Catalog
Time :2022.6.23
The newcomer task of Jishi —— Hard hat Recognition brings us a better understanding of the polar games through simple competition questions 、 Project listing process .
If you are also a lover of deep learning , You might as well stop and have a look !!!
1. Development environment selection
2. To configure yolov5 Environmental Science
3. Write code
4. model training
5. Model test
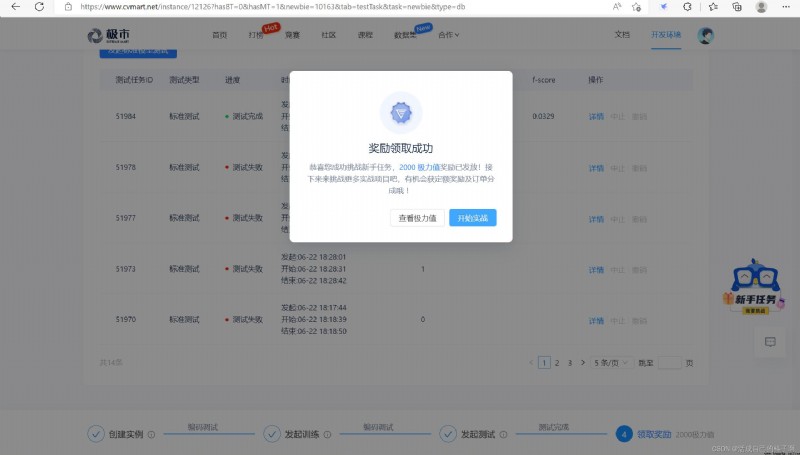
6. Get the reward
No one's success is achieved in one step , You need to spend more time than others , More energy , More love .
Jishi developer platform - Computer vision algorithm development landing platform (cvmart.net) https://www.cvmart.net/
https://www.cvmart.net/
documentation :( There's a yolov5 course )
Jishi developer platform - Computer vision algorithm development landing platform (cvmart.net)https://www.cvmart.net/document
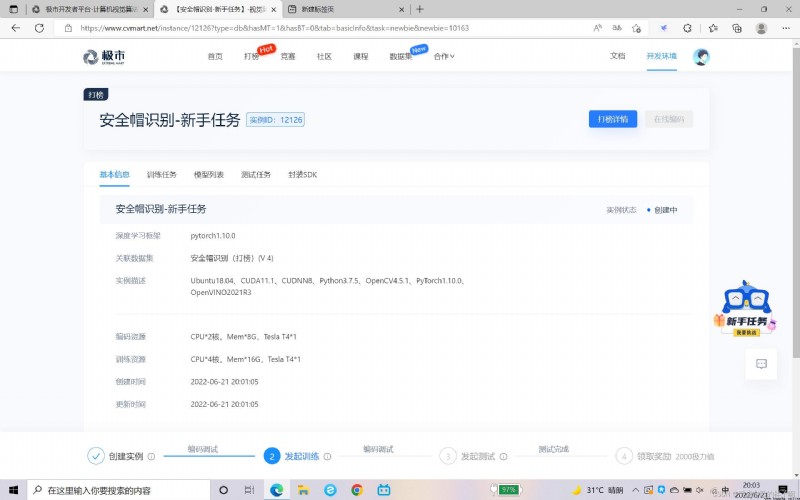
I chose pytorch1.10.0, The example is a ubantu system ,CUDA、OPENCV I have brought them with me , The graphics card is a card Tesla The graphics card , Video memory is about 15G.
Linux Basic commands :( Great God, just skip over here ~)// May be used
Back to root :cd /
Go back to the parent directory :cd ..
Entry directory :cd XXX
List all the files under the current directory :ls
Edit the file :vim XXX
-- Save and exit ::wq
-- Enter compile mode :i
-- Exit compile mode :【esc】
Clear the screen :clear
Soft connection :ln -s Target files or folders Soft connection name
Coding considerations :

So here's what I chose VSCode compiler , He is similar to ours PyCharm, The one on the left is our old friend Jupyter.
