This time it is for crawlers that need web page analysis , After analysis, you will often get the source address of each video you need , But if a video lesson has many lessons, you must search the source address of each video one by one , This is a waste of time and does not meet our requirements for crawler automation , So we need to analyze the whole page and try to uproot it .
What we are going to climb this time is mooc Dr. monkey circuit series in .
Open up our mooc Find Dr. monkey's circuit series courses and click on the first lesson ,F12 Post refresh . My habit of analyzing packets is to sort packets from large to small
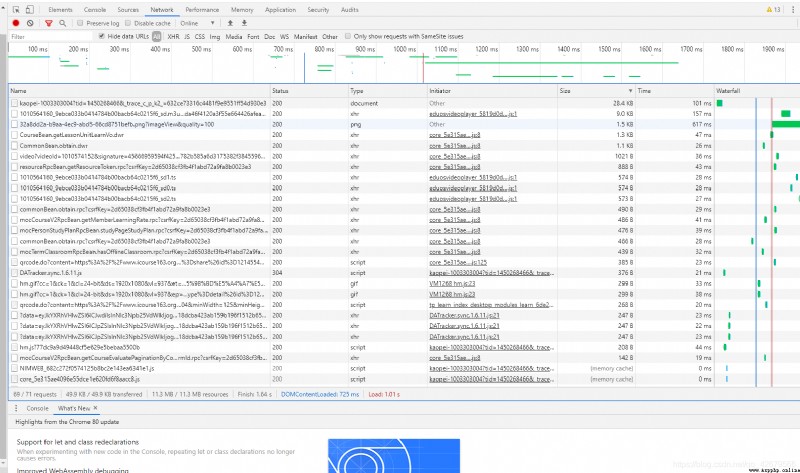
We look at it from big to small , When we see the second one, if we click its link, we will automatically download one for you .m3u8 file
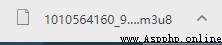
We know this through Baidu m3u8 Files are for storing videos , The video will be cut into ten seconds .ts Video format .ts Format is a video format invented in Japan that can be parsed by segments. With this format, our video can be transmitted in real time , To change the resolution and not start playing from scratch . After understanding, we use Notepad ( I used it here notepad++) Open the file .
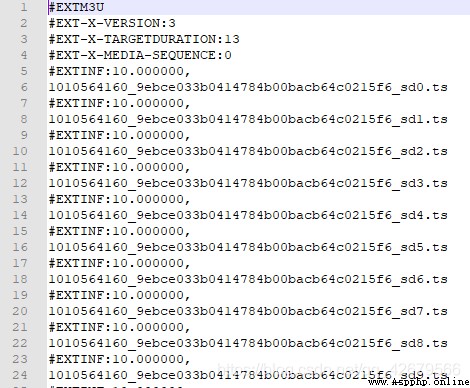
Sure enough, there are links in this one , But it seems incomplete , So I took a look .m3u8 Link to https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8?ak=7909bff134372bffca53cdc2c17adc27a4c38c6336120510aea1ae1790819de83648959c0963d7b517df373715a0a62630c89a42b26e6c7c455cd73d745bce253059f726dc7bb86b92adbc3d5b34b13258d0932fcf70014da46f4120a3f55e664426afeac364f76a817da3b2623cd41e
This link is very long, but a closer look shows .m3u8 And then there's the parameters , Use https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8 This link can also be downloaded to .m3u8 The file of . It is not difficult to find out by careful comparison 1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8 This is very similar to our video link , It's not hard to find the video link. You need to bring it with you https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/ To round up the links , So I can easily write the crawling code for this video
import requests
url = "https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/"
m3u8 = '1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8'
r = requests.get(url+m3u8)
