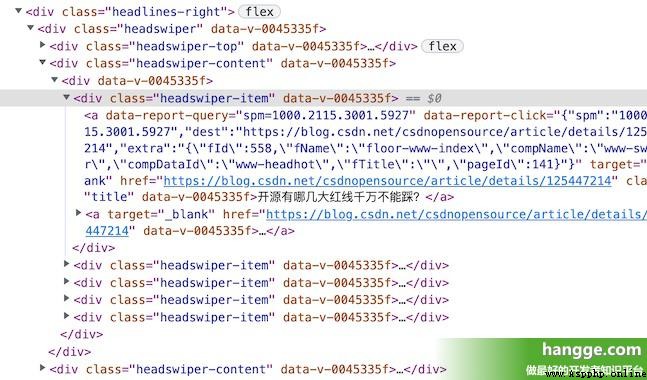
(3) Here is the specific code :
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.csdn.net")
soup = BeautifulSoup(response.text, "lxml")
items = soup.select(".headswiper-item")
for item in items:
print(item.a.text)
attach : Web crawler
1, preparation
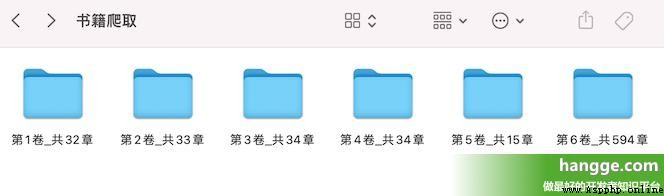
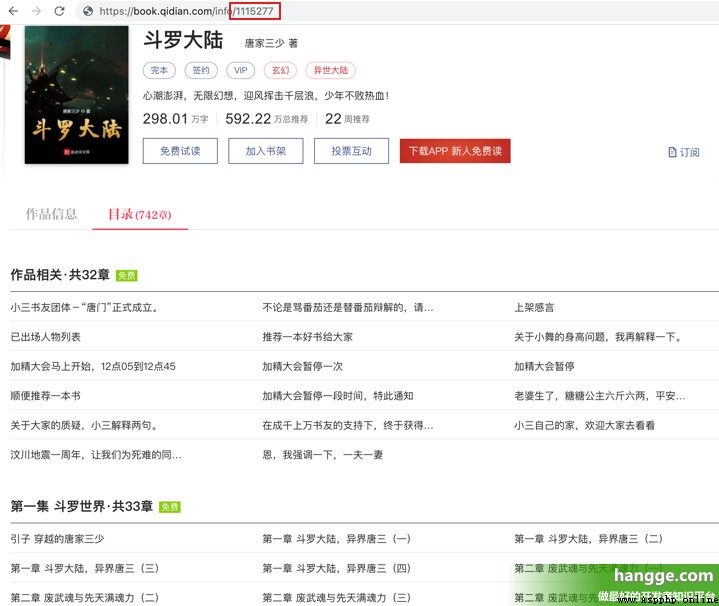
(1) Here we have captured and downloaded the novel on the starting point novel online as a demonstration . First, find a novel to download , Write down the novel bookId.