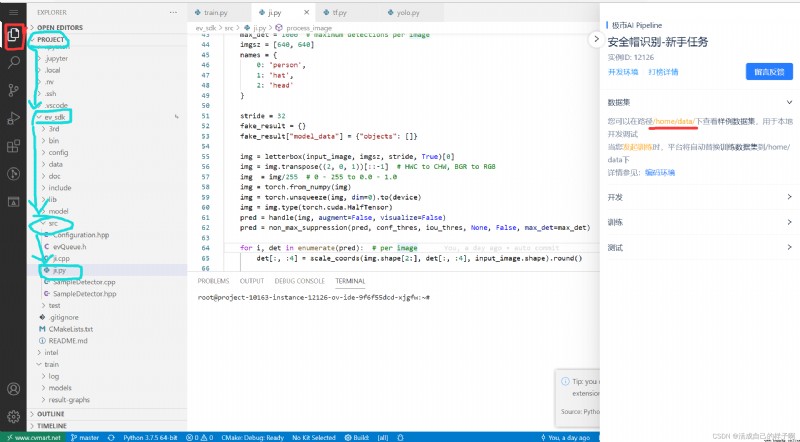
Click the one with the red circle on the left , That's the file tree list , The blue one is to create a ji.py file , The red line on the right is where the data set is stored ( We can only see sample datasets , Not all datasets are visible ).
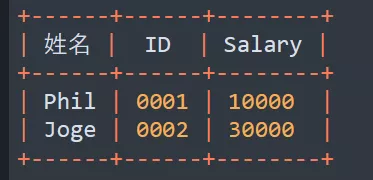
Before writing code , Let me first show you what our dataset looks like ~~~
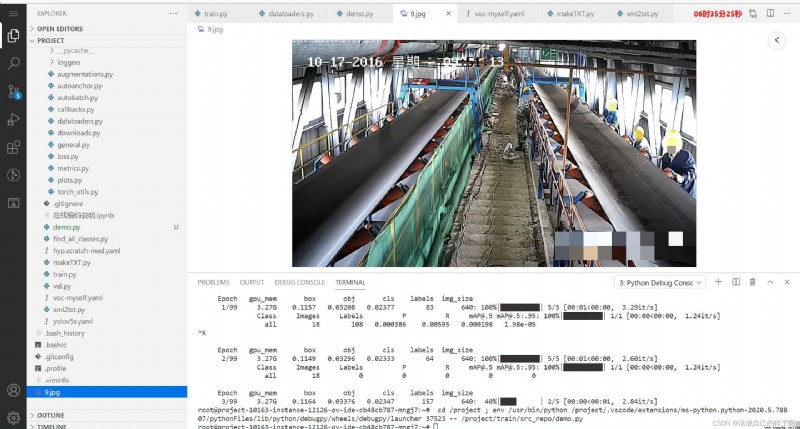
( All indicators are 0 Because Too few data sets + Learning rate is too high ~~~~)
notes : Through what was written before linux Orders can get him out ~~~
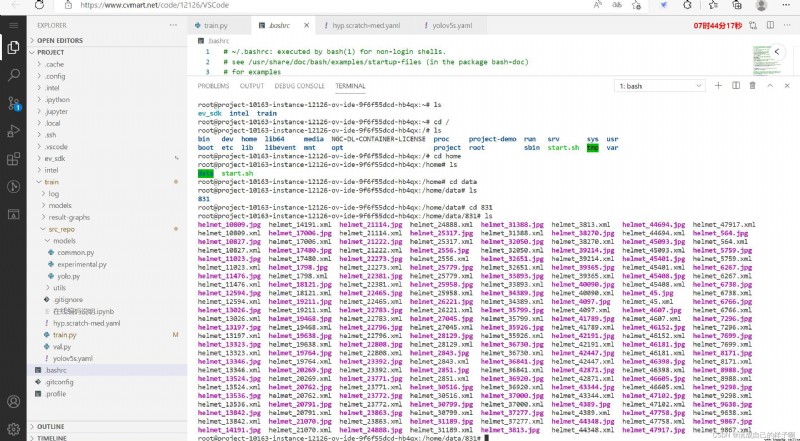
It can be seen that the data sets of polar markets are all labeled VOC Format .
next step , We move our yolov5 Code , At present, there are two ways ( There may be more , I haven't found out yet !!!)
