Next, a difficult point in the index , Handle pandas The integer index of is often difficult for novices , Because it is related to python The built-in list tuples of are indexed differently . For example, the following code :
ser = pd.Series(np.arange(3.))
ser
ser[-1]
Is there no problem ?? No , It's wrong here !!!
here ,pandas You can barely index integers , But it will lead to small bug. We have 0,1,2 The index of , But introducing what users want ( Index based on label or location ) It is difficult to .
in addition , For non integer indexes , No ambiguity :
In [145]: ser2 = pd.Series(np.arange(3.), index=['a', 'b', 'c'])
In [146]: ser2[-1]
Out[146]: 2.0
For the sake of unification , If the axis index contains an integer , Data selection always uses labels . In order to be more accurate , Please use loc( label ) or iloc( Integers ):
In [147]: ser[:1]
Out[147]:
0 0.0
dtype: float64
In [148]: ser.loc[:1]
Out[148]:
0 0.0
1 1.0
dtype: float64
In [149]: ser.iloc[:1]
Out[149]:
0 0.0
dtype: float64
pandas One of the most important functions is , It can perform arithmetic operations on objects with different indexes . When you add objects , If there is an index that does not correspond to , The result is the union of the indexes . For students who have used databases , This is similar to the automatic external connection in the database . Here is an example :
In [150]: s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
In [151]: s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1],
.....: index=['a', 'c', 'e', 'f', 'g'])
In [152]: s1
Out[152]:
a 7.3
c -2.5
d 3.4
e 1.5
dtype: float64
In [153]: s2
Out[153]:
a -2.1
c 3.6
e -1.5
f 4.0
g 3.1
dtype: float64
In [154]: s1 + s2
Out[154]:
a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
Automatic data alignment introduces... At non overlapping indexes NA value . Missing values are propagated during arithmetic operations .
about DataFrame, Alignment occurs on both rows and columns :
In [155]: df1 = pd.DataFrame(np.arange(9.).reshape((3, 3)), columns=list('bcd'),
.....: index=['Ohio', 'Texas', 'Colorado'])
In [156]: df2 = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [157]: df1
Out[157]:
b c d
Ohio 0.0 1.0 2.0
Texas 3.0 4.0 5.0
Colorado 6.0 7.0 8.0
In [158]: df2
Out[158]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [159]: df1 + df2
Out[159]:
b c d e
Colorado NaN NaN NaN NaN
Ohio 3.0 NaN 6.0 NaN
Oregon NaN NaN NaN NaN
Texas 9.0 NaN 12.0 NaN
Utah NaN NaN NaN NaN
because 'c' and 'e' The columns are not in two DataFrame In the object , Render in the result with default values . OK, the same is true .
If DataFrame Add objects , No shared column or row labels , The result will be empty :
In [160]: df1 = pd.DataFrame({'A': [1, 2]})
In [161]: df2 = pd.DataFrame({'B': [3, 4]})
In [162]: df1
Out[162]:
A
0 1
1 2
In [163]: df2
Out[163]:
B
0 3
1 4
In [164]: df1 - df2
Out[164]:
A B
0 NaN NaN
1 NaN NaN
After learning the above modules , I think you also found a problem , In these two different index object operations , I don't want it to generate NaN, I want to set up my own way to deal with different situations .pandas Of course, the following is also designed , For example, you need to fill in the value is 0 when :
In [165]: df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),
.....: columns=list('abcd'))
In [166]: df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),
