四、定制請求頭
1,基本用法
(1)如果我們想為請求添加 HTTP 請求頭( Request Header),只要簡單地傳遞一個 dict 給 headers 參數就可以了。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Token': '123456'
}
r = requests.get('http://httpbin.org/get?name=hangge', headers=headers)
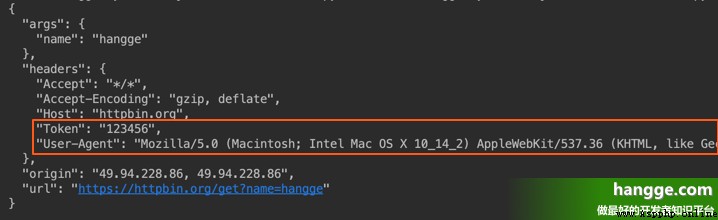
print(r.text) (2)運行程序可以看到請求頭已經添加成功了:
2,注意事項
(1)定制 header 的優先級低於某些特定的信息源,例如:
- 如果在 .netrc 中設置了用戶認證信息,使用 headers= 設置的授權就不會生效。而如果設置了 auth= 參數,``.netrc`` 的設置就無效了。
- 如果被重定向到別的主機,授權 header 就會被刪除。
- 代理授權 header 會被 URL 中提供的代理身份覆蓋掉。
- 在我們能判斷內容長度的情況下,header 的 Content-Length 會被改寫。
(2)簡單來說, Requests 不會基於定制 header 的具體情況改變自己的行為。只不過在最後的請求中,所有的 header 信息都會被傳遞進去。
五、超時設置
1,timeout 參數
(1)默認情況下, requests 是沒有超時時長限制的,如果請求沒有響應,我們的程序就會一直等待下去。 (2)我們可以使用 timeout 參數設置個時長(單位:秒),告訴 requests 在經過多長時間之後停止等待響應。 注意:timeout 僅對連接過程有效,與響應體的下載無關。
timeout 並不是整個下載響應的時間限制,而是如果服務器在 timeout 秒內沒有應答,將會引發一個異常(更精確地說,是在 timeout 秒內沒有從基礎套接字上接收到任何字節的數據時)
2,使用樣例
(1)下面將超時時間設為 0.001 秒(這樣肯定超時)
import requests
response = requests.get('http://httpbin.org/get', timeout=0.001)
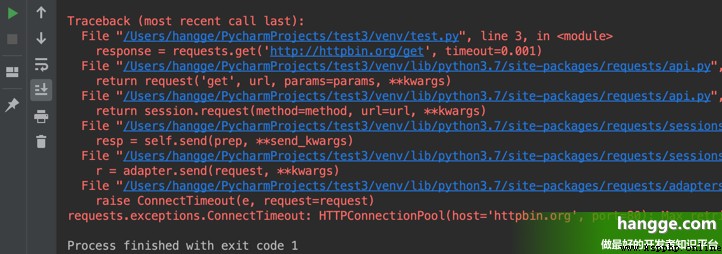
print(response.text) (2)運行是可以發現拋出了個超時異常:
六、Cookie
1,查看 cookie 信息
(1)我們這裡請求百度翻譯的首頁,可以看到百度已經生成了一個名為 BAIDUID 的 cookie,放在 RequestsCookieJar[] 裡了。由於我們本地沒有保存這個 cookie 並在下一次請求時進行攜帶,所有下面代碼每次執行百度都會生成一個新的 cookie:
import requests
response = requests.get("https://fanyi.baidu.com")
print(type(response.cookies), response.cookies)
print("-------------------")
for key, value in response.cookies.items():
print(key + "=" + value)
(2) requests 庫還提供了個方法將 RequestsCookieJar 轉換成 dict 字典:
import requests
response = requests.get("https://fanyi.baidu.com")
print(type(response.cookies), response.cookies)
print("-------------------")
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
2,自定義 cookie
(1)如果要在發送請求時添加某些 cookie, 最簡單的方法就是設置 cookies 參數。下面我們通過字典方式構建一個 cookie,再次請求百度翻譯頁面,可以看到返回結果中不會有新的 cookie,說明百度認為我們不是一個新的客戶端請求:
import requests
cookies = {'BAIDUID': 'DEBE4AEE74931831BD0406630BEC3B5C:FG=1'}
response = requests.get("https://fanyi.baidu.com",cookies=cookies)
print(type(response.cookies), response.cookies)
(2)構建 cookie 更專業的方式是先實例化一個 RequestCookieJar 的類,然後把值 set 進去。下面代碼效果同上面是一樣的: RequestsCookieJar 的行為和字典類似,但接口更為完整,適合跨域名跨路徑使用
import requests
cookie_jar = requests.cookies.RequestsCookieJar()
cookie_jar.set('BAIDUID', 'DEBE4AEE74931831BD0406630BEC3B5C:FG=1', domain='fanyi.baidu.com')
response = requests.get("https://fanyi.baidu.com",cookies=cookies)
print(type(response.cookies), response.cookies) 七、設置代理
如果需要讓某些請求使用代理,可以使用 requests 的 proxies 參數進行設置:
proxies = {
"http": "http://192.168.43.1:58300",
"https": "https://192.168.43.1:58300"
}
response = requests.get("http://httpbin.org/get", proxies=proxies)
print(response.text)