1. Copy the code you have written ——CV Chant ~( This method is stupid , But you can change your model 、 Upload the code )
2. Open the terminal :(Ctrl + J)
cd /project/train/src_repo
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installThis step is the same as we usually write code .
Attach a I use yolov5 Write about the project , There will be no more details here !! I'm sorry ! I'm sorry ! Please refer to for specific usage :
(132 Bar message ) 【python object detection 】 Road damage detection based on deep learning |yolov5|VOC_ Live your own blog -CSDN Blog _ Pavement damage data set https://blog.csdn.net/m0_61139217/article/details/124182727?spm=1001.2014.3001.5501
debugging :F5 【 Whether it's training or testing , You have to debug locally first , There is also a local one 15G Of the graphics card , It can be used for debugging 】
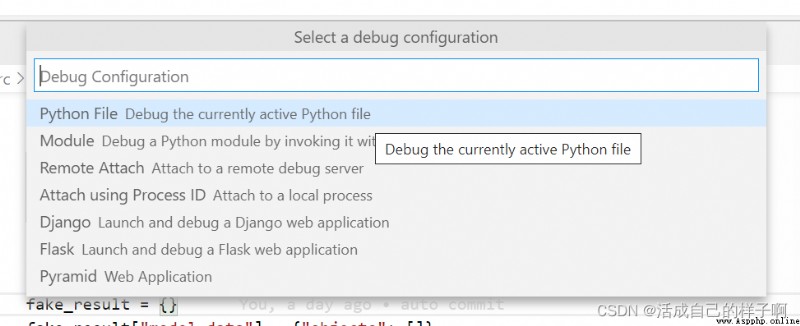
Here I am the first one to click .
To configure 、 Transform data sets , In order to put into our model training , We need to take VOC Turn into YOLO Data set in format , As shown in the figure, my data set storage path tree :( Do it with me yolov5 It's basically the same )
Here are the changed 2 A code for making data sets :( Pay attention to the position !!!)( We must pay attention to the relative path here !!!)
/project/train/src_repo/makeTXT.py
""" Generate Main Inside 4 individual txt file , Corresponding to each picture name """
import os
import random
def makeTXT():
traintest_percent = 0.9 # Scale of test set (1-traintest_percent)
train_percent = 0.8 # The ratio of training set to test set ( The proportion of training sets )
base_path = '/home/data' # xml
base_path = os.path.join(base_path, os.listdir(base_path)[0])
txtsavepath = 'train/src_repo/datasets/VOC/ImageSets/Main' # Training set 、 Verification set 、 Path to the test set
total_xml = []
for each_path in os.listdir(base_path):
xmlfilepath = each_path.endswith('.xml')
if xmlfilepath:
total_xml.append(each_path)
num = len(total_xml)
list = range(num) # 【0, num - 1】
tv = int(num * traintest_percent) # Number of validation sets and training sets
tr = int(tv * train_percent) # Number of training sets
# sample(list, k) Returns a length of k New list , The new list stores list Produced by k A random unique element
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
# [:-4] Cut it off 4 position (.xml)
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()/project/train/src_repo/xml2txt.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# sets What's set up is
sets = ['train', 'val', 'test']
# Category
classes = ['hat', 'person', 'head'] # Find category ( Just write your own category here )
# convert to yolo Dimension of format 【 Category , x Represents the scale of the abscissa of the dimension center in the image ,y Represents the scale of the ordinate of the dimension center in the image ,w Indicates the proportion of dimension box width ,h Indicates the proportion of dimension box height 】
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('/home/data/831/%s.xml' % image_id, encoding='utf8')
out_file = open('train/src_repo/datasets/VOC/labels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# b yes 2 Coordinates 4 It's worth
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
# 【 Category , x Represents the scale of the abscissa of the dimension center in the image ,y Represents the scale of the ordinate of the dimension center in the image ,w Indicates the proportion of dimension box width ,h Indicates the proportion of dimension box height 】
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def runs():
wd = r'train/src_repo/datasets/VOC'
# sets:train、val、test
for image_set in sets:
# establish labels
if not os.path.exists(wd + '/labels/'):
os.makedirs(wd + '/labels/')
image_ids = open('train/src_repo/datasets/VOC/ImageSets/Main/%s.txt' % image_set).read().strip().split()
list_file = open('train/src_repo/datasets/VOC/%s.txt' % image_set, 'w')
# Operate on each sheet
for image_id in image_ids:
list_file.write('/home/data/831/%s.jpg\n' % image_id) # Write the path of each picture
convert_annotation(image_id)
list_file.close()/project/train/src_repo/train.py ( This is the original train.py On the basis of !!! direct CV that will do )
modify :
---1--- The default values of the command line parameters are set directly ( The set file path is also the path to be placed , such as hyp、data、model Of yaml file )
---2--- The second is to add the above two data set creation functions to train.py Inside the , So there's no need to write .sh file To start the command , Yes linux The novice is very friendly !