.....: columns=list('abcde'))
In [167]: df2.loc[1, 'b'] = np.nan
In [168]: df1
Out[168]:
a b c d
0 0.0 1.0 2.0 3.0
1 4.0 5.0 6.0 7.0
2 8.0 9.0 10.0 11.0
In [169]: df2
Out[169]:
a b c d e
0 0.0 1.0 2.0 3.0 4.0
1 5.0 NaN 7.0 8.0 9.0
2 10.0 11.0 12.0 13.0 14.0
3 15.0 16.0 17.0 18.0 19.0
In [171]: df1.add(df2, fill_value=0)
Out[171]:
a b c d e
0 0.0 2.0 4.0 6.0 4.0
1 9.0 5.0 13.0 15.0 9.0
2 18.0 20.0 22.0 24.0 14.0
3 15.0 16.0 17.0 18.0 19.0
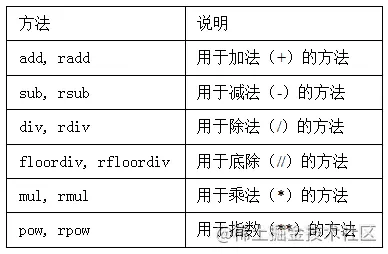
chart 5-2 Lists Series and DataFrame The arithmetic method of . They each have a copy , In letters r start , It flips the parameters . So the two statements are equivalent :
In [172]: 1 / df1
Out[172]:
a b c d
0 inf 1.000000 0.500000 0.333333
1 0.250000 0.200000 0.166667 0.142857
2 0.125000 0.111111 0.100000 0.090909
In [173]: df1.rdiv(1)
Out[173]:
a b c d
0 inf 1.000000 0.500000 0.333333
1 0.250000 0.200000 0.166667 0.142857
2 0.125000 0.111111 0.100000 0.090909
A similar , In the face of Series or DataFrame When re indexing , You can also specify a fill value :
In [174]: df1.reindex(columns=df2.columns, fill_value=0)
Out[174]:
a b c d e
0 0.0 1.0 2.0 3.0 0
1 4.0 5.0 6.0 7.0 0
2 8.0 9.0 10.0 11.0 0
The operation between the two is Numpy The operation of different dimension arrays in is similar , If you have studied my previous articles , This section will also be understood very quickly . Let's start with an example , Consider the difference between a two-dimensional array and one of its rows :
In [175]: arr = np.arange(12.).reshape((3, 4))
In [176]: arr
Out[176]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
In [177]: arr[0]
Out[177]: array([ 0., 1., 2., 3.])
In [178]: arr - arr[0]
Out[178]:
array([[ 0., 0., 0., 0.],
[ 4., 4., 4., 4.],
[ 8., 8., 8., 8.]])
When we are from arr subtract arr[0], Each row will perform this operation . This is called broadcasting (broadcasting).DataFrame and Series The same is true of operations between :
In [179]: frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
.....: columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [180]: series = frame.iloc[0]
In [181]: frame
Out[181]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [182]: series
Out[182]:
b 0.0
d 1.0
e 2.0
Name: Utah, dtype: float64
In [183]: frame - series
Out[183]:
b d e
Utah 0.0 0.0 0.0
Ohio 3.0 3.0 3.0
Texas 6.0 6.0 6.0
Oregon 9.0 9.0 9.0
If an index value is in DataFrame Column or Series Could not find... In the index of , Then the two objects involved in the operation will be re indexed to form a union :
In [184]: series2 = pd.Series(range(3), index=['b', 'e', 'f'])
In [185]: frame + series2
Out[185]:
b d e f
Utah 0.0 NaN 3.0 NaN
Ohio 3.0 NaN 6.0 NaN
Texas 6.0 NaN 9.0 NaN
Oregon 9.0 NaN 12.0 NaN
If you want to match rows and broadcast on Columns , Then the arithmetic operation method must be used . for example :
In [186]: series3 = frame['d']
In [187]: frame
Out[187]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [188]: series3
Out[188]:
Utah 1.0
Ohio 4.0
Texas 7.0
Oregon 10.0
Name: d, dtype: float64
In [189]: frame.sub(series3, axis='index')
Out[189]:
b d e
Utah -1.0 0.0 1.0
Ohio -1.0 0.0 1.0
Texas -1.0 0.0 1.0
Oregon -1.0 0.0 1.0
The axis number passed in is the axis you want to match . In this case , Our goal is to match DataFrame The row index of (axis='index' or axis=0) And broadcast .