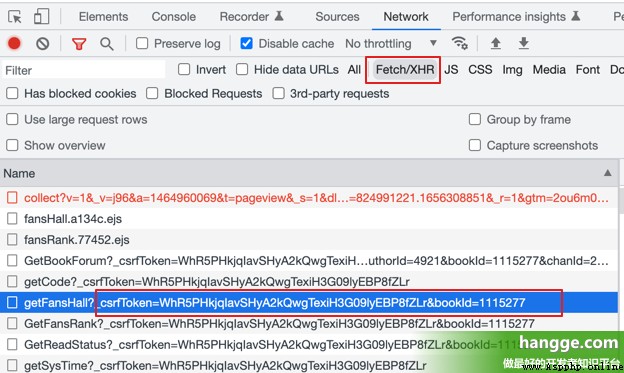
(2) next F12 Open the browser console , Click on Network, Click again XHR, Refresh the page to get the csrfToken( bookId Also have ):
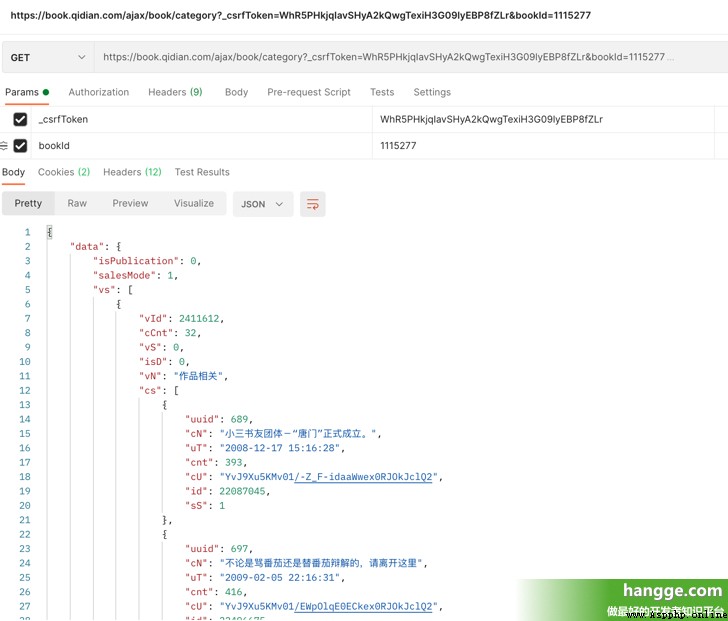
(3) We access the following interface to pass in the previously obtained csrfToken and bookId You can get the catalogue of the whole novel . among vs Set for all volumes , Under each roll cs Set all chapters for this volume .
(4) Of each chapter cU It is the address of the chapter page , We can access this page by splicing the fixed prefix , Next, just parse the content of the page , And save it locally .
2, Sample code
(1) Here is the complete code of the crawler , When using, you only need to modify it according to the situation bookId、 csrfToken And the download file storage address :
import requests
import re
from bs4 import BeautifulSoup
from requests.exceptions import *
import random
import json
import time
import os
import sys
# Random return list One of the User Agent Set the value , Prevent being banned
def get_user_agent():
list = ['Mozilla/5.0(Windows NT 10.0;Win64; x64)AppleWebKit/537.36(KHTML,like Gecko) Chrome/87.0.4280.66 Safari/537.36',
'Mozilla/5.0(Windows NT 6.3;Win64;x64)AppleWebKit/537.36 (KHTML,like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.2; Win64;x64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.1;Win64;x64AppleWebKit/537.36 (KHTML,like GeckoChrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.3;WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0(Windows NT 6.2; WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0(Windows NT6.1; WOW64)AppleWebKit/537.36(KHTML, like Gecko)Chrome/41.0.2225.0 Safari/537.36']
return list[random.randint(0, len(list)-1)]
# return url The book chapter on the website (Page)id, Each chapter (Page) Corresponding chapters (Chap) number , And chapter page address
def getPageAndChapUrl(bookId, csrfToken):
url ='https://book.qidian.com/ajax/book/category?_csrfToken=' + csrfToken + '&bookId=' + bookId
headers ={
'User-Agent': get_user_agent(),
'Referer':'https://book.qidian.com/info/' + bookId
}
try:
response = requests.get(url=url, params=headers)
if response.status_code == 200:
json_str = response.text
list = json.loads(json_str)['data']['vs']
volume ={
'VolumeId_List':[],
'VolumeNum_List':[],
'ChapterUrl_List':[]
}
for i in range(len(list)):
json_str = json.dumps(list[i]).replace(" ","")
volume_id =re.search('.*?"vId":(.*?),',json_str,re.S).group(1)
volume_num=re.search('.*?"cCnt":(.*?),',json_str,re.S).group(1)
volume['VolumeId_List'].append(volume_id)
volume['VolumeNum_List'].append(volume_num)
volume['ChapterUrl_List'].append([])
for j in range(len(list[i]['cs'])):
volume['ChapterUrl_List'][i].append(list[i]['cs'][j]['cU'])
print(volume)
return volume
else:
print('No response')
return None
except Exception as e:
print(" Error requesting page !", e)