---3---project Save path changed to :/project/train/tensorboard ( For the convenience of Jishi open tensorboard)
---4--- Save the model as :torch.save(ckpt, r'/project/train/models/' + f'epoch{epoch}.pt')
import argparse
import math
import os
import random
import sys
import time
from copy import deepcopy
from datetime import datetime
from pathlib import Path
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import SGD, Adam, AdamW, lr_scheduler
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
import val # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.dataloaders import create_dataloader
from utils.downloads import attempt_download
from utils.general import (LOGGER, check_amp, check_dataset, check_file, check_git_status, check_img_size,
check_requirements, check_suffix, check_version, check_yaml, colorstr, get_latest_run,
increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer)
from utils.loggers import Loggers
from utils.loggers.wandb.wandb_utils import check_wandb_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve, plot_labels
from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
callbacks.run('on_pretrain_routine_start')
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
if not evolve:
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Loggers
data_dict = None
if RANK in {-1, 0}:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config
plots = not evolve and not opt.noplots # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
amp = check_amp(model) # check AMP
# Freeze
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz, amp)
loggers.on_params_update({"batch_size": batch_size})
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g[2].append(v.bias)
if isinstance(v, bn): # weight (no decay)
g[1].append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g[0].append(v.weight)
if opt.optimizer == 'Adam':
optimizer = Adam(g[2], lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
elif opt.optimizer == 'AdamW':
optimizer = AdamW(g[2], lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g[2], lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': g[0], 'weight_decay': hyp['weight_decay']}) # add g0 with weight_decay
optimizer.add_param_group({'params': g[1]}) # add g1 (BatchNorm2d weights)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g[1])} weight (no decay), {len(g[0])} weight, {len(g[2])} bias")
del g
# Scheduler
if opt.cos_lr:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
else:
lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in {-1, 0} else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csd
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# Trainloader
train_loader, dataset = create_dataloader(train_path,
imgsz,
batch_size // WORLD_SIZE,
gs,
single_cls,
hyp=hyp,
augment=True,
cache=None if opt.cache == 'val' else opt.cache,
rect=opt.rect,
rank=LOCAL_RANK,
workers=workers,
image_weights=opt.image_weights,
quad=opt.quad,
prefix=colorstr('train: '),
shuffle=True)
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
nb = len(train_loader) # number of batches
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# Process 0
if RANK in {-1, 0}:
val_loader = create_dataloader(val_path,
imgsz,
batch_size // WORLD_SIZE * 2,
gs,
single_cls,
hyp=hyp,
cache=None if noval else opt.cache,
rect=True,
rank=-1,
workers=workers * 2,
pad=0.5,
prefix=colorstr('val: '))[0]
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end')
# DDP mode
if cuda and RANK != -1:
if check_version(torch.__version__, '1.11.0'):
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
else:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model attributes
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, [email protected], [email protected], val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = torch.cuda.amp.GradScaler(enabled=amp)
stopper = EarlyStopping(patience=opt.patience)
compute_loss = ComputeLoss(model) # init loss class
callbacks.run('on_train_start')
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
f"Logging results to {colorstr('bold', save_dir)}\n"
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
callbacks.run('on_train_epoch_start')
model.train()
# Update image weights (optional, single-GPU only)
if opt.image_weights:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
if RANK in {-1, 0}:
pbar = tqdm(pbar, total=nb, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
callbacks.run('on_train_batch_start')
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
with torch.cuda.amp.autocast(amp):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in {-1, 0}:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) %
(f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots)
if callbacks.stop_training:
return
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in {-1, 0}:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
if not noval or final_epoch: # Calculate mAP
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, [email protected], [email protected]]
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
'date': datetime.now().isoformat()}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
# torch.save(ckpt, w / f'epoch{epoch}.pt')
torch.save(ckpt, r'/project/train/models/' + f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# Stop Single-GPU
if RANK == -1 and stopper(epoch=epoch, fitness=fi):
break
# Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
# stop = stopper(epoch=epoch, fitness=fi)
# if RANK == 0:
# dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
# Stop DPP
# with torch_distributed_zero_first(RANK):
# if stop:
# break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in {-1, 0}:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = val.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=plots,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
callbacks.run('on_train_end', last, best, plots, epoch, results)
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--cfg', type=str, default='train/src_repo/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='train/src_repo/voc-myself.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='train/src_repo/hyp.myself.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=4, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default='/project/train/tensorboard', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=30, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=3, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def main(opt, callbacks=Callbacks()):
# Checks
if RANK in {-1, 0}:
print_args(vars(opt))
check_git_status()
check_requirements(exclude=['thop'])
# Resume
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
LOGGER.info(f'Resuming training from {ckpt}')
else:
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
if opt.evolve:
if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
if opt.name == 'cfg':
opt.name = Path(opt.cfg).stem # use model.yaml as name
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# DDP mode
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
assert not opt.image_weights, f'--image-weights {msg}'
assert not opt.evolve, f'--evolve {msg}'
assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
# Train
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ')
dist.destroy_process_group()
# Evolve hyperparameters (optional)
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
meta = {
'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {evolve_csv}') # download evolve.csv if exists
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation
results = train(hyp.copy(), opt, device, callbacks)
callbacks = Callbacks()
# Write mutation results
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
# Plot results
plot_evolve(evolve_csv)
LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Usage example: $ python train.py --hyp {evolve_yaml}')
def run(**kwargs):
# Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
return opt
if __name__ == "__main__":
import makeTXT
import xml2txt
makeTXT.makeTXT()
xml2txt.runs()
opt = parse_opt()
main(opt)
Quick view of other documents :
train/src_repo/hyp.myself.yaml :( It can be seen when the parameters are running p、r、map Return to zero , Reasonably change the learning rate or batchsize that will do , You can also change it to your own parameters )
# YOLOv5 by Ultralytics, GPL-3.0 license
# Hyperparameters for low-augmentation COCO training from scratch
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
train/src_repo/voc-myself.yaml :
train: datasets/VOC/train.txt # Here is / instead of \
val: datasets/VOC/val.txt # Here is / instead of \
test: datasets/VOC/test.txt # Here is / instead of \
# Classes
nc: 3 # number of classes Number of dataset categories
names: ['hat', 'person', 'head'] # class names Dataset category name , Note that it corresponds to the order of the labels `train/src_repo/yolov5s.yaml :
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 3 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
notes : There are... For helmet inspection 3 Categories , Namely :'hat', 'person', 'head'
Training models , Jishi recommends .sh Command line , But many friends don't know how to write , Simply us Directly by order Just go ( If you use the code I changed above !)