content = r.text
content = content.split('\n')
ts = []
num = 4
f = open(" Dr. monkey circuit lesson 1 .ts", 'wb')
while True:
if content[num][:7] == '#EXTINF':
res = requests.get(url+content[num+1])
f.write(res.content)
elif content[num] == '#EXT-X-ENDLIST':
break
num = num+2
f.close()
print('ok')
Let's go back to the foreword , If you simply crawl through a lesson, you can , But for a series of crawls, you need to manually find each link , This is particularly troublesome. Is there any way ? Of course there are , We want to find the rules between each link , The best way is to find the source of the link . So in F12 Search inside 1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8
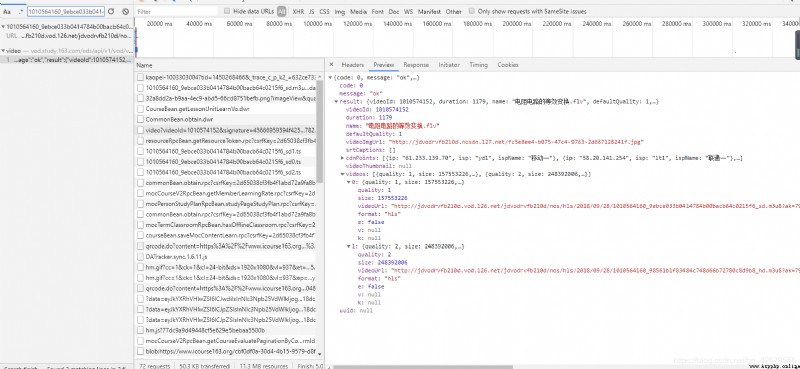
I found it https://vod.study.163.com/eds/api/v1/vod/video?videoId=1010574152&signature=45666959594f425950516d3679506e65537539334145562f665130584a4c31362b35572b633632317a5848514d7032314f756333355269334b517a4b733351446d5731704e3341334f4e2f632b67654c70557073713033564947356154724e536b55437131685a486343364b4a46646f6339766e7432544c614573414a62572f682f6d4762762f517873595a754c4b2b304e6b37536d3739344e782b585a6d3175382f38455967574e34633d&clientType=1, After it returns json There are also two links in , One of them is our link , There is another one with better picture quality
Um. , Now we can get , But we still haven't found the source of this link , Through analysis, it is not difficult to see that the link has three parameters. One is videoId, One is signature, The other one is clientType, Then let's continue our search 45666959594f425950516d3679506e65537539334145562f665130584a4c31362b35572b633632317a5848514d7032314f756333355269334b517a4b733351446d5731704e3341334f4e2f632b67654c70557073713033564947356154724e536b55437131685a486343364b4a46646f6339766e7432544c614573414a62572f682f6d4762762f517873595a754c4b2b304e6b37536d3739344e782b585a6d3175382f38455967574e34633d To trace back to its upper layer
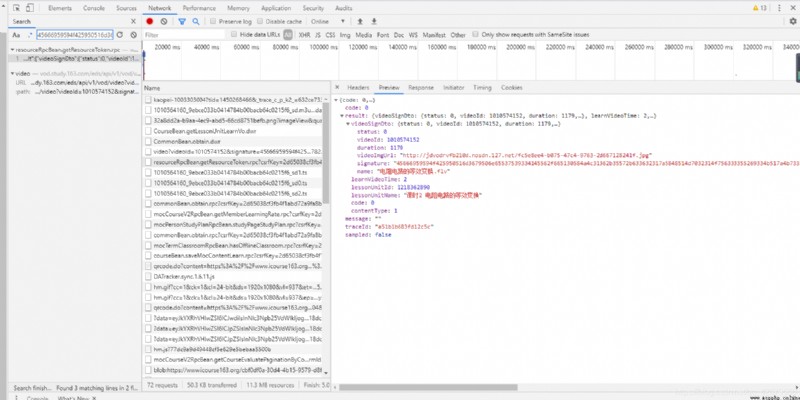
Tracing the source, we found https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=2d65038cf3fb4f1abd72a9fa8b0023e3 This post link , We saw it post Of data
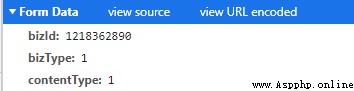
adopt requests In the database post We can imitate the browser to the server post.( You need to add cookies Otherwise, a cross region request will be returned ) So here comes the question 1218362890 Where did we come from ?