return None
# Find the page to crawl through the page address of each chapter , And return to the page html Information .
def getPage(savePath, volume, bookId):
for i in range(len(volume['VolumeId_List'])):
path = savePath + '/ The first '+ str(i + 1) + ' volume _ common '+ volume['VolumeNum_List'][i] +' Chapter '
mkdir(path)
print('--- The first ' + str(i+1) +' The roll has started crawling ---')
for j in range(int(volume['VolumeNum_List'][i])):
url ='https://read.qidian.com/chapter/' + volume['ChapterUrl_List'][i][j]
print(' Climbing to the top ' + str(i+1) + ' Volume No ' + str(j+1) + ' Zhang path :'+url)
headers ={
'User-Agent': get_user_agent(),
'Referer':'https://book.qidian.com/info/' + bookId
}
try:
response = requests.get(url=url, params=headers)
if(response.status_code==200):
getChapAndSavetxt(response.text, url, path, j)
else:
print ('No response')
return None
except ReadTimeout:
print("ReadTimeout!")
return None
except RequestException:
print(" Error requesting page !")
return None
time.sleep(5)
print('--- The first ' + str(i+1) +' Roll crawling is over ---')
# Analyze the novel content page , Put each chapter (Chap) Content write txt file , And stored in the corresponding volume chapter (Page) Under the table of contents .
# among ,html For the novel content page ;url Is the access path ;path Storage path for volume chapter ;chapNum For each volume Page Corresponding chapters Chap number
def getChapAndSavetxt(html, url, path, chapNum):
if html == None:
print(' The access path is '+url+' The page of is empty ')
return
soup = BeautifulSoup(html,'lxml')
ChapName = soup.find('h3',attrs={'class':'j_chapterName'}).span.string
ChapName = re.sub('[\/:*?"<>]','',ChapName)
filename = path+'//'+' The first '+ str(chapNum+1) +' Chapter .' + ChapName + '.txt'
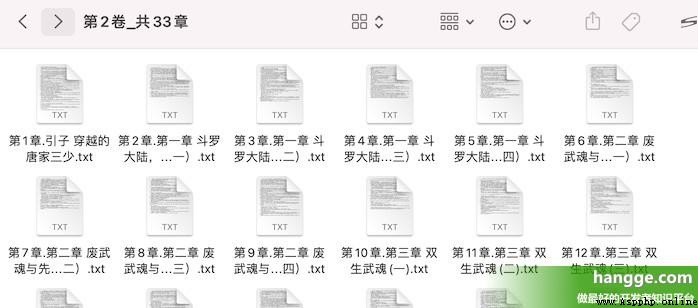
readContent = soup.find('div', attrs={'class':'read-content j_readContent'}).find_all('p')
paragraph = []
for item in readContent:
paragraph.append(re.search('.*?<p>(.*?)</p>',str(item),re.S).group(1))
save2file(filename, '\n'.join(paragraph))
# Write content to file .
# among ,filename For the stored file path ,content For what to write
def save2file(filename, content):
with open(r''+filename, 'w', encoding='utf-8') as f:
f.write(content)
# Create a chapter directory folder .
# among ,path For the path to be created
def mkdir(path):
folder = os.path.exists(path)
if(not folder):
os.makedirs(path)
else:
print(' route “' + path + '” Already exists ')
# The main function
def main(savePath, bookId, csrfToken):
volume = getPageAndChapUrl(bookId, csrfToken)
if (volume != None):
getPage(savePath, volume, bookId)
else:
print(' Unable to crawl the novel !')
print(" Finished crawling the novel !")
# Call the main function
savePath = '/Volumes/BOOTCAMP/ Book crawling ' # File save path
bookId = '1115277' # A novel id
csrfToken = 'WhR5PHkjqIavSHyA2kQwgTexiH3G09lyEBP8fZLr' #csrfToken
main(savePath, bookId, csrfToken)
(2) After the program runs, the console information is as follows , You can see that first, you will get the catalog information of the novel and parse it , Then start downloading each chapter page in turn .


(3) Check out the download directory , You can see that the contents of each chapter are in txt The form of the document is saved under each volume folder .