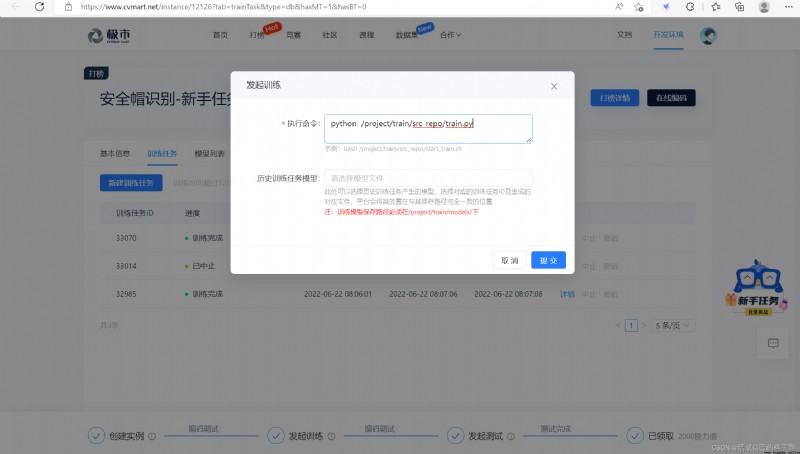
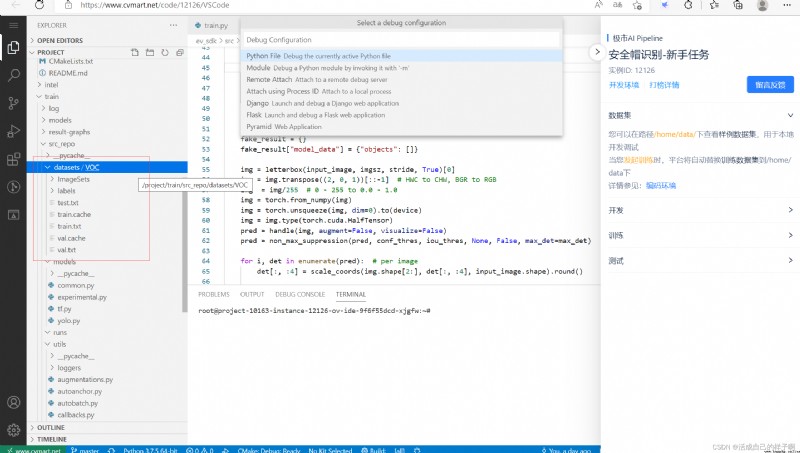
you 're right !!! The above command is the same as our normal right-click operation 【pycharm】 Is the same effect ~
The initial training log :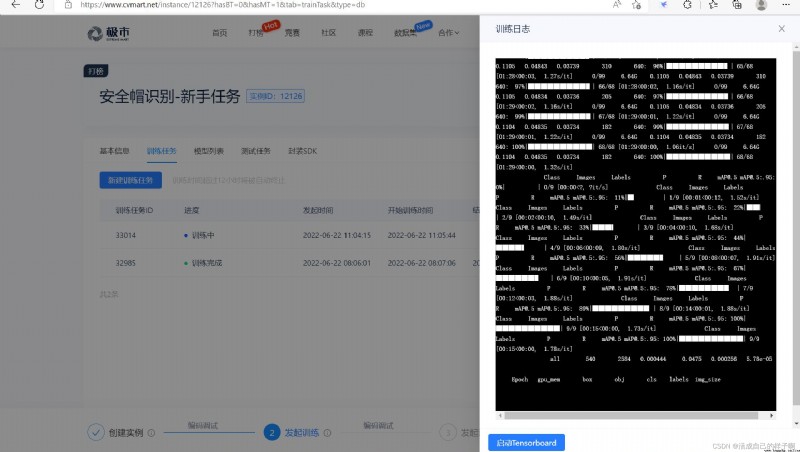
After that 40 Training log after rounds :
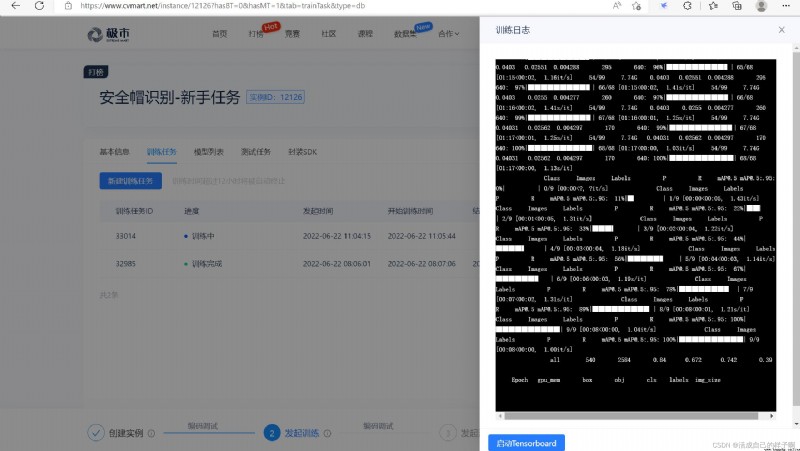
It can be seen that the indicators have significantly improved !
Of course , Because I modified yolov5 project The path to save , So you can also see tensorboard design sketch !