Through the search, we found https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLastLearnedMocTermDto.dwr It returns a seemingly js Code for , And found other videos bizId So now we can uproot it through the program , We crawled it all down through multithreading
import requests
import re
import threading
cookie = {
'EDUWEBDEVICE':'4e11983bda394e54ad6138086e05561b;'
# Here, in order to protect my privacy, I haven't finished writing my own cookies, When writing, you need to change the equal sign to a colon according to the above form , hold
# Values are represented by key value pairs, and different values are separated by semicolons
}
def GitID():
heards = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'content-type':'text/plain'
}
data = 'callCount=1\nscriptSessionId=${scriptSessionId}190\nhttpSessionId=2d65038cf3fb4f1abd72a9fa8b0023e3\nc0-scriptName=CourseBean\nc0-methodName=getLastLearnedMocTermDto\nc0-id=0\nc0-param0=number:1450268466\nbatchId=1582376246318'
r = requests.post('https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLastLearnedMocTermDto.dwr',data=data,headers=heards,cookies=cookie)
content = re.findall('id=1218\d*', r.text)
for i in range(len(content)):
content[i] = content[i][3:]
return content
def GetSignature(num):
heards = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'content-type':'application/x-www-form-urlencoded'
}
data = 'bizId=%s&bizType=1&contentType=1'%(num)
r = requests.post('https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=2d65038cf3fb4f1abd72a9fa8b0023e3',data=data,headers=heards,cookies=cookie)
return r.json()['result']['videoSignDto']['videoId'],r.json()['result']['videoSignDto']['signature']
def GetUrl(signature):
r = requests.get('https://vod.study.163.com/eds/api/v1/vod/video?videoId=%s&signature=%s&clientType=1'%(signature[0],signature[1]))
return r.json()['result']['videos'][0]['videoUrl']
def GetMp4(Url,name):
r = requests.get(Url)
content = r.text.split('\n')
num = 4
f = open(' Dr. monkey circuit %d.mp4'%(int(name)-89),'wb')
while True:
if content[num][:7] == '#EXTINF':
res = requests.get(Url[:66]+content[num+1])
f.write(res.content)
elif content[num] == '#EXT-X-ENDLIST':
break
num = num+2
f.close()
def mutilprocess():
Id = GitID()
threads = []
url = []
for i in range(len(Id)):
try:
url.append(GetUrl(GetSignature(Id[i])))
threads.append(threading.Thread(target=GetMp4,args=(url[i],Id[i][-2:])))
except:
pass
for i in range(len(threads)):
threads[i].start()
for i in range(len(threads)):
threads[i].join()
print('" Dr. monkey circuit %d.mp4" Crawling is complete '%(int(Id[i][-2:])-89))
if __name__ == "__main__":
mutilprocess()
print(' Climb to success !')
Here to cookies Let's talk about it [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-4W8rd8qU-1582558032317)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20200224232144234.png)]
if name == “main”:
mutilprocess()
print(‘ Climb to success !’)
Here to cookies Let's talk about it
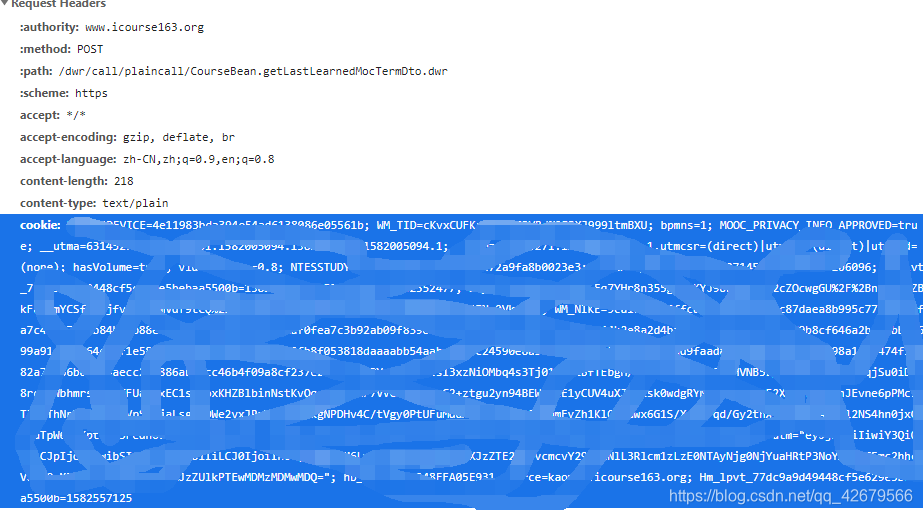
Source cookies The information in F12 Of headers Inside Requests Headers in , But I have to rewrite it into a dictionary .