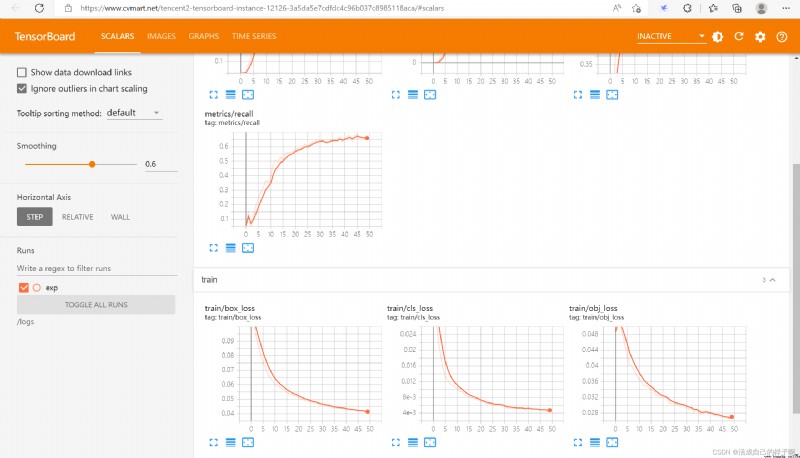
notes : You can see here that I only train 50 round . But the model has not converged yet .
This is the last step , And the most critical step , Not the hardest , But the most troublesome ...
You can see :( I have passed countless failed tests , Just successfully submitted ! Well, )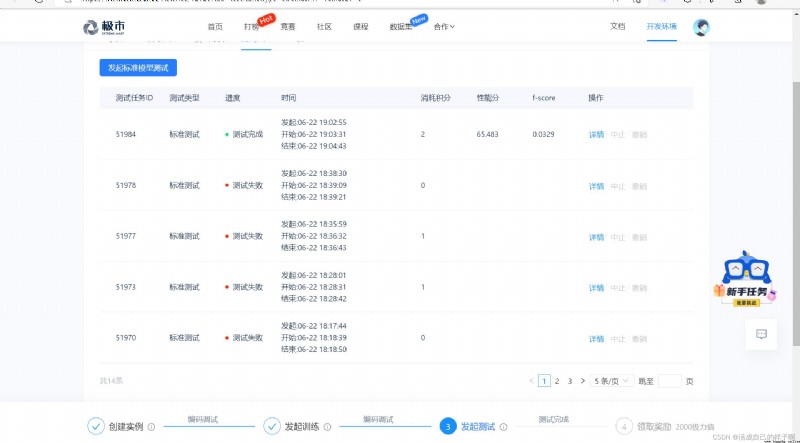
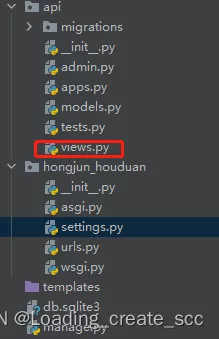
The polar test is a direct call /project/ev_sdk/src Under the ji.py file ( Don't get the name wrong ), So we need to write an interface under this path !!!
I'll just give the code :
/project/ev_sdk/src/ji.py :( Pay attention to the guide bag here !! The relative path guide package is used , Can't , Jishi has to use this position to test , I'm too lazy to move files )
notes : that model_path The variable is assigned its own weight to save the path ... Don't copy directly ...
import json
import torch
import sys
import numpy as np
import cv2
from pathlib import Path
#from ensemble_boxes import weighted_boxes_fusion
# from train.src_repo.models.experimental import attempt_load
# from train.src_repo.utils.torch_utils import select_device
# from train.src_repo.utils.general import check_img_size, non_max_suppression, scale_coords
from train.src_repo.utils.augmentations import letterbox
from train.src_repo.models.common import DetectMultiBackend
from train.src_repo.utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from train.src_repo.utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from train.src_repo.utils.plots import Annotator, colors, save_one_box
from train.src_repo.utils.torch_utils import select_device, time_sync
device = torch.device("cuda:0")
model_path = r'/project/train/models/epoch48.pt' # The model address must be consistent with the model address selected in the test phase !!!
@torch.no_grad()
def init():
weights = model_path
device = 'cuda:0' # cuda device, i.e. 0 or 0,1,2,3 or
half = True # use FP16 half-precision inference
device = select_device(device)
w = str(weights[0] if isinstance(weights, list) else weights)
# model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
model = DetectMultiBackend(w, device=device, dnn=False, data=r'/project/train/src_repo/voc-myself.yaml', fp16=True)
if half:
model.half() # to FP16
model.eval()
return model
def process_image(handle=None, input_image=None, args=None, **kwargs):
half = True # use FP16 half-precision inference
conf_thres = 0.3 # confidence threshold
iou_thres = 0.05 # NMS IOU threshold
max_det = 1000 # maximum detections per image
imgsz = [640, 640]
names = {
0: 'person',
1: 'hat',
2: 'head'
}
stride = 32
fake_result = {}
fake_result["model_data"] = {"objects": []}
img = letterbox(input_image, imgsz, stride, True)[0]
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = img/255 # 0 - 255 to 0.0 - 1.0
img = torch.from_numpy(img)
img = torch.unsqueeze(img, dim=0).to(device)
img = img.type(torch.cuda.HalfTensor)
pred = handle(img, augment=False, visualize=False)
pred = non_max_suppression(pred, conf_thres, iou_thres, None, False, max_det=max_det)
for i, det in enumerate(pred): # per image
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], input_image.shape).round()
for *xyxy, conf, cls in reversed(det):
xyxy_list = torch.tensor(xyxy).view(1, 4).view(-1).tolist()
conf_list = conf.tolist()
label = names[int(cls)]
fake_result['model_data']['objects'].append({
"xmin": int(xyxy_list[0]),
"ymin": int(xyxy_list[1]),
"xmax": int(xyxy_list[2]),
"ymax": int(xyxy_list[3]),
"confidence": conf_list,
"name": label
})
return json.dumps(fake_result, indent=4)Do you think it's over ?no way!
Because of the relative position , You need to put yolov5 All the guide packages in the code have been changed , Change to relative path guide package !!!
for example : add train.src_repo.

The documents with red circle on the left need to be changed !!!
Tips :
direct debug(F5)ji.py file , Just look at his error report , Know not to report the error of the package , It means that all the changes have been completed .
【 If there is a great God here who has a good way, you can also share it !!!】
emmm, Finally, don't forget to get the